LLMBook zh.github.io
1.0.0
저자 : Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
2022 년 말, Chatgpt는 충격적으로 출시되었으며, 대규모 모델 기술은 전체 사회를 빠르게 "스윕"했으며 인공 지능 기술은 중요한 진전을 이끌어 냈습니다. 대형 언어 모델의 강력한 성능에 직면 한 우리는 도움을 줄 수는 없습니다.이 모델의 기술은 정확히 무엇입니까? 이 질문은 의심 할 여지없이 많은 과학 연구자들에게 사고의 초점이되었습니다. 큰 모델 기술은 하룻밤 사이에 달성되지 않는다는 것을 지적해야합니다. 개발 기록은 통계 언어 모델, 신경망 언어 모델 및 미리 훈련 된 언어 모델과 같은 여러 개발 단계를 연속적으로 경험해 왔습니다. 개발의 각 단계는 많은 과학 연구자들의 노력과 성취를 요약했습니다. 대형 언어 모델 기술의 중요한 프로모터 인 OpenAI는 과거에 관련된 많은 기술 세부 사항을 탐색하고 마침내 GPT 시리즈 모델을 출시하여 이러한 기술 변화를 이끌었습니다.
그러나 GPT-3 이후 OpenAI 팀은 공개 자료에 대한 관련 기술 세부 사항을 거의 언급하지 않았으며 많은 기술 보고서가 주로 검토 관련 컨텐츠를 도입합니다. 지금까지 GPT 시리즈 모델에 대한 핵심 기술은 여전히 완전히 해독하기가 어렵습니다. 현재, 학계가 직면 한 주요 과제는 대형 언어 모델 교육을 완전히 탐색하기에 충분한 자원을 가진 팀이 거의 없어서 직접적인 경험이 부족하고 관련 연구를 직접 수행하는 데 어려움을 겪고 있다는 것입니다. 대규모 모델 교육에는 많은 교육 세부 사항이 포함되며, 종종 기존 과학 연구 논문에서 직접 얻지 못합니다. 수많은 매개 변수, 복잡한 구성 요소 및 비교적 복잡한 훈련 프로세스로 인해 초기 실험 탐색은 사전 지식이 도입되지 않으면 실험 수의 기하 급수적 인 증가로 이어질 수 있습니다. 이로 인해 관련 과학적 연구 문제를 처음부터 탐색하는 것은 말할 것도없이 큰 모델 기술의 경험을 마스터하기가 어려워지며,이 인공적인 물결에서 학술 공동체가 수행하는 역할을 크게 제한합니다. 현재 강력한 기능을 갖춘 대형 언어 모델은 기본적으로 업계에서 파생되며 이러한 추세는 시간이 지남에 따라 더욱 분명해질 수 있습니다. "노하우"는 직접적인 경험을 가진 과학 연구자들에게 매우 중요합니다. 기술의 핵심을 알면서만 어떤 문제가 의미가 있는지를 진정으로 이해하고 해결책을 찾을 수 있습니다.
사람들이 학계와 산업 모두에서 "개방성"의 중요성을 점차적으로 깨달았으며, 대형 모델 기술의 "투명성"을 효과적으로 홍보 한 점점 더 많은 공개 기본 모델, 기술 코드 및 학술 논문을 볼 수 있습니다. 개방성과 공유를 통해서만 우리는 모든 인류의 지혜를 모으고 인공 지능 기술의 발전을 공동으로 홍보 할 수 있습니다. 실제로, 기존의 공개 정보에 따르면, 대형 모델 기술은 전반적인 교육 프로세스, 데이터 청소 방법, 교육용 미세 조정 기술, 인적 선호도 정렬 알고리즘 등과 같은 "따라야하는 규칙"도 있습니다. 이러한 기술에 따르면 자원 계산 자원에 따르면 R & D 직원은 비교적 부드럽게 대규모 교육 프로세스를 완료하고 우수한 모델 결과를 달성 할 수있었습니다. 더 많은 핵심 기술의 공개 및 개방으로 인해 대형 모델 기술의 "투명성"이 더욱 향상 될 것입니다.
요컨대, 대형 모델 기술은 빠른 개발 단계에 있으며 기본 원칙을 탐색해야하며 주요 기술을 개선해야합니다. 과학 연구자들에게 큰 모델 연구 작업은 상상력과 매력으로 가득합니다. 우리는 지속적인 발전과 공유 및 공유 및 개방으로 인공 지능 기술이 미래에 더 큰 진전을 이룰 것이라고 믿고 더 많은 분야에 더 큰 영향을 미칠 것이라고 믿을만한 이유가 있습니다. 이 책은 독자들에게 기본 원칙, 주요 기술 및 응용 프로그램 전망을 포함한 대형 모델 기술에 대한 포괄적 인 이해를 제공하는 것을 목표로합니다. 심층적 인 연구와 실습을 통해 우리는 대규모 모델 기술을 지속적으로 탐색하고 개선하고 인공 지능 분야의 개발에 기여할 수 있습니다. 우리는 독자 들이이 책을 읽음으로써 큰 모델 기술의 현재 상황과 미래의 트렌드를 깊이 이해하고 연구와 실습에 대한 지침과 영감을 제공하기를 바랍니다. 인공 지능 기술의 발전을 촉진하기 위해 함께 노력하고 더 똑똑하고 지속 가능한 미래를 구축하는 데 기여합시다.

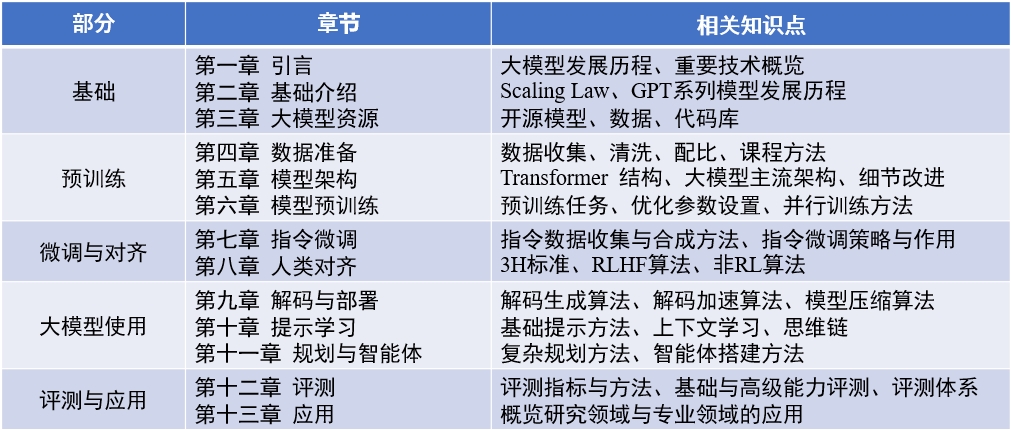
책의 내용 : "큰 언어 모델" (업데이트 된 2024-04-15)
영어 검토 논문 : llmsurvey
llmbox : 코드 라이브러리
Yulan Mockup : 코드 라이브러리
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
이 책의 각 장의 주요 책임있는 사람과 참가자 목록은 다음과 같습니다.
또한이 책의 편집 및 교정에 참여한 다른 학생들에게 감사합니다. 그들은 (Pinyin에 의해 분류) Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zhibin, Gu Zihui, Guo Geyang, Ho hou Xinming, Hu Yiwen, Li Bingnan, Hu Ywen Chengyuan, Li Ging-Yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, Ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Tang Yiru, Wang Jiapeng, Wang Lei, Wang Shuting, Yao Feng, Yan Yanbin, Zhanbin yanbin Zhang Liang, Zhu Tianyu 및 Zhu Yutao.
작문 과정 에서이 책은 중국 Renmin University의 대규모 과학 도구 공유 플랫폼의 자원을 계산하여 지원되었습니다. 세 교사 인 Chen Yueguo, Lu Weizheng 및 Shi Yuan에게 진심으로 진심으로 표현하고 싶습니다.
이 책의 표지 이미지는 AI 도구에 의해 생성되며 Xu Lanling에서 제작합니다.
중국 책을 준비하는 과정에서, 우리는 기존의 고전적인 논문, 관련 코드 및 교과서, 추출 된 핵심 개념, 주류 알고리즘 및 모델을 광범위하게 읽고 체계적으로 구성하고 소개했습니다. 우리는 각 장의 첫 번째 초안을 여러 번 수정하여 표현을 명확하고 정확한 표현을 위해 노력했습니다. 그러나 글쓰기 과정에서 우리는 자신의 능력과 지식의 한계를 깊이 느낍니다. 우리는 큰 노력을 기울 였지만 필연적으로 누락이나 부적절한 요점이있을 것입니다. 이 책의 첫 번째 판은 출발점 일뿐입니다. 우리는 온라인 컨텐츠를 계속 업데이트하고 개선 할 계획이며, 특히 독자들이 귀중한 비판과 제안을하도록 환영합니다. 우리는 또한 웹 사이트에서 동시에 귀중한 제안을하는 독자들에게도 감사를 표할 것입니다. 우리는이 책을 우리 자신의 학습 과정으로 간주하며,이 책을 통해 독자들과 심층적 인 의사 소통을하고 더 많은 업계 동료들로부터 배우기를 희망합니다.
의견, 의견 및 제안이 있으면 (최신 버전이 수정되었는지 확인) GitHub의 문제 페이지를 통해 피드백을 제공하거나 QQ.com의 저자의 이메일 주소 Batmanfly , lijunyi (ruc.edu.cn) , francis_kun_zhou (ruc.edu.cn , Steventianyitang) 로 이메일을 보내주십시오.


