literary alpaca2
1.0.0

Desde el vocabulario hasta el ajuste, esto es todo lo que necesitas
Este repositorio mostrará cómo construir su propio vocabulario a partir del vocabulario y usar el modelo de muelle previa y ajustar los ejemplos de código en el repositorio se capacitan principalmente en base a la versión de abrazadera de LLAMA2, proporcionando ejemplos de capacitación para GPU y TPU. Debido a la energía limitada del autor, hay errores en el script TPU, que es solo para referencia.
| tipo | describir |
|---|---|
| Novelas en línea | Datos de texto largo de alta calidad |
| Math23k | Problemas de matemáticas chinas |
| LCCC | Conjunto de diálogo de código abierto chino |
Cómo usar el conjunto de datos LCCC:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
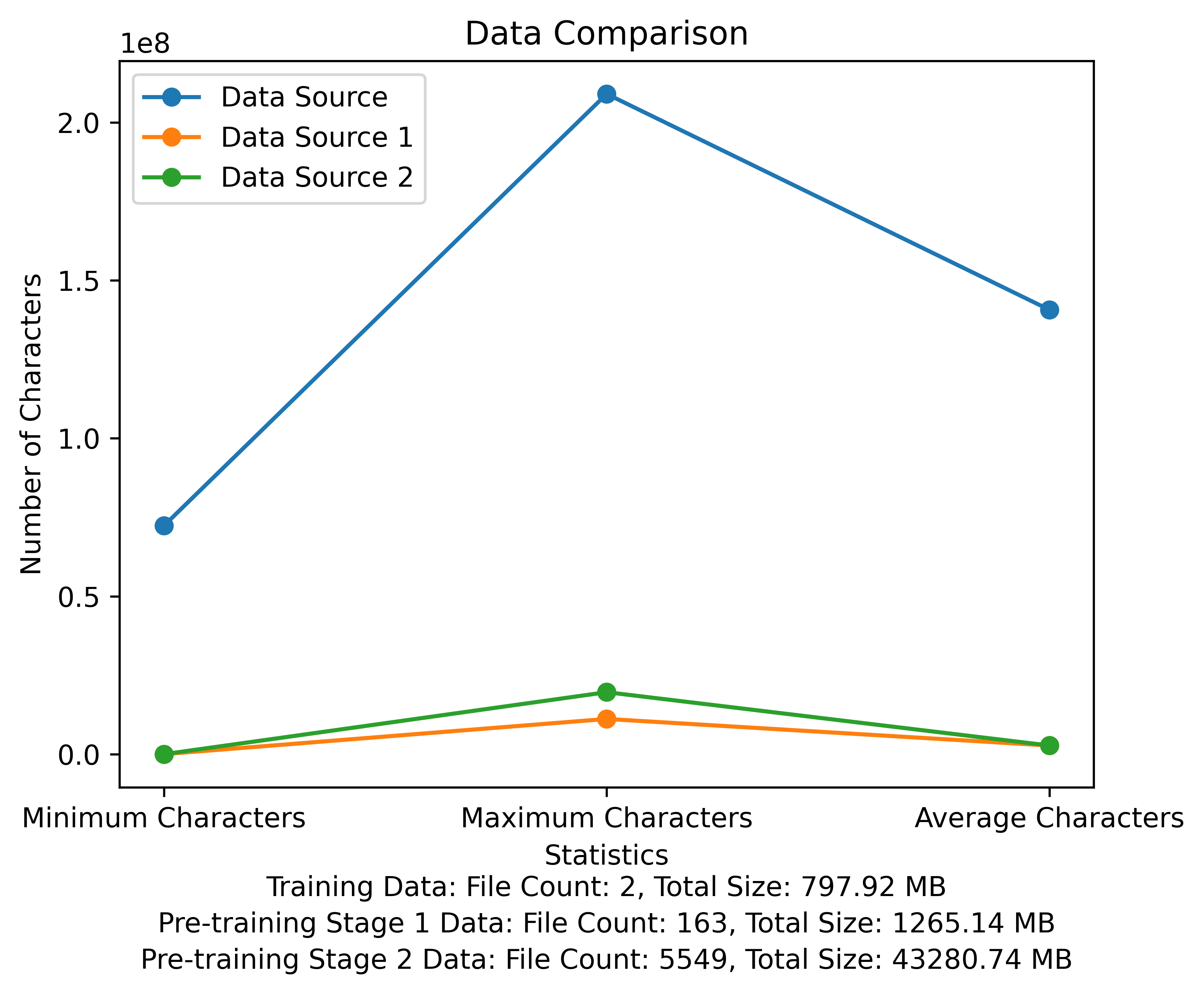
La lista de vocabulario y el diagrama de comparación de datos de la etapa previa al entrenamiento. La figura muestra el número de archivos y los tamaños de archivos totales de cada fuente de datos, y compara los caracteres mínimo y máximo y el número promedio de caracteres en cada archivo:
Enlace de descarga meta oficial: https://huggingface.co/meta-llama
El modelo chino pre-entrenado, los parámetros de Lora y los modelos de chat se han subido a la cara abrazada. Actualmente, solo hay modelos 13B.
| categoría | ? Nombre del modelo | Modelo base | Dirección de descarga |
|---|---|---|---|
| Pre-entrenamiento | taotie1/literary-alpaca2-13b | Meta-llama/Llama-2-13B-HF | Descargar modelo |
| Lora | taotie1/literary-alpaca2-13b-lora | taotie1/literary-alpaca2-13b | Descargar modelo |
| categoría | ? Nombre del modelo | Dirección de descarga |
|---|---|---|
| Charlar | taotie1/literary-alpaca2-13b-chat | Descargar modelo |
De acuerdo con los requisitos. Dependencias del entorno de instalación de txt, seleccione la versión de la instalación de la antorcha de acuerdo con su dispositivo.
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) Nombre y limpie sus datos de entrenamiento [opcional]
Elija ejecutar el código de limpieza aleatorio o limpiarlo todo, y puede personalizar sus reglas en Ill_ocr_regex.txt.
Ejecute full_sample_extraction.py para fusionar los datos en un archivo.
Consulte Train-chinese-tokenizer.ipynb para el entrenamiento de vocabulario, y puede modificar el código de acuerdo con sus propias necesidades. Después de completar el entrenamiento, coloque su lista de vocabulario en el directorio de My-Tokenizer. Fusionarse con el tokenizer del Llama2 original de la siguiente manera
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
Ejecutar Text.py para probar el efecto de vocabulario
Este código de entrenamiento de repositorio utiliza DeepSpeed para acelerar
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
- El uso de script de pretrain 2 Pretrain-Peft2.Sh generará parámetros LORA. Puede ejecutar el script merge_lora_low_mem.py modificado de chino-llama-alpaca-2 para fusionar
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
Visualización de ajustes personalizados a conjuntos de datos simples:

Use el script de conversión en el directorio SFT para convertir el conjunto de datos en el formato de capacitación requerido. Los conjuntos de datos originales utilizados en este proyecto están todos en formato JSON. Modifique el script de conversión según sea necesario:
El formato de archivo JSON generado es:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
Por ejemplo:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
El archivo CSV convertido contiene una columna de "texto", cada comportamiento es un ejemplo de entrenamiento, y cada ejemplo de entrenamiento se organiza en la entrada del modelo en el siguiente formato:
"<s>Human: "+...+"n</s><s>Assistant: "+...
Por ejemplo:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
Ejecute SFT/SFT-PEFT.SH en el directorio SFT para comenzar a entrenar. Para el código de implementación específico, consulte SFT/SFT-PEFT.PY


