LLMBook zh.github.io
1.0.0
Autor: Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
No final de 2022, o ChatGPT foi lançado chocantemente, e a tecnologia de modelos de grande língua rapidamente "varreu" toda a sociedade, e a tecnologia de inteligência artificial deu início a um progresso importante. Diante do poderoso desempenho de grandes modelos de idiomas, não podemos deixar de perguntar: o que exatamente é a tecnologia por trás desses modelos? Esta questão, sem dúvida, tornou -se o foco do pensamento para muitos pesquisadores científicos. Deve -se ressaltar que a grande tecnologia de modelo não é alcançada da noite para o dia. Sua história de desenvolvimento experimentou sucessivamente vários estágios de desenvolvimento, como modelos de linguagem estatística, modelos de linguagem de rede neural e modelos de idiomas pré-treinados. Cada etapa do desenvolvimento condensou os esforços e realizações de muitos pesquisadores científicos. Como um importante promotor da tecnologia de modelos de grandes idiomas, o OpenAI explorou um grande número de detalhes técnicos relacionados a ela no passado e finalmente lançou a série GPT de modelos, liderando essa mudança tecnológica.
No entanto, desde o GPT-3, a equipe do OpenAI raramente mencionou detalhes técnicos relevantes em materiais públicos, e muitos relatórios técnicos introduzem principalmente o conteúdo relacionado à revisão. Até agora, a tecnologia principal sobre o modelo da série GPT ainda é difícil de descriptografar totalmente. Atualmente, o principal desafio enfrentado pela comunidade acadêmica é que existem muito poucas equipes com recursos suficientes para explorar completamente o grande treinamento de modelos de idiomas, o que leva à falta de experiência em primeira mão e dificuldade em conduzir diretamente pesquisas relacionadas. O grande treinamento de modelos envolve muitos detalhes de treinamento, que geralmente não são obtidos diretamente dos trabalhos de pesquisa científica existentes. Devido a seus numerosos parâmetros, componentes complexos e processo de treinamento relativamente complexo, as explorações experimentais iniciais podem levar a um aumento exponencial no número de experimentos se nenhum conhecimento prévio for introduzido. Isso torna particularmente difícil dominar a experiência da Big Model Technology, sem mencionar explorar questões de pesquisa científica relacionadas do zero, limitando bastante o papel desempenhado pela comunidade acadêmica nessa onda artificial. Atualmente, grandes modelos de idiomas com recursos fortes são basicamente derivados da indústria, e essa tendência pode se tornar mais óbvia ao longo do tempo. "Know-how" é muito importante para pesquisadores científicos da experiência em primeira mão. Somente conhecendo o núcleo da tecnologia, podemos realmente entender quais problemas são significativos e encontrar soluções.
É gratificante que as pessoas tenham percebido gradualmente a importância de "abertura" na academia e na indústria e possam ver cada vez mais modelos básicos públicos, códigos técnicos e trabalhos acadêmicos, que promoveram efetivamente a "transparência" da tecnologia de grandes modelos. Somente através da abertura e do compartilhamento podemos reunir a sabedoria de toda a humanidade e promover em conjunto o desenvolvimento da tecnologia de inteligência artificial. De fato, de acordo com as informações públicas existentes, a tecnologia Big Model também está "com regras a seguir", como processo geral de treinamento, métodos de limpeza de dados, tecnologia de ajuste de fino de instruções, algoritmos de alinhamento de preferências humanas, etc. De acordo com esses tecnologias, com o suporte de recursos de computação e o pessoal de R&D foi capaz de concluir o processo geral de treinamento do grande modelo relativamente bem e alcançar o bom modelo e alcançar o bom modelo. Com a revelação e a abertura de mais tecnologias principais, a "transparência" da tecnologia de modelos grandes será melhorada ainda mais.
Em resumo, a tecnologia de modelo grande está em um estágio de desenvolvimento rápido, e os princípios básicos precisam ser explorados e as principais tecnologias precisam ser melhoradas. Para pesquisadores científicos, o grande trabalho de pesquisa modelo é cheio de imaginação e fascinante. Com o avanço contínuo e o compartilhamento e a abertura da tecnologia, temos motivos para acreditar que a tecnologia de inteligência artificial fará maior progresso no futuro e terá um impacto mais profundo em mais campos. Este livro tem como objetivo fornecer aos leitores uma compreensão abrangente da grande tecnologia de modelo, incluindo seus princípios básicos, tecnologias -chave e perspectivas de aplicativos. Através de pesquisas e práticas aprofundadas, podemos explorar e melhorar continuamente a tecnologia de modelos em larga escala e contribuir para o desenvolvimento do campo da inteligência artificial. Esperamos que os leitores possam entender profundamente a situação atual e as tendências futuras da Big Model Technology lendo este livro e fornecer orientação e inspiração para sua pesquisa e prática. Vamos trabalhar juntos para promover o desenvolvimento da tecnologia de inteligência artificial e contribuir para a construção de um futuro mais inteligente e sustentável.

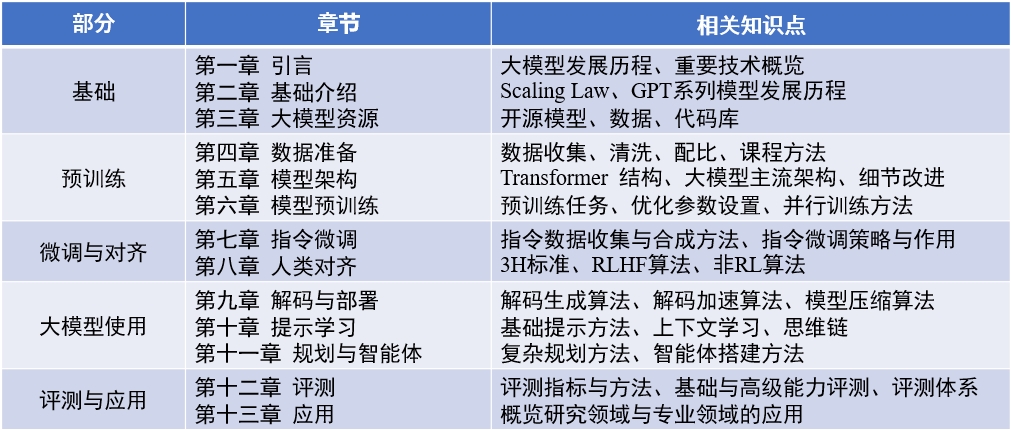
Conteúdo do livro : "Big Language Model" (atualizado 2024-04-15)
Artigo em inglês : llmsurvey
LLMBOX : Biblioteca de Código
Yulan Mockup : Biblioteca de Código
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
A lista das principais pessoas e participantes responsáveis em cada capítulo deste livro é a seguinte:
Além disso, graças a outros alunos que participaram da compilação e revisão deste livro. They (sorted by pinyin) are Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zhibin, Gu Zihui, Guo Geyang, He Dongnan, Hou Xinming, Hu Yiwen, Li Bingqian, Li Chengyuan, Li Ging-yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, Ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Tang Yiru, Wang Jiapeng, Wang Lei, Wang Shuting, Yao Feng, Yin Yanbin, Zhan Yuliang, Zhang Jingsen, Zhang Liang, Zhu Tianyu e Zhu Yutao.
Durante o processo de escrita, este livro foi apoiado pela computação de recursos da plataforma de compartilhamento de instrumentos científicos em larga escala da Universidade Renmin da China. Gostaria de expressar meus sinceros agradecimentos aos três professores Chen Yueguo, Lu Weizheng e Shi Yuan.
A imagem da capa deste livro é gerada por ferramentas de IA e é produzida pela Xu Lanling.
No processo de preparação de livros chineses, lemos extensivamente os papéis clássicos existentes, códigos e livros relacionados, conceitos principais extraídos, algoritmos e modelos convencionais e os organizamos e os introduzimos sistematicamente. Revisamos o primeiro rascunho de cada capítulo muitas vezes, esforçando -se para esclarecer e expressões precisas. No entanto, durante o processo de escrita, sentimos profundamente as limitações de nossas próprias habilidades e conhecimentos. Embora tenhamos feito grandes esforços, inevitavelmente haverá omissões ou pontos inadequados. A primeira edição deste livro é apenas um ponto de partida. Planejamos continuar atualizando e melhorando o conteúdo on -line, e recebemos especialmente os leitores para fazer críticas e sugestões valiosas. Também agradeceremos aos leitores que fazem sugestões valiosas no site ao mesmo tempo. Consideramos o processo de escrever este livro como nosso próprio processo de aprendizado e também esperamos ter uma comunicação aprofundada com os leitores através deste livro e aprender com mais colegas do setor.
If you have any comments, comments, and suggestions (first confirm whether the latest version has been corrected), please provide feedback through GitHub's Issues page, or email it to the author's email address batmanfly at qq.com , lijunyi at ruc.edu.cn , francis_kun_zhou at ruc.edu.cn , steventianyitang at outlook.com .


