literary alpaca2
1.0.0

Dari kosakata hingga penyesuaian, ini adalah semua yang Anda butuhkan
Repositori ini akan menunjukkan cara membangun kosakata Anda sendiri dari kosakata dan menggunakan model dock pra-pelatihan dan menyempurnakan contoh kode dalam repositori terutama dilatih berdasarkan versi pemeluk wajah LLAMA2, memberikan contoh pelatihan untuk GPU dan TPU. Karena terbatasnya energi penulis, ada bug dalam skrip TPU, yang hanya untuk referensi.
| jenis | menggambarkan |
|---|---|
| Novel online | Data teks panjang berkualitas tinggi |
| Math23k | Masalah matematika Cina |
| LCCC | Set Dialog Sumber Terbuka Cina |
Cara menggunakan dataset LCCC:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
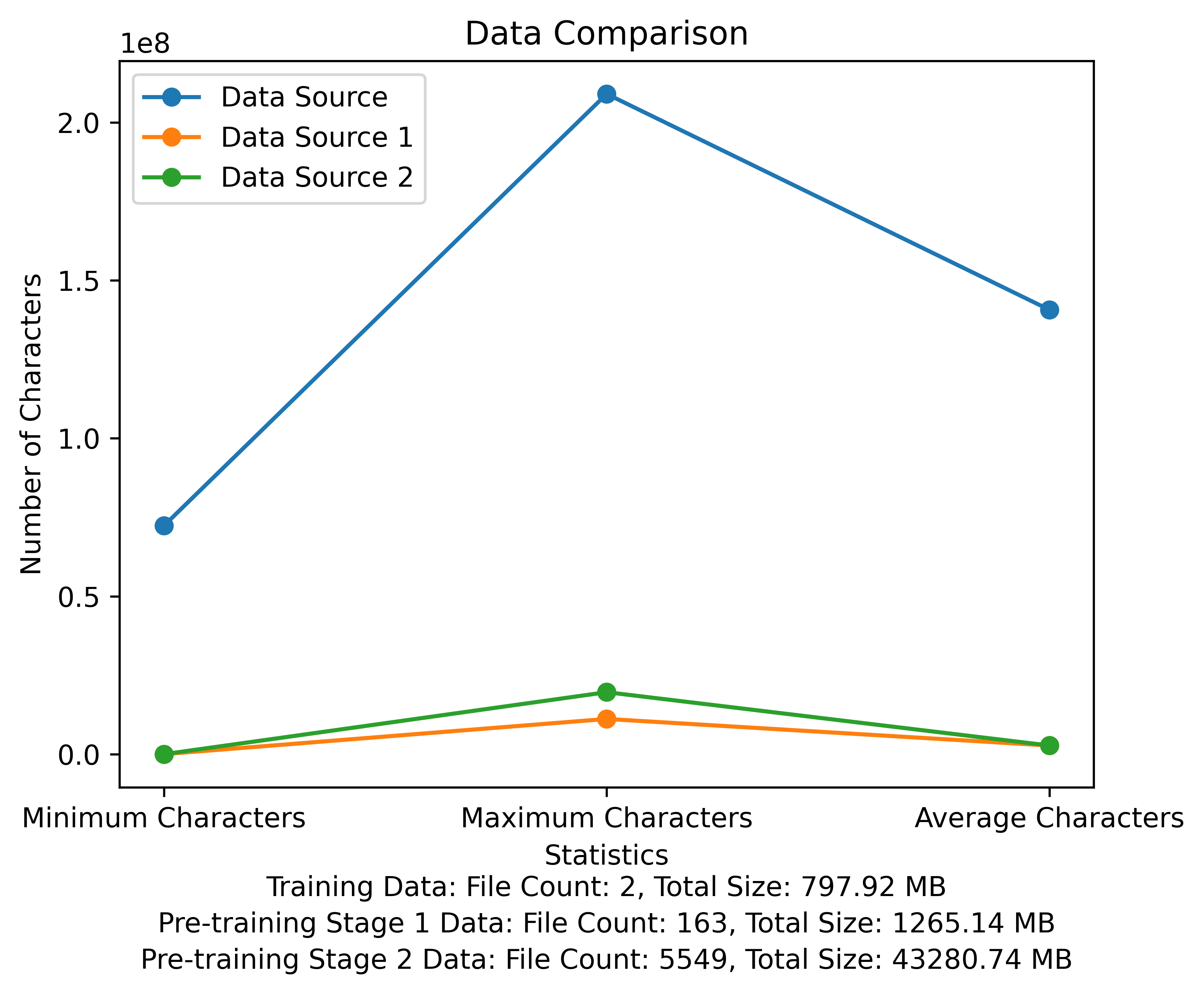
Daftar kosa kata dan diagram perbandingan data dari tahap pra-pelatihan. Gambar ini menunjukkan jumlah file dan total ukuran file dari setiap sumber data, dan membandingkan karakter minimum dan maksimum dan jumlah rata -rata karakter di setiap file:
Meta Link Unduh Resmi: https://huggingface.co/meta-llama
Model pra-terlatih Cina, parameter LORA, dan model obrolan semuanya telah diunggah ke wajah memeluk. Saat ini, hanya ada model 13B.
| kategori | ? Nama model | Model dasar | Alamat unduhan |
|---|---|---|---|
| Pra-pelatihan | taotie1/sastra-alpaca2-13b | Meta-llama/llama-2-13b-hf | Download model |
| Lora | taotie1/sastra-alpaca2-13b-lora | taotie1/sastra-alpaca2-13b | Download model |
| kategori | ? Nama model | Alamat unduhan |
|---|---|---|
| Mengobrol | taotie1/sastra-alpaca2-13b-chat | Download model |
Menurut persyaratan.txt dependensi lingkungan instalasi, silakan pilih versi instalasi obor sesuai dengan perangkat Anda.
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) Nama Depan dan Bersihkan Data Pelatihan Anda [Opsional]
Pilih untuk menjalankan kode pembersih acak atau membersihkan semuanya, dan Anda dapat menyesuaikan aturan Anda di ill_ocr_regex.txt.
Jalankan full_sample_extraction.py untuk menggabungkan data ke dalam file.
Rujuk ke train-chinese-tokenizer.ipynb untuk pelatihan kosa kata, dan Anda dapat memodifikasi kode sesuai dengan kebutuhan Anda sendiri. Setelah pelatihan selesai, masukkan daftar kosakata Anda ke direktori My-Tokenizer. Gabungkan dengan tokenizer dari llama2 asli dengan cara berikut
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
Jalankan Text.py untuk menguji efek kosa kata
Kode pelatihan repositori ini menggunakan Deepspeed untuk mempercepat
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
- Menggunakan pretrain Script 2 pretrain-peft2.sh akan menghasilkan parameter lora. Anda dapat menjalankan skrip merge_lora_low_mem.py yang dimodifikasi dari cina-llama-alpaca-2 untuk menggabungkan
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
Tampilan penyesuaian yang dipersonalisasi untuk set data sederhana:

Gunakan skrip konversi di direktori SFT untuk mengonversi dataset menjadi format pelatihan yang diperlukan. Dataset asli yang digunakan dalam proyek ini semuanya dalam format JSON. Harap ubah skrip konversi sesuai kebutuhan:
Format file JSON yang dihasilkan adalah:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
Misalnya:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
File CSV yang dikonversi berisi kolom "teks", setiap perilaku adalah contoh pelatihan, dan setiap contoh pelatihan diatur ke dalam input model dalam format berikut:
"<s>Human: "+...+"n</s><s>Assistant: "+...
Misalnya:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
Jalankan SFT/SFT-Peft.sh di direktori SFT untuk memulai pelatihan. Untuk kode implementasi spesifik, lihat SFT/SFT-PEFT.PY


