literary alpaca2
1.0.0

Do vocabulário ao ajuste fino, isso é tudo que você precisa
Este repositório mostrará como construir seu próprio vocabulário a partir do vocabulário e usará o modelo de dock pré-treinamento e ajustando os exemplos de código no repositório são treinados principalmente com base na versão de face abraça do LLAMA2, fornecendo exemplos de treinamento para GPU e TPU. Devido à energia limitada do autor, existem bugs no script da TPU, que é apenas para referência.
| tipo | descrever |
|---|---|
| Romances online | Dados de texto longo de alta qualidade |
| Math23k | Problemas de matemática chinesa |
| LCCC | Conjunto de diálogo de código aberto chinês |
Como usar o conjunto de dados LCCC:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
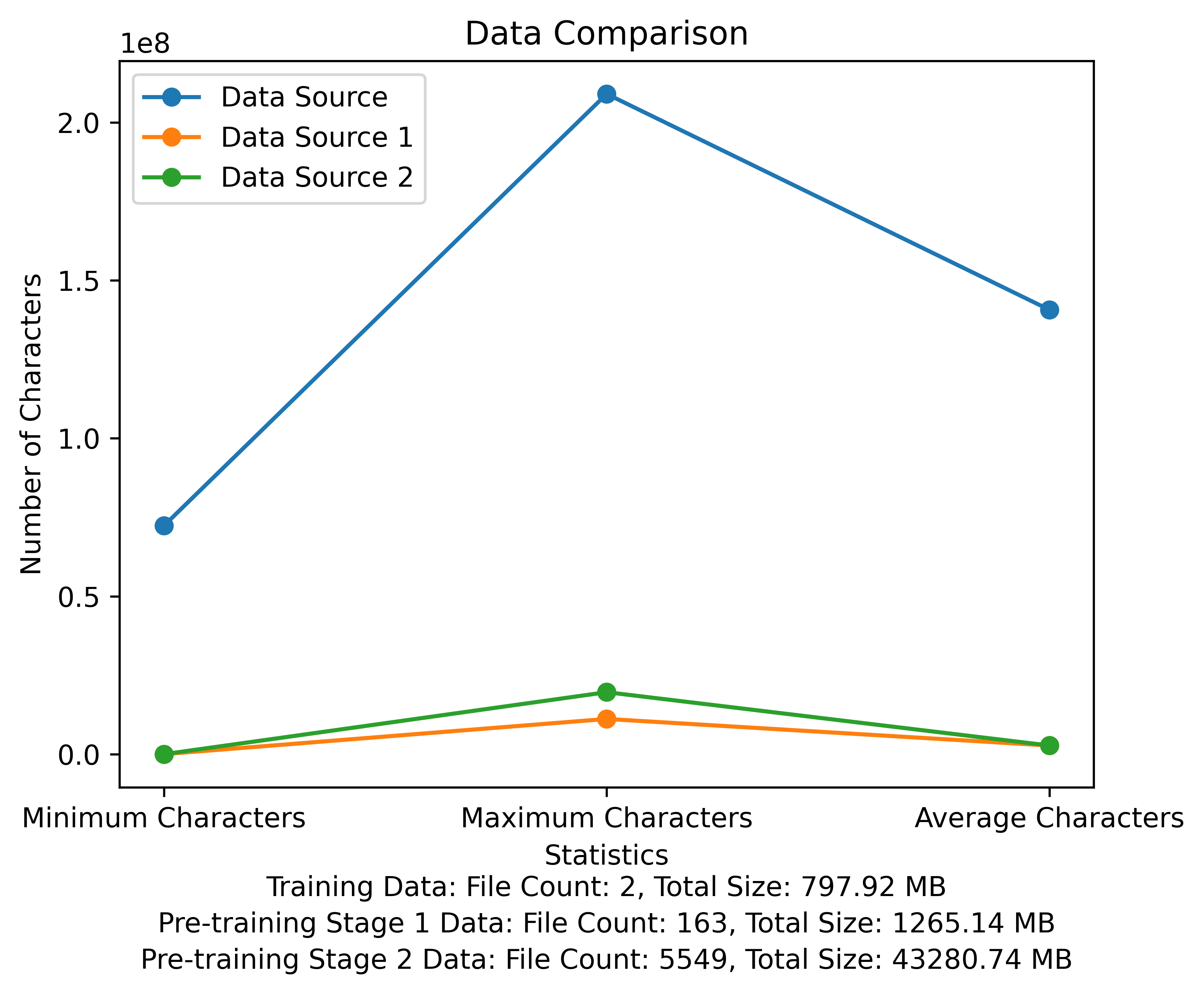
A lista de vocabulário e o diagrama de comparação de dados do estágio de pré-treinamento. A figura mostra o número de arquivos e os tamanhos totais de arquivos de cada fonte de dados e compara os caracteres mínimo e máximo e o número médio de caracteres em cada arquivo:
Link para download oficial da meta: https://huggingface.co/meta-llama
O modelo pré-treinado chinês, os parâmetros Lora e os modelos de bate-papo foram enviados para abraçar o rosto. Atualmente, existem apenas 13B modelos.
| categoria | ? Nome do modelo | Modelo base | Endereço para download |
|---|---|---|---|
| Pré-treinamento | Taotie1/literário-alpaca2-13b | meta-llama/llama-2-13b-hf | Download do modelo |
| Lora | Taotie1/literário-alpaca2-13b-lora | Taotie1/literário-alpaca2-13b | Download do modelo |
| categoria | ? Nome do modelo | Endereço para download |
|---|---|---|
| Bater papo | Taotie1/literário-alpaca2-13b-chat | Download do modelo |
De acordo com requisitos.
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) Primeiro nome e limpe seus dados de treinamento [opcional]
Escolha executar o código de limpeza aleatório ou limpar tudo, e você pode personalizar suas regras em ill_ocr_regex.txt.
Execute full_sample_extraction.py para mesclar os dados em um arquivo.
Consulte o trem-chinese-tokenizer.ipynb para obter o treinamento de vocabulário e você pode modificar o código de acordo com suas próprias necessidades. Após a conclusão do treinamento, coloque sua lista de vocabulário no diretório do My-Tokenizer. Fundir -se com o tokenizer da llama2 original da seguinte maneira
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
Execute text.py para testar o efeito do vocabulário
Este código de treinamento do repositório usa o DeepSpeed para acelerar
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
- Usando o script pré-rAin 2 pré-train-PEFT2.sh gerará parâmetros LORA. Você pode executar o script Merge_lora_low_mem.py modificado de chinês-llama-alpaca-2 para mesclar
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
Exibição de ajustes personalizados para conjuntos de dados simples:

Use o script de conversão no diretório SFT para converter o conjunto de dados no formato de treinamento necessário. Os conjuntos de dados originais usados neste projeto estão todos no formato JSON. Modifique o script de conversão conforme necessário:
O formato de arquivo JSON gerado é:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
Por exemplo:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
O arquivo CSV convertido contém uma coluna de "texto", cada comportamento é um exemplo de treinamento e cada exemplo de treinamento é organizado na entrada do modelo no seguinte formato:
"<s>Human: "+...+"n</s><s>Assistant: "+...
Por exemplo:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
Execute SFT/SFT-PEFT.SH no diretório SFT para iniciar o treinamento. Para o código de implementação específico, consulte SFT/SFT-PEFT.PY


