LLMBook zh.github.io
1.0.0
Penulis: Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
Pada akhir 2022, ChatGPT diluncurkan secara mengejutkan, dan teknologi model berbahasa besar dengan cepat "menyapu" seluruh masyarakat, dan teknologi kecerdasan buatan telah mengantarkan kemajuan penting. Dihadapkan dengan kinerja yang kuat dari model bahasa besar, kami tidak dapat membantu tetapi bertanya: Apa sebenarnya teknologi di balik model ini? Pertanyaan ini tidak diragukan lagi menjadi fokus berpikir bagi banyak peneliti ilmiah. Harus ditunjukkan bahwa teknologi model besar tidak tercapai dalam semalam. Sejarah pengembangannya secara berturut-turut mengalami beberapa tahap pengembangan seperti model bahasa statistik, model bahasa jaringan saraf, dan model bahasa pra-terlatih. Setiap langkah pembangunan telah memadatkan upaya dan pencapaian banyak peneliti ilmiah. Sebagai promotor penting dari teknologi model bahasa besar, OpenAI telah mengeksplorasi sejumlah besar detail teknis yang terkait dengannya di masa lalu dan akhirnya meluncurkan serangkaian model GPT, yang memimpin perubahan teknologi ini.
Namun, sejak GPT-3, tim OpenAI jarang menyebutkan detail teknis yang relevan dalam bahan publik, dan banyak laporan teknis terutama memperkenalkan konten terkait ulasan. Sejauh ini, teknologi inti tentang model seri GPT masih sulit untuk didekripsi sepenuhnya. Saat ini, tantangan utama yang dihadapi komunitas akademik adalah bahwa ada sangat sedikit tim dengan sumber daya yang cukup untuk sepenuhnya mengeksplorasi pelatihan model bahasa besar, yang mengarah pada kurangnya pengalaman langsung dan kesulitan dalam melakukan penelitian terkait secara langsung. Pelatihan model besar melibatkan banyak detail pelatihan, yang seringkali tidak secara langsung diperoleh dari makalah penelitian ilmiah yang ada. Karena banyak parameter, komponen yang kompleks, dan proses pelatihan yang relatif kompleks, eksplorasi eksperimental awal dapat menyebabkan peningkatan eksponensial dalam jumlah percobaan jika tidak ada pengetahuan sebelumnya yang diperkenalkan. Ini membuatnya sangat sulit untuk menguasai pengalaman teknologi model besar, belum lagi mengeksplorasi masalah penelitian ilmiah terkait dari awal, sangat membatasi peran yang dimainkan oleh komunitas akademik dalam gelombang buatan ini. Saat ini, model bahasa besar dengan kemampuan kuat pada dasarnya berasal dari industri, dan tren ini mungkin menjadi lebih jelas dari waktu ke waktu. "Pengetahuan" sangat penting bagi para peneliti ilmiah dari pengalaman langsung. Hanya dengan mengetahui inti teknologi, kita dapat benar -benar memahami masalah mana yang bermakna dan menemukan solusi.
Sangat menyenangkan bahwa orang secara bertahap menyadari pentingnya "keterbukaan" di akademisi dan industri, dan dapat melihat lebih banyak model dasar publik, kode teknis dan makalah akademik, yang secara efektif mempromosikan "transparansi" teknologi model besar. Hanya melalui keterbukaan dan berbagi kita dapat mengumpulkan kebijaksanaan semua umat manusia dan bersama -sama mempromosikan pengembangan teknologi kecerdasan buatan. Faktanya, menurut informasi publik yang ada, teknologi model besar juga "dengan aturan yang harus diikuti", seperti proses pelatihan keseluruhan, metode pembersihan data, teknologi penyempurnaan instruksi, algoritma penyelarasan preferensi manusia, dll. Menurut teknologi ini, dengan dukungan sumber daya yang komputasi, hasil baik-baik. Dengan mengungkapkan dan membuka lebih banyak teknologi inti, "transparansi" teknologi model besar akan lebih baik.
Singkatnya, teknologi model besar sedang dalam tahap perkembangan yang cepat, dan prinsip-prinsip dasar perlu dieksplorasi dan teknologi utama perlu ditingkatkan. Bagi para peneliti ilmiah, pekerjaan penelitian model besar penuh dengan imajinasi dan menarik. Dengan kemajuan dan berbagi yang berkelanjutan dan membuka teknologi, kami memiliki alasan untuk percaya bahwa teknologi kecerdasan buatan akan membuat kemajuan yang lebih besar di masa depan dan akan memiliki dampak yang lebih mendalam di lebih banyak bidang. Buku ini bertujuan untuk memberi pembaca pemahaman yang komprehensif tentang teknologi model besar, termasuk prinsip -prinsip dasar, teknologi utama, dan prospek aplikasi. Melalui penelitian dan praktik yang mendalam, kita dapat terus mengeksplorasi dan meningkatkan teknologi model skala besar dan berkontribusi pada pengembangan bidang kecerdasan buatan. Kami berharap bahwa pembaca dapat sangat memahami situasi saat ini dan tren masa depan teknologi model besar dengan membaca buku ini, dan memberikan bimbingan dan inspirasi untuk penelitian dan praktik mereka. Mari kita bekerja sama untuk mempromosikan pengembangan teknologi kecerdasan buatan dan berkontribusi untuk membangun masa depan yang lebih cerdas dan lebih berkelanjutan.

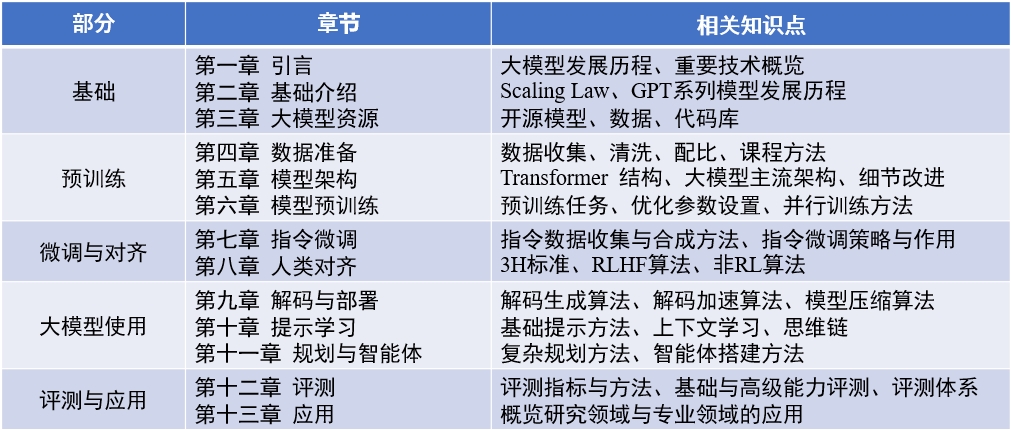
Konten Buku : "Model Bahasa Besar" (diperbarui 2024-04-15)
Makalah Tinjauan Bahasa Inggris : llmsurvey
LLMBox : Perpustakaan Kode
Yulan Mockup : Perpustakaan Kode
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
Daftar orang dan peserta utama yang bertanggung jawab di setiap bab buku ini adalah sebagai berikut:
Juga, terima kasih kepada siswa lain yang berpartisipasi dalam kompilasi dan proofreading buku ini. Mereka (diurutkan oleh Pinyin) adalah Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zibin, Gu Zihui, Guo Geyang, He Dongnan, Hou, Hou, Hou, Hohming, Hohming, Hohming, Hohming, Hohming, Hohming, Hu. Chengyuan, Li Ging-yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, Ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Wang Japeng, Wang Lei, Wang Shuting, Yao Yau, Yin Fing, Wang Lei, Wang Shuting, Yao, Yao Fance, Wang Shuting, Yao, Yao Fance, Wang Shuting, Yao, Yao, Zhang Liang, Zhu Tianyu dan Zhu Yutao.
Selama proses penulisan, buku ini didukung oleh komputasi sumber daya dari platform berbagi instrumen ilmiah berskala besar dari Renmin University of China. Saya ingin mengucapkan terima kasih yang tulus kepada ketiga guru Chen Yueguo, Lu Weizheng dan Shi Yuan.
Gambar sampul buku ini dihasilkan oleh AI Tools dan diproduksi oleh Xu Lanling.
Dalam proses mempersiapkan buku -buku Cina, kami membaca secara luas makalah klasik yang ada, kode dan buku teks terkait, mengekstraksi konsep inti, algoritma dan model arus utama, dan mengatur dan memperkenalkannya secara sistematis. Kami telah merevisi draf pertama dari setiap bab berkali -kali, berusaha untuk mengklarifikasi dan ekspresi yang akurat. Namun, selama proses penulisan, kami sangat merasakan keterbatasan kemampuan dan pengetahuan kami sendiri. Meskipun kami telah melakukan upaya besar, pasti akan ada kelalaian atau poin yang tidak pantas. Edisi pertama buku ini hanyalah titik awal. Kami berencana untuk terus memperbarui dan meningkatkan konten secara online, dan kami sangat menyambut pembaca untuk membuat kritik dan saran yang berharga. Kami juga akan berterima kasih kepada pembaca yang membuat saran berharga di situs web pada saat yang sama. Kami menganggap proses menulis buku ini sebagai proses belajar kami sendiri, dan kami juga berharap memiliki komunikasi mendalam dengan pembaca melalui buku ini dan belajar dari lebih banyak rekan industri.
Jika Anda memiliki komentar, komentar, dan saran (pertama -tama konfirmasikan apakah versi terbaru telah diperbaiki), berikan umpan balik melalui halaman masalah GitHub, atau kirim email ke alamat email penulis BatmanFly di qq.com , Lijunyi di Ruc.edu.cn , Francis_kun_zhou di ruc.edu.cn , steventiNang .


