literary alpaca2
1.0.0

Vom Wortschatz bis zur Feinabstimmung ist dies alles, was Sie brauchen
Dieses Repository zeigt, wie Sie Ihr eigenes Vokabular aus dem Wortschatz erstellen und das Dock-Modell vor der Ausbildung verwenden und die Codebeispiele im Repository federn. Sie werden hauptsächlich auf der Basis der umarmenden Gesichtsversion von LLAMA2 trainiert. Aufgrund der begrenzten Energie des Autors gibt es Fehler im TPU -Skript, das nur als Referenz dient.
| Typ | beschreiben |
|---|---|
| Online -Romane | Hochwertige lange Textdaten |
| Math23k | Chinesische Mathematikprobleme |
| LCCC | Chinesischer Open -Source -Dialog -Set |
So verwenden Sie den LCCC -Datensatz:
from datasets import load_dataset
dataset = load_dataset("lccc", "base") # or "large"
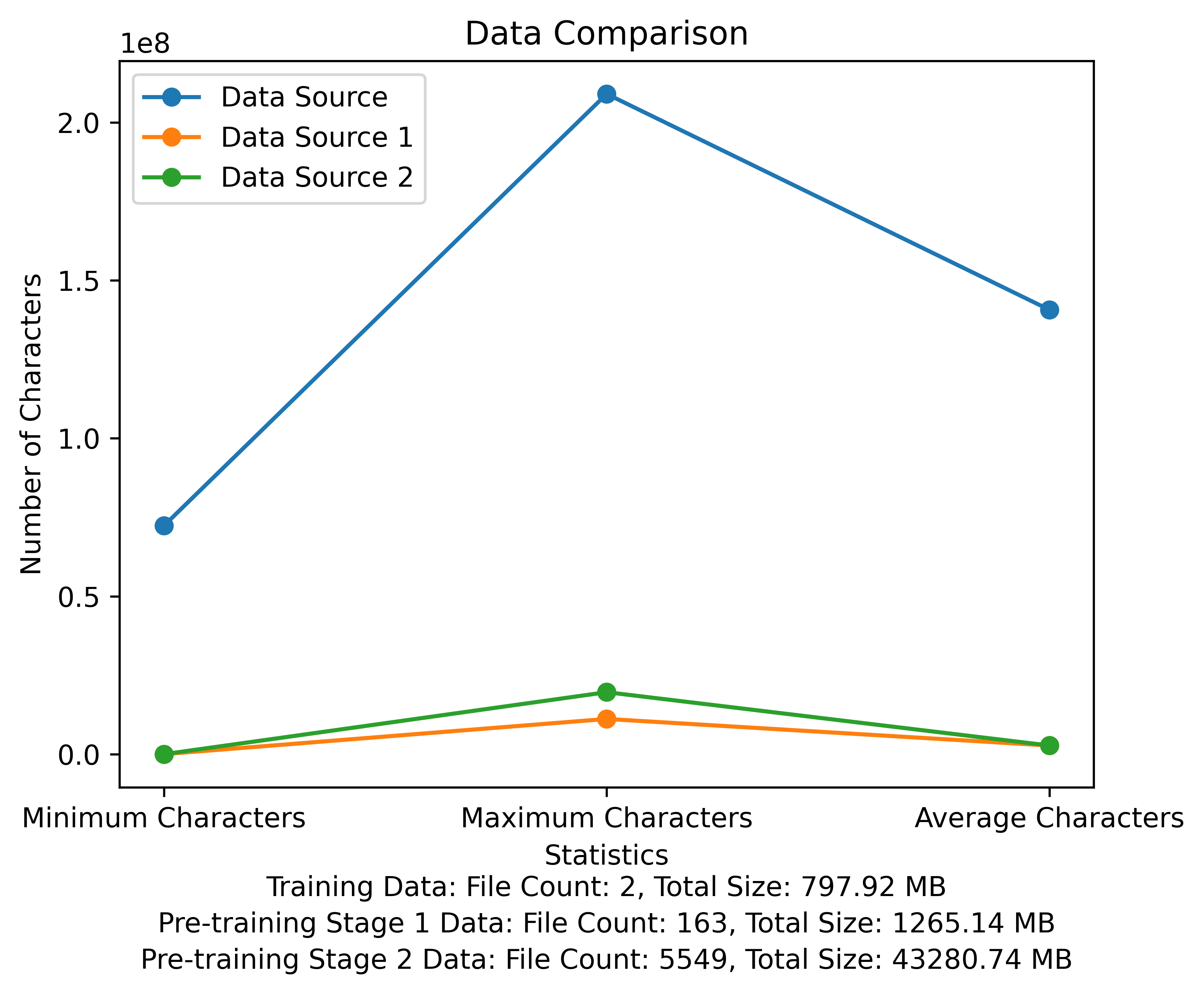
Die Wortschatzliste und das Datenvergleichsdiagramm der Vorausbildungsphase. Die Abbildung zeigt die Anzahl der Dateien und Gesamtdateigrößen jeder Datenquelle und vergleicht die minimalen und maximalen Zeichen und die durchschnittliche Anzahl der Zeichen in jeder Datei:
META Offizieller Download Link: https://huggingface.co/meta-llama
Das chinesische vorgebildete Modell, die LORA-Parameter und die Chat-Modelle wurden alle auf das Umarmung hochgeladen. Derzeit gibt es nur 13B -Modelle.
| Kategorie | Modellname | Basismodell | Adresse herunterladen |
|---|---|---|---|
| Vorausbildung | Taotie1/Literary-Alpaca2-13b | meta-llama/lama-2-13b-hf | Modell Download |
| Lora | Taotie1/Literary-Alpaca2-13b-Lora | Taotie1/Literary-Alpaca2-13b | Modell Download |
| Kategorie | Modellname | Adresse herunterladen |
|---|---|---|
| Chat | Taotie1/Literary-Alpaca2-13b-Chat | Modell Download |
Nach Anforderungen.
import torch
from transformers import AutoTokenizer , AutoModelForCausalLM
model = AutoModelForCausalLM . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , device_map = 'auto' , torch_dtype = torch . float16 , load_in_8bit = True )
model = model . eval ()
tokenizer = AutoTokenizer . from_pretrained ( 'taotie1/literary-alpaca2-13B-chat' , use_fast = False )
tokenizer . pad_token = tokenizer . eos_token
input_ids = tokenizer ([ '<s>Human: 什么是计算机n </s><s>Assistant: ' ], return_tensors = "pt" , add_special_tokens = False ). input_ids . to ( 'cuda' )
generate_input = {
"input_ids" : input_ids ,
"max_new_tokens" : 512 ,
"do_sample" : True ,
"top_k" : 50 ,
"top_p" : 0.95 ,
"temperature" : 0.3 ,
"repetition_penalty" : 1.3 ,
"eos_token_id" : tokenizer . eos_token_id ,
"bos_token_id" : tokenizer . bos_token_id ,
"pad_token_id" : tokenizer . pad_token_id
}
generate_ids = model . generate ( ** generate_input )
text = tokenizer . decode ( generate_ids [ 0 ])
print ( text ) Vorname und reinigen Sie Ihre Trainingsdaten [Optional]
Wählen Sie den zufälligen Reinigungscode aus oder reinigen Sie alles, und Sie können Ihre Regeln in ill_ocr_regex.txt anpassen.
Führen Sie full_sample_extraction.py aus, um die Daten in eine Datei zusammenzuführen.
Informationen zum Wortschatz finden Sie unter Train-Chinese-tokenizer.ipynb. Sie können den Code entsprechend Ihren eigenen Anforderungen ändern. Nach Abschluss des Trainings geben Sie Ihre Vokabularliste in das Verzeichnis von My-Tokenizer. Zusammenführen
bash运行
'
Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
python incorporation.py
'
Text.py ausführen, um den Wortschatzeffekt zu testen
Dieser Repository -Trainingscode verwendet Deepspeed, um zu beschleunigen
如两机8卡:torchrun --nnodes 2 --nproc_per_node 8
for name, param in model.named_parameters():
if "model.embed_tokens" not in name:
param.requires_grad = False
else:
param.requires_grad = True
--load_in_kbits 设置量化,不为4或8则不启用量化
--bf16 | --fp16 启用bf16需要gpu硬件支持
如果出现OOM请在deepspeed_config_peft2.json配置中添加:
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
- Verwenden von Vorab-Skript 2 Vorab-Peft2.SH generiert Lora-Parameter. Sie können das von Chinese-Llama-Alpaca-2 modifizierte Skript merge_lora_low_mem.py ausführen, um zusammenzuarbeiten
python merge_lora_low_mem.py
--base_model /root/LiteraryAlpaca2
--lora_model /root/autodl-tmp/LiteraryAlpaca2-lora
--output_type huggingface
--output_dir /root/autodl-tmp/LiteraryAlpaca2
Anzeige personalisierter Anpassungen an einfache Datensätze:

Verwenden Sie das Conversion -Skript im SFT -Verzeichnis, um den Datensatz in das erforderliche Trainingsformat umzuwandeln. Die in diesem Projekt verwendeten ursprünglichen Datensätze sind alle im JSON -Format. Bitte ändern Sie das Conversion -Skript nach Bedarf:
Das generierte JSON -Dateiformat lautet:
[
{"instruction" : ...,
"input" : ...,
"output" : ...},
...
]
Zum Beispiel:
{
"instruction": "下面是人类之间的对话与交流",
"input": "火锅 我 在 重庆 成都 吃 了 七八 顿 火锅",
"output": [
"哈哈哈哈 ! 那 我 的 嘴巴 可能 要 烂掉 !",
"不会 的 就是 好 油腻"
]
}
Die konvertierte CSV -Datei enthält eine Spalte von "Text", jedes Verhalten ist ein Trainingsbeispiel, und jedes Trainingsbeispiel ist in die Eingabe des Modells im folgenden Format organisiert:
"<s>Human: "+...+"n</s><s>Assistant: "+...
Zum Beispiel:
<s>Human: 镇海雅乐学校二年级的小朋友到一条小路的一边植树.小朋友们每隔2米种一棵树(马路两头都种了树),最后发现一共种了11棵,这条小路长多少米.</s><s>Assistant: 根据方程式x=(11-1)*2解得:
20</s>
Führen Sie SFT/sft-peft.sh im SFT-Verzeichnis aus, um mit dem Training zu beginnen. Für den spezifischen Implementierungscode siehe SFT/SFT-PEFT.py


