LLMBook zh.github.io
1.0.0
ผู้แต่ง: Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
ในตอนท้ายของปี 2022 Chatgpt ได้เปิดตัวอย่างน่าตกใจและเทคโนโลยีโมเดลภาษาขนาดใหญ่อย่างรวดเร็ว "กวาด" ทั้งสังคมและเทคโนโลยีปัญญาประดิษฐ์ได้นำไปสู่ความก้าวหน้าที่สำคัญ ต้องเผชิญกับประสิทธิภาพที่ทรงพลังของแบบจำลองภาษาขนาดใหญ่เราไม่สามารถช่วยได้ แต่ถามว่า: เทคโนโลยีที่อยู่เบื้องหลังโมเดลเหล่านี้คืออะไร? คำถามนี้ได้กลายเป็นจุดสนใจของการคิดสำหรับนักวิจัยทางวิทยาศาสตร์หลายคนอย่างไม่ต้องสงสัย จะต้องชี้ให้เห็นว่าเทคโนโลยีโมเดลขนาดใหญ่ไม่สามารถทำได้ในชั่วข้ามคืน ประวัติการพัฒนาของมันมีประสบการณ์การพัฒนาหลายขั้นตอนอย่างต่อเนื่องเช่นรูปแบบภาษาสถิติโมเดลภาษาเครือข่ายประสาทและแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อน การพัฒนาแต่ละขั้นตอนได้รวมความพยายามและความสำเร็จของนักวิจัยทางวิทยาศาสตร์หลายคน ในฐานะผู้สนับสนุนที่สำคัญของเทคโนโลยีรูปแบบภาษาขนาดใหญ่ OpenAI ได้สำรวจรายละเอียดทางเทคนิคจำนวนมากที่เกี่ยวข้องกับมันในอดีตและในที่สุดก็เปิดตัวชุด GPT ของโมเดลซึ่งนำไปสู่การเปลี่ยนแปลงทางเทคโนโลยีนี้
อย่างไรก็ตามตั้งแต่ GPT-3 ทีม OpenAI ได้กล่าวถึงรายละเอียดทางเทคนิคที่เกี่ยวข้องในสื่อสาธารณะและรายงานทางเทคนิคจำนวนมากส่วนใหญ่แนะนำเนื้อหาที่เกี่ยวข้องกับการตรวจสอบ จนถึงตอนนี้เทคโนโลยีหลักเกี่ยวกับโมเดล GPT Series ยังคงยากที่จะถอดรหัสอย่างเต็มที่ ในปัจจุบันความท้าทายที่สำคัญที่ชุมชนวิชาการต้องเผชิญคือมีทีมงานน้อยมากที่มีทรัพยากรเพียงพอที่จะสำรวจการฝึกอบรมแบบจำลองภาษาขนาดใหญ่อย่างเต็มที่ซึ่งนำไปสู่การขาดประสบการณ์มือแรกและความยากลำบากในการดำเนินการวิจัยที่เกี่ยวข้องโดยตรง การฝึกอบรมแบบจำลองขนาดใหญ่เกี่ยวข้องกับรายละเอียดการฝึกอบรมมากมายซึ่งมักจะไม่ได้รับโดยตรงจากเอกสารการวิจัยทางวิทยาศาสตร์ที่มีอยู่ เนื่องจากพารามิเตอร์จำนวนมากส่วนประกอบที่ซับซ้อนและกระบวนการฝึกอบรมที่ค่อนข้างซับซ้อนการสำรวจการทดลองในระยะแรกอาจนำไปสู่การเพิ่มจำนวนทวีคูณของจำนวนการทดลองหากไม่มีการแนะนำความรู้มาก่อน สิ่งนี้ทำให้เป็นเรื่องยากโดยเฉพาะอย่างยิ่งที่จะฝึกฝนประสบการณ์ของเทคโนโลยีขนาดใหญ่ไม่ต้องพูดถึงการสำรวจปัญหาการวิจัยทางวิทยาศาสตร์ที่เกี่ยวข้องตั้งแต่เริ่มต้นโดย จำกัด บทบาทของชุมชนวิชาการในคลื่นเทียมนี้อย่างมาก ในปัจจุบันโมเดลภาษาขนาดใหญ่ที่มีความสามารถที่แข็งแกร่งนั้นได้มาจากอุตสาหกรรมและแนวโน้มนี้อาจชัดเจนขึ้นเมื่อเวลาผ่านไป "ความรู้" เป็นสิ่งสำคัญมากสำหรับนักวิจัยทางวิทยาศาสตร์จากประสบการณ์มือแรก โดยการทำความรู้จักกับแกนกลางของเทคโนโลยีเท่านั้นที่เราสามารถเข้าใจได้อย่างแท้จริงว่าปัญหาใดที่มีความหมายและค้นหาวิธีแก้ปัญหา
เป็นเรื่องน่ายินดีที่ผู้คนค่อยๆตระหนักถึงความสำคัญของ "การเปิดกว้าง" ทั้งในด้านวิชาการและอุตสาหกรรมและสามารถมองเห็นโมเดลพื้นฐานสาธารณะมากขึ้นรหัสทางเทคนิคและเอกสารทางวิชาการซึ่งได้ส่งเสริม "ความโปร่งใส" ของเทคโนโลยีขนาดใหญ่อย่างมีประสิทธิภาพ ผ่านการเปิดกว้างและการแบ่งปันเท่านั้นเราสามารถรวบรวมภูมิปัญญาของมนุษยชาติทั้งหมดและส่งเสริมการพัฒนาเทคโนโลยีปัญญาประดิษฐ์ ในความเป็นจริงตามข้อมูลสาธารณะที่มีอยู่เทคโนโลยีโมเดลขนาดใหญ่ยังเป็น "ด้วยกฎที่ต้องปฏิบัติตาม" เช่นกระบวนการฝึกอบรมโดยรวมวิธีการทำความสะอาดข้อมูลเทคโนโลยีการปรับแต่งการปรับแต่งการปรับแต่งอัลกอริทึมการจัดตำแหน่งการตั้งค่าของมนุษย์ ฯลฯ ตามเทคโนโลยีเหล่านี้ด้วยการสนับสนุนทรัพยากรการคำนวณ ด้วยการเปิดเผยและเปิดเทคโนโลยีหลักมากขึ้น "ความโปร่งใส" ของเทคโนโลยีขนาดใหญ่จะได้รับการปรับปรุงให้ดีขึ้น
ในระยะสั้นเทคโนโลยีขนาดใหญ่เป็นขั้นตอนของการพัฒนาอย่างรวดเร็วและจำเป็นต้องมีการสำรวจหลักการพื้นฐานและจำเป็นต้องปรับปรุงเทคโนโลยีที่สำคัญ สำหรับนักวิจัยทางวิทยาศาสตร์งานวิจัยขนาดใหญ่นั้นเต็มไปด้วยจินตนาการและน่าหลงใหล ด้วยความก้าวหน้าอย่างต่อเนื่องและการแบ่งปันและการเปิดเทคโนโลยีเรามีเหตุผลที่จะเชื่อว่าเทคโนโลยีปัญญาประดิษฐ์จะก้าวหน้ามากขึ้นในอนาคตและจะมีผลกระทบอย่างลึกซึ้งยิ่งขึ้นในสาขามากขึ้น หนังสือเล่มนี้มีวัตถุประสงค์เพื่อให้ผู้อ่านมีความเข้าใจที่ครอบคลุมเกี่ยวกับเทคโนโลยีโมเดลขนาดใหญ่รวมถึงหลักการพื้นฐานเทคโนโลยีที่สำคัญและโอกาสในการใช้งาน ผ่านการวิจัยและการปฏิบัติเชิงลึกเราสามารถสำรวจและปรับปรุงเทคโนโลยีแบบจำลองขนาดใหญ่อย่างต่อเนื่องและมีส่วนร่วมในการพัฒนาสาขาปัญญาประดิษฐ์ เราหวังว่าผู้อ่านสามารถเข้าใจสถานการณ์ปัจจุบันและแนวโน้มในอนาคตของเทคโนโลยีขนาดใหญ่โดยการอ่านหนังสือเล่มนี้และให้คำแนะนำและแรงบันดาลใจสำหรับการวิจัยและการปฏิบัติของพวกเขา ให้เราทำงานร่วมกันเพื่อส่งเสริมการพัฒนาเทคโนโลยีปัญญาประดิษฐ์และมีส่วนร่วมในการสร้างอนาคตที่ชาญฉลาดและยั่งยืนมากขึ้น

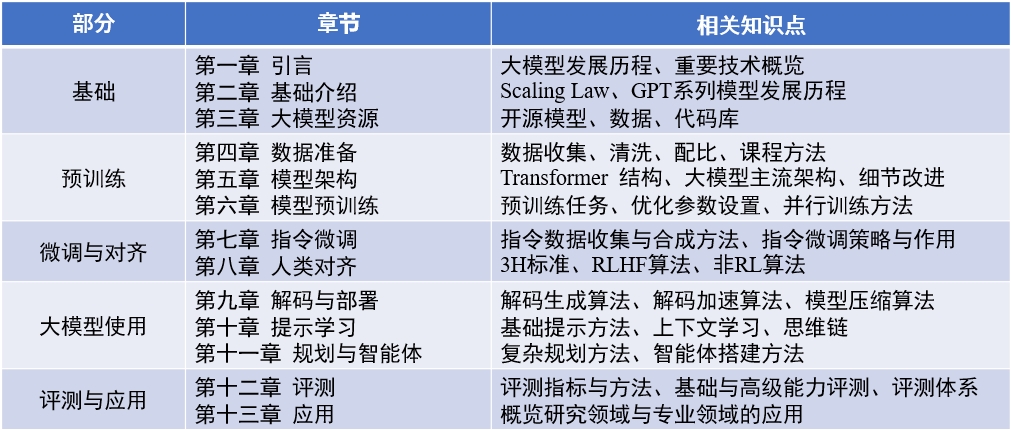
เนื้อหาของหนังสือ : "โมเดลภาษาใหญ่" (อัปเดต 2024-04-15)
กระดาษทบทวนภาษาอังกฤษ : llmsurvey
llmbox : ไลบรารีรหัส
Yulan Mockup : Code Library
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
รายชื่อผู้รับผิดชอบหลักและผู้เข้าร่วมในแต่ละบทของหนังสือเล่มนี้มีดังนี้:
นอกจากนี้ต้องขอบคุณนักเรียนคนอื่น ๆ ที่เข้าร่วมในการรวบรวมและพิสูจน์อักษรของหนังสือเล่มนี้ พวกเขา (จัดเรียงโดยพินอิน) ได้แก่ Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zibin, Guzihui, Guo Geyang Chengyuan, Li Ging-Yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, Ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Tang Yiru, Wang Jiapeng, Wang Lei จางเหลียงจู้เตียนยูและจุนยูโตะ
ในระหว่างกระบวนการเขียนหนังสือเล่มนี้ได้รับการสนับสนุนโดยทรัพยากรการคำนวณจากแพลตฟอร์มการแบ่งปันเครื่องมือทางวิทยาศาสตร์ขนาดใหญ่ของมหาวิทยาลัย Renmin of China ฉันอยากจะแสดงความขอบคุณอย่างจริงใจต่อครูสามคนเฉิน Yueguo, Lu Weizheng และ Shi Yuan
ภาพหน้าปกของหนังสือเล่มนี้สร้างขึ้นโดยเครื่องมือ AI และผลิตโดย Xu Lanling
ในกระบวนการเตรียมหนังสือภาษาจีนเราได้อ่านเอกสารคลาสสิกที่มีอยู่อย่างกว้างขวางรหัสที่เกี่ยวข้องและตำราเรียนแนวคิดหลักที่สกัดอัลกอริธึมหลักและรุ่นและจัดระเบียบและแนะนำพวกเขาอย่างเป็นระบบ เราได้แก้ไขร่างแรกของแต่ละบทหลายครั้งพยายามที่จะชี้แจงและการแสดงออกที่แม่นยำ อย่างไรก็ตามในระหว่างกระบวนการเขียนเรารู้สึกถึงข้อ จำกัด ของความสามารถและความรู้ของเราอย่างลึกซึ้ง แม้ว่าเราจะใช้ความพยายามอย่างมาก แต่ก็จะมีการละเว้นหรือจุดที่ไม่เหมาะสมอย่างหลีกเลี่ยงไม่ได้ หนังสือเล่มนี้ฉบับแรกเป็นเพียงจุดเริ่มต้น เราวางแผนที่จะอัปเดตและปรับปรุงเนื้อหาออนไลน์ต่อไปและโดยเฉพาะอย่างยิ่งเรายินดีต้อนรับผู้อ่านเพื่อทำการวิพากษ์วิจารณ์และคำแนะนำที่มีค่า นอกจากนี้เรายังจะขอบคุณผู้อ่านที่ให้คำแนะนำที่มีค่าบนเว็บไซต์ในเวลาเดียวกัน เราถือว่ากระบวนการเขียนหนังสือเล่มนี้เป็นกระบวนการเรียนรู้ของเราเองและเราหวังว่าจะมีการสื่อสารเชิงลึกกับผู้อ่านผ่านหนังสือเล่มนี้และเรียนรู้จากเพื่อนในอุตสาหกรรมมากขึ้น
หากคุณมีความคิดเห็นความคิดเห็นและข้อเสนอแนะ (ยืนยันก่อนว่าเวอร์ชันล่าสุดได้รับการแก้ไข) โปรดให้ข้อเสนอแนะผ่านหน้าปัญหาของ GitHub หรือส่งอีเมลไปยังที่อยู่อีเมลของผู้เขียน Batmanfly ที่ qq.com , Lijunyi ที่ ruc.edu.cn , Francis_kun_zhou ที่ ruc.edu.cn


