literary alpaca2
1.0.0

Du vocabulaire au réglage fin, c'est tout ce dont vous avez besoin
Ce référentiel montrera comment construire votre propre vocabulaire à partir du vocabulaire et utiliser le modèle de quai pré-formation et affinage les exemples de code dans le référentiel est principalement formé en fonction de la version étreinte du visage de LLAMA2, fournissant des exemples de formation pour GPU et TPU. En raison de l'énergie limitée de l'auteur, il y a des bogues dans le script TPU, qui est à titre de référence uniquement.
| taper | décrire |
|---|---|
| Romans en ligne | Données de texte longs de haute qualité |
| Math23k | Problèmes de mathématiques chinoises |
| LCCC | Ensemble de dialogue open source chinois |
Comment utiliser un ensemble de données LCCC:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
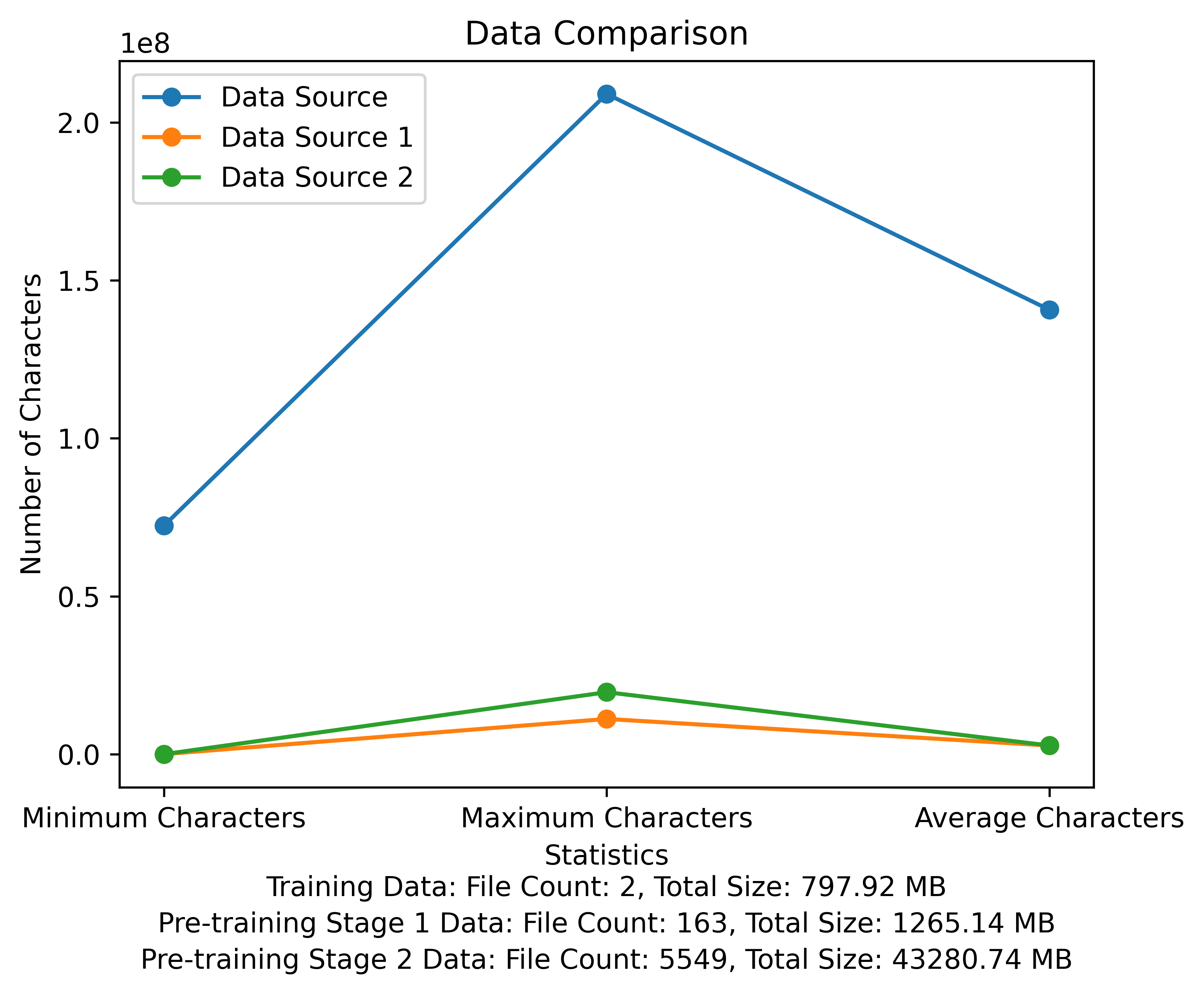
La liste de vocabulaire et le diagramme de comparaison des données de l'étape pré-formation. La figure montre le nombre de fichiers et les tailles de fichiers totales de chaque source de données et compare les caractères minimum et maximum et le nombre moyen de caractères dans chaque fichier:
META LIEN DE TÉLÉCHARGE OFFICIEL: https://huggingface.co/meta-llama
Le modèle chinois pré-formé, les paramètres LORA et les modèles de chat ont tous été téléchargés sur le visage étreint. Actuellement, il n'y a que des modèles 13B.
| catégorie | ? Nom du modèle | Modèle de base | Adresse de téléchargement |
|---|---|---|---|
| Pré-formation | taotie1 / littéraire-alpaca2-13b | méta-llama / lama-2-13b-hf | Téléchargement du modèle |
| Lora | taotie1 / littéraire-alpaca2-13b-lora | taotie1 / littéraire-alpaca2-13b | Téléchargement du modèle |
| catégorie | ? Nom du modèle | Adresse de téléchargement |
|---|---|---|
| Chat | Taotie1 / littéraire-alpaca2-13b | Téléchargement du modèle |
Selon les dépendances de l'environnement d'installation de requirement.txt, veuillez sélectionner la version de l'installation de la torche selon votre appareil.
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) Prénom et nettoyez vos données de formation [Facultatif]
Choisissez d'exécuter le code de nettoyage aléatoire ou de tout nettoyer, et vous pouvez personnaliser vos règles dans ill_ocr_regex.txt.
Exécutez full_sample_extraction.py pour fusionner les données dans un fichier.
Reportez-vous à Train-Chinese-Tokenizer.Ipynb pour la formation du vocabulaire, et vous pouvez modifier le code en fonction de vos propres besoins. Une fois la formation terminée, placez votre liste de vocabulaire dans le répertoire My-Tokenzer. Fusionner avec le tokenizer du LLAMA2 original de la manière suivante
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
Exécuter text.py pour tester l'effet de vocabulaire
Ce code de formation de référentiel utilise Deeppeed pour accélérer
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
- Utilisation du script Pretrain 2 Pretrain-peft2.sh générera des paramètres LORA. Vous pouvez exécuter le script Merge_lora_low_mem.py modifié à partir de chinois-llama-alpaca-2 pour fusionner
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
Affichage des ajustements personnalisés à des ensembles de données simples:

Utilisez le script de conversion dans le répertoire SFT pour convertir l'ensemble de données en format de formation requis. Les ensembles de données originaux utilisés dans ce projet sont tous au format JSON. Veuillez modifier le script de conversion au besoin:
Le format de fichier JSON généré est:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
Par exemple:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
Le fichier CSV converti contient une colonne de "texte", chaque comportement est un exemple de formation, et chaque exemple de formation est organisé dans l'entrée du modèle dans le format suivant:
"<s>Human: "+...+"n</s><s>Assistant: "+...
Par exemple:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
Exécutez sft / sft-peft.sh dans le répertoire SFT pour commencer la formation. Pour le code d'implémentation spécifique, voir SFT / SFT-PEFT.py


