literary alpaca2
1.0.0

어휘에서 미세 조정에 이르기까지 이것이 필요한 모든 것입니다
이 저장소는 어휘에서 자신의 어휘를 구축하는 방법을 보여주고 도크 모델 사전 훈련 및 저장소의 코드 예제를 미세 조정하는 방법을 보여줍니다. 저자의 제한된 에너지로 인해 TPU 스크립트에는 버그가 있습니다.
| 유형 | 설명하다 |
|---|---|
| 온라인 소설 | 고품질 긴 텍스트 데이터 |
| 수학 | 중국 수학 문제 |
| LCCC | 중국 오픈 소스 대화 세트 |
LCCC 데이터 세트 사용 방법 :
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
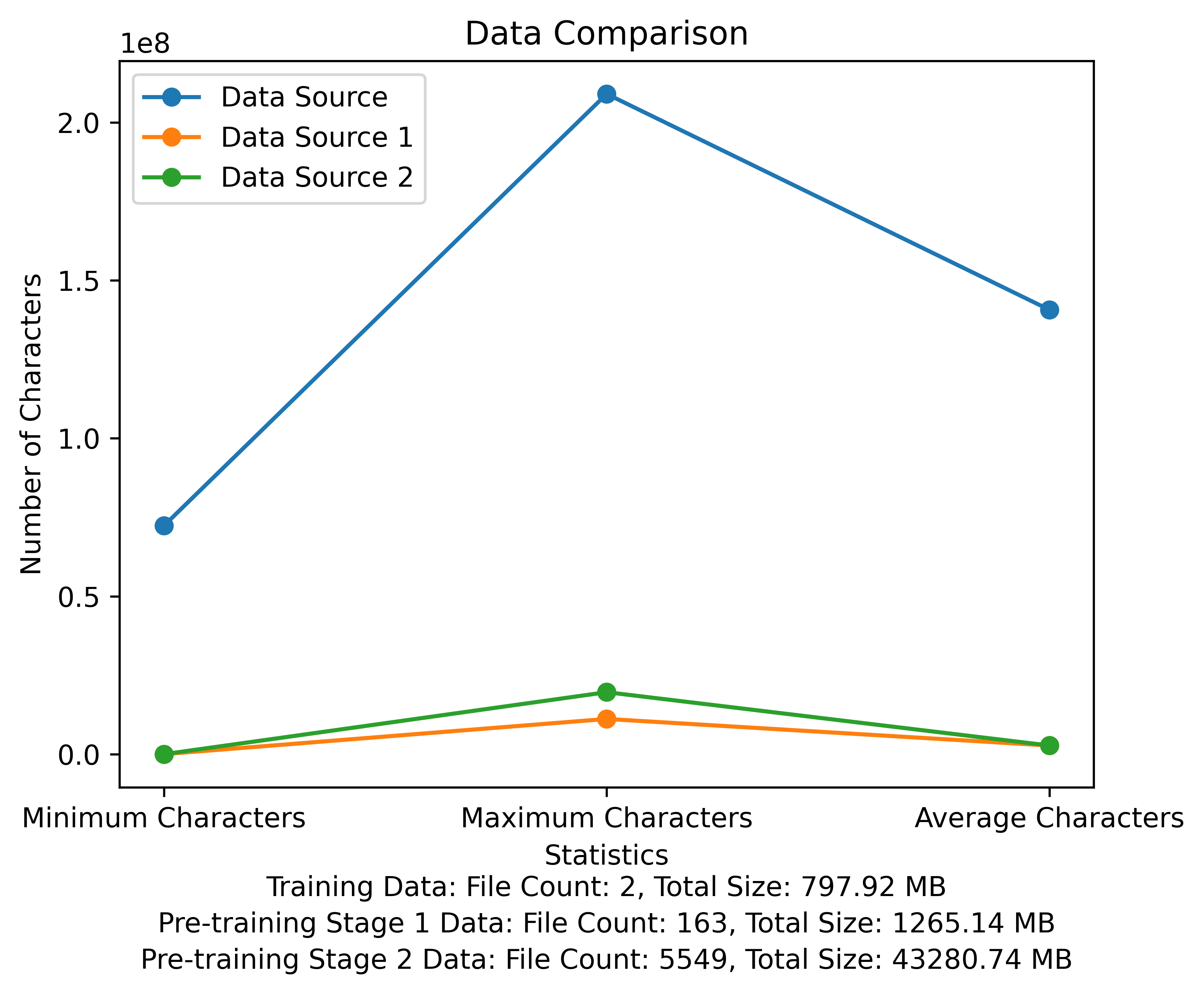
사전 훈련 단계의 어휘 목록 및 데이터 비교 다이어그램. 그림은 각 데이터 소스의 파일 수와 총 파일 크기를 보여 주며 각 파일의 최소 및 최대 문자 및 평균 문자 수를 비교합니다.
메타 공식 다운로드 링크 : https://huggingface.co/meta-llama
중국 미리 훈련 된 모델, LORA 매개 변수 및 채팅 모델이 모두 포옹 얼굴에 업로드되었습니다. 현재 13B 모델 만 있습니다.
| 범주 | ? 모델 이름 | 기본 모델 | 주소를 다운로드하십시오 |
|---|---|---|---|
| 사전 훈련 | taotie1/문학-알파카 2-13b | 메타 롤라/라마 -2-13B-HF | 모델 다운로드 |
| 로라 | taotie1/문학-알파카 2-13b-lora | taotie1/문학-알파카 2-13b | 모델 다운로드 |
| 범주 | ? 모델 이름 | 주소를 다운로드하십시오 |
|---|---|---|
| 채팅 | taotie1/문학-알파카 2-13B-chat | 모델 다운로드 |
요구 사항에 따라 TXT 설치 환경 종속성에 따라 장치에 따라 토치 설치 버전을 선택하십시오.
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) 이름 이름과 훈련 데이터를 청소 [선택 사항]
랜덤 클리닝 코드를 실행하거나 모두 정리하도록 선택하면 ill_ocr_regex.txt에서 규칙을 사용자 정의 할 수 있습니다.
full_sample_extraction.py를 실행하여 데이터를 파일로 병합하십시오.
어휘 훈련은 Train-Chinese-Tokenizer.ipynb를 참조하고 자신의 요구에 따라 코드를 수정할 수 있습니다. 교육이 완료된 후 어휘 목록을 My-Tokenizer 디렉토리에 넣으십시오. 다음 방법으로 원래 llama2의 토큰 화제와 병합
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
텍스트를 실행하여 어휘 효과를 테스트하십시오
이 저장소 교육 코드는 DeepSpeed를 사용하여 속도를 높입니다
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
-Pretrain Script 2 Pretrain-Peft2.sh를 사용하면 LORA 매개 변수가 생성됩니다. MERGE_LORA_LOW_MEM.PY 스크립트를 중국어-알라마 -Alpaca-2에서 수정하여 병합 할 수 있습니다.
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
간단한 데이터 세트에 개인화 된 조정 표시 :

SFT 디렉토리의 변환 스크립트를 사용하여 데이터 세트를 필요한 교육 형식으로 변환하십시오. 이 프로젝트에 사용 된 원래 데이터 세트는 모두 JSON 형식입니다. 필요에 따라 변환 스크립트를 수정하십시오.
생성 된 JSON 파일 형식은 다음과 같습니다.
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
예를 들어:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
변환 된 CSV 파일에는 "텍스트"열이 포함되어 있으며 각 동작은 훈련 예이며, 각 교육 예제는 다음 형식으로 모델의 입력으로 구성됩니다.
"<s>Human: "+...+"n</s><s>Assistant: "+...
예를 들어:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
SFT 디렉토리에서 SFT/SFT-PEFT.SH를 실행하여 교육을 시작하십시오. 특정 구현 코드는 SFT/SFT-PEFT.py를 참조하십시오


