LLMBook zh.github.io
1.0.0
Автор: Чжао Синь, Ли Джуни, Чжоу Кун, Тан Тяни, Вэнь Джиронг
В конце 2022 года Chatgpt был запущен шокирующе, а модельная технология с крупноязычной моделей быстро «охватила» все общество, а технология искусственного интеллекта вступила в важный прогресс. Столкнувшись с мощными показателями крупных языковых моделей, мы не можем не спросить: какова технология этих моделей? Этот вопрос, несомненно, стал центром мышления для многих научных исследователей. Следует отметить, что технология большой модели не достигается в течение ночи. История развития последовательно пережила множественные этапы разработки, такие как статистические языковые модели, модели языка нейронной сети и предварительно обученные языковые модели. Каждый этап развития сжал усилия и достижения многих научных исследователей. Как важный промоутер технологии крупной языковой модели, OpenAI исследовал большое количество технических деталей, связанных с ней в прошлом, и, наконец, запустил серию моделей GPT, что привело к этим технологическим изменениям.
Однако, начиная с GPT-3, команда OpenAI редко упоминала соответствующие технические детали в общественных материалах, и многие технические отчеты в основном представляют контент, связанный с проверкой. Пока что основная технология модели серии GPT по -прежнему трудно полностью расшифровать. В настоящее время основная задача, стоящая перед академическим сообществом, заключается в том, что существует очень мало команд с достаточным количеством ресурсов для полного изучения крупных языковых моделей, что приводит к отсутствию опыта из первых рук и трудностей с непосредственным проведением связанных исследований. Крупная модельная обучение включает в себя множество деталей обучения, которые часто не получают непосредственно из существующих научных исследовательских работ. Из -за многочисленных параметров, сложных компонентов и относительно сложного обучения, ранние экспериментальные исследования могут привести к экспоненциальному увеличению количества экспериментов, если не вводится предварительные знания. Это затрудняет овладение опытом технологий Big Model, не говоря уже о изучении связанных вопросов научных исследований с нуля, что значительно ограничивает роль академического сообщества в этой искусственной волне. В настоящее время крупные языковые модели с сильными возможностями в основном получены из отрасли, и эта тенденция может стать более очевидной с течением времени. «Ноу-хау» очень важно для научных исследователей из первого рук. Только узнав, как ядро технологии мы можем по -настоящему понять, какие проблемы являются значимыми, и найти решения.
Приятно, что люди постепенно осознали важность «открытости» как в академических кругах, так и в отрасли, и могут видеть все больше и больше общественных базовых моделей, технических кодов и академических работ, которые эффективно способствуют «прозрачности» технологии крупной модели. Только благодаря открытости и обмену мы можем собрать мудрость всего человечества и совместно способствовать развитию технологий искусственного интеллекта. Фактически, в соответствии с существующей общественной информацией, технология Big Model также является «с которыми следует следовать», такие как общий процесс обучения, методы очистки данных, технология тонкой настройки обучения, алгоритмы выравнивания предпочтений человека и т. Д. В соответствии с этими технологиями, при поддержке вычислительных ресурсов сотрудники R & D смогли завершить общий процесс обучения крупной модели. С раскрытием и открытием более основных технологий, «прозрачность» технологии крупно-модели будет улучшена.
Короче говоря, технология крупно-модели находится в стадии быстрого развития, и необходимо изучить основные принципы, и ключевые технологии должны быть улучшены. Для научных исследователей большая модельная исследовательская работа полна воображения и увлекательной. Благодаря постоянному продвижению, обмену и открытию технологий, у нас есть основания полагать, что технология искусственного интеллекта будет добиваться большего прогресса в будущем и окажет более глубокое влияние на большее количество областей. Эта книга направлена на то, чтобы предоставить читателям всестороннее понимание технологии Big Model, включая ее основные принципы, ключевые технологии и перспективы применения. Благодаря углубленным исследованиям и практике мы можем постоянно изучать и улучшать крупномасштабные технологии моделей и способствовать развитию области искусственного интеллекта. Мы надеемся, что читатели смогут глубоко понять текущую ситуацию и будущие тенденции больших модельных технологий, прочитав эту книгу, а также предоставить руководство и вдохновение для их исследований и практики. Давайте работать вместе, чтобы способствовать развитию технологий искусственного интеллекта и внести свой вклад в создание более умного и устойчивого будущего.

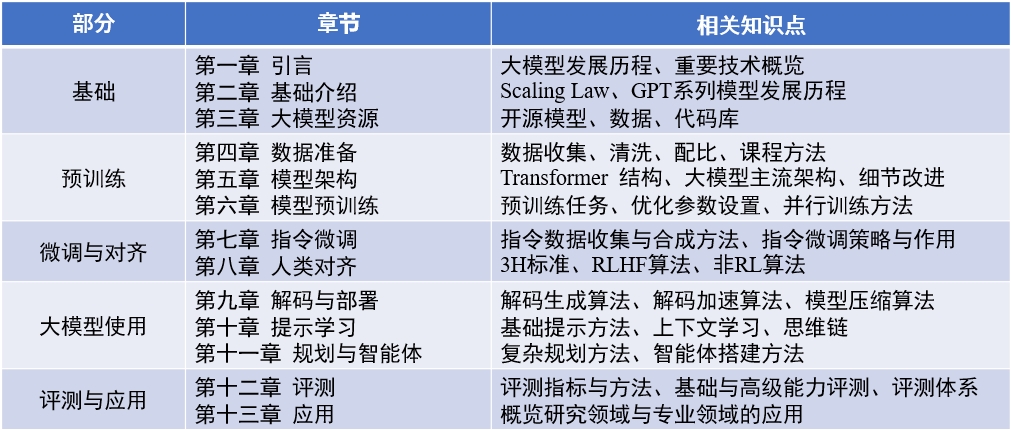
Содержание книги : «Модель большого языка» (обновленная 2024-04-15)
Английский обзорный документ : Llmsurvey
Llmbox : библиотека кода
Yulan Mockup : Кодовая библиотека
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
Список основных ответственных людей и участников в каждой главе этой книги заключается в следующем:
Кроме того, благодаря другим студентам, которые участвовали в сборнике и корректуре этой книги. Они (сортируются пининином) - это Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Sin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zhibin, Gu Zihui, Guo Geyang, He Dongnan, Hou xinming, hu yiwin, li Bynemuan, hou, Hu yiwin, li Byneren, hou yiwinen, hou yiwinen, hou yiwen, hou yiwinen, hu yiwen Ли Гин-Юань, Лю Энез, Лю Джионганн, Лю Зихан, Луо Веньянг, Мей Ланг, Оу Кешан, Пенг Хан, Руан Кай, Су Вейханг, Солнчик, Танг, Тан Йиру, Ван Цзяпенг, Ван Лей, Ванг, Яо Фенг, Иин Янбин, Занггн, Зангн, Зангн, Зангн, Зангн Лян, Чжу Тянью и Чжу Ютао.
В процессе написания эта книга была поддержана вычислительностью ресурсов из крупномасштабной научной платформы для обмена инструментами в Китайском университете Ренмина. Я хотел бы выразить искреннюю благодарность трем учителям Чэну Ююгу, Лу Вейзхенгу и Ши Юаню.
Изображение обложки этой книги генерируется инструментами ИИ и производится Сюй Ланлингом.
В процессе подготовки китайских книг мы широко читаем существующие классические статьи, связанные коды и учебники, извлеченные основные концепции, основные алгоритмы и модели, а также организовали и вводя их систематически. Мы много раз пересмотрели первый черновик каждой главы, стремясь прояснить и точные выражения. Однако в процессе написания мы глубоко чувствуем ограничения наших собственных способностей и знаний. Хотя мы приложили большие усилия, неизбежно будут упущения или неуместные пункты. Первое издание этой книги является лишь отправной точкой. Мы планируем продолжать обновлять и улучшать контент в Интернете, и мы особенно приветствуем читателей, чтобы они критиковали и предложили. Мы также поблагодарим читателей, которые одновременно вносят ценные предложения на веб -сайте. Мы рассматриваем процесс написания этой книги как наш собственный учебный процесс, и мы также надеемся, что будут иметь глубокое общение с читателями через эту книгу и учиться у большего количества сверстников отрасли.
Если у вас есть какие -либо комментарии, комментарии и предложения (сначала подтвердите, была ли последняя версия исправлена), пожалуйста, предоставьте обратную связь на странице выпуска Github или отправьте ее по электронной почте по адресу автора по электронной почте Batmanfly на QQ.com , Lijunyi на ruc.edu.cn , francis_kun_zhou atruc.edu.cn , steventianyang attlook.com .


