LLMBook zh.github.io
1.0.0
Autor: Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
Ende 2022 wurde Chatgpt schockierend gestartet, und die großsprachige Modelltechnologie "fegte" schnell die gesamte Gesellschaft, und die künstliche Intelligenztechnologie hat einen wichtigen Fortschritt eingeleitet. Angesichts der leistungsstarken Leistung großer Sprachmodelle können wir nicht anders, als zu fragen: Was genau ist die Technologie hinter diesen Modellen? Diese Frage ist für viele wissenschaftliche Forscher zweifellos zum Schwerpunkt des Denkens geworden. Es muss darauf hingewiesen werden, dass die große Modelltechnologie nicht über Nacht erreicht wird. Seine Entwicklungsgeschichte hat nacheinander mehrere Entwicklungsstadien wie statistische Sprachmodelle, neuronale Netzwerksprachenmodelle und vorgebreitete Sprachmodelle erlebt. Jeder Entwicklungsschritt hat die Bemühungen und Erfolge vieler wissenschaftlicher Forscher verdichtet. Als wichtiger Promoter der großsprachigen Modelltechnologie hat OpenAI eine große Anzahl technischer Details in der Vergangenheit untersucht und schließlich die GPT -Serie von Modellen auf den Markt gebracht, was diesen technologischen Wandel leitete.
Seit GPT-3 hat das OpenAI-Team jedoch selten relevante technische Details in öffentlichen Materialien erwähnt, und viele technische Berichte führen hauptsächlich überprüfliche Inhalte ein. Bisher ist die Kerntechnologie über das Modell der GPT -Serie immer noch schwer zu entschlüsseln. Derzeit besteht die größte Herausforderung für die akademische Gemeinschaft darin, dass es nur sehr wenige Teams mit ausreichenden Ressourcen gibt, um das Modell der Großsprachen vollständig zu erforschen, was zu mangelnden Erfahrungen aus erster Hand und Schwierigkeiten bei der direkten Durchführung der verwandten Forschung führt. Ein großes Modelltraining beinhaltet viele Schulungsdetails, die häufig nicht direkt aus vorhandenen wissenschaftlichen Forschungsarbeiten erhalten werden. Aufgrund seiner zahlreichen Parameter, komplexen Komponenten und des relativ komplexen Trainingsprozesses können frühe experimentelle Erkundungen zu einer exponentiellen Zunahme der Anzahl der Experimente führen, wenn kein Vorwissen eingeführt wird. Dies macht es besonders schwierig, die Erfahrung der großen Modelltechnologie zu beherrschen, ganz zu schweigen von der Erforschung verwandter wissenschaftlicher Forschungsprobleme von Grund auf neu, wobei die Rolle der akademischen Gemeinschaft in dieser künstlichen Welle stark einschränkt. Gegenwärtig werden Großsprachenmodelle mit starken Fähigkeiten im Grunde genommen aus der Branche abgeleitet, und dieser Trend kann im Laufe der Zeit offensichtlicher werden. "Know-how" ist sehr wichtig für wissenschaftliche Forscher aus erster Hand. Nur wenn wir den Kern der Technologie kennenlernen, können wir wirklich verstehen, welche Probleme sinnvoll sind und Lösungen finden.
Es ist erfreulich, dass die Menschen nach und nach die Bedeutung von "Offenheit" sowohl in der Wissenschaft als auch in der Industrie erkannt haben und immer mehr öffentliche Grundmodelle, technische Codes und akademische Papiere sehen können, die die "Transparenz" der großen Modelltechnologie effektiv fördert. Nur durch Offenheit und Teilen können wir die Weisheit aller Menschheit sammeln und gemeinsam die Entwicklung der Technologie für künstliche Intelligenz fördern. Tatsächlich ist nach vorhandenen öffentlichen Informationen auch die Big-Model-Technologie "mit Regeln zu befolgen", wie z. B. allgemeine Schulungsprozesse, Datenreinigungsmethoden, Unterrichtsfeineinstellungstechnologie, Algorithmen zur Ausrichtung der menschlichen Präferenzausrichtungen usw. Gemäß diesen Technologien haben diese Technologien mithilfe der Berechnung von Ressourcen, Ressourcen, F & E-Personal in der Lage, den Gesamtschulungsprozess des Großmodells relativ ordnungsgemäß und erzielte gute Modellergebnisse zu vervollständigen. Mit der Enthüllung und Öffnung von mehr Kerntechnologien wird die "Transparenz" der großmodellischen Technologie weiter verbessert.
Kurz gesagt, die großmodellische Technologie befindet sich in einer Phase der schnellen Entwicklung, und Grundprinzipien müssen untersucht werden und die Schlüsseltechnologien müssen verbessert werden. Für wissenschaftliche Forscher ist die Forschungsarbeit von Big Model voller Vorstellungskraft und faszinierend. Angesichts des kontinuierlichen Fortschritts und des Teilens und der Eröffnung von Technologie haben wir Grund zu der Annahme, dass künstliche Intelligenztechnologie in Zukunft größere Fortschritte erzielen und in weiteren Bereichen einen stärkeren Einfluss haben wird. Dieses Buch zielt darauf ab, den Lesern ein umfassendes Verständnis der großen Modelltechnologie zu vermitteln, einschließlich der Grundprinzipien, Schlüsseltechnologien und Anwendungsaussichten. Durch eingehende Forschung und Praxis können wir die groß angelegte Modelltechnologie kontinuierlich erforschen und verbessern und zur Entwicklung des Bereichs der künstlichen Intelligenz beitragen. Wir hoffen, dass die Leser die aktuelle Situation und die zukünftigen Trends der Big Model -Technologie durch das Lesen dieses Buches zutiefst verstehen und Anleitung und Inspiration für ihre Forschung und Praxis bieten können. Lassen Sie uns zusammenarbeiten, um die Entwicklung der Technologie für künstliche Intelligenz zu fördern und zum Aufbau einer intelligenteren und nachhaltigeren Zukunft beizutragen.

Inhalt des Buches : "Big Language Model" (aktualisiert 2024-04-15)
Englisch Review Paper : LLMSURVEY
LLMBox : Codebibliothek
Yulan Mockup : Code Library
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
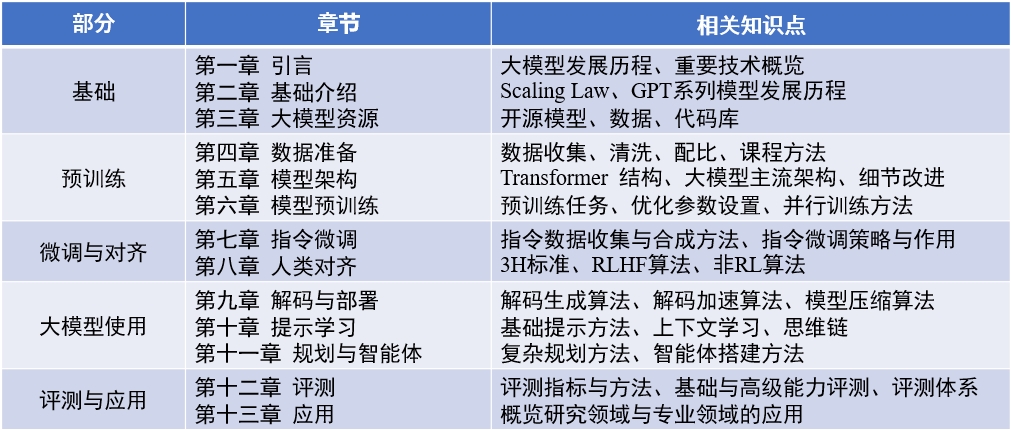
Die Liste der wichtigsten verantwortlichen Personen und Teilnehmer in jedem Kapitel dieses Buches lautet wie folgt:
Dank anderer Schüler, die an der Zusammenstellung und Korrekturlesen dieses Buches teilgenommen haben. They (sorted by pinyin) are Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zhibin, Gu Zihui, Guo Geyang, He Dongnan, Hou Xinming, Hu Yiwen, Li Bingqian, Li Chengyuan, Li Ging-yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, Ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Tang Yiru, Wang Jiapeng, Wang Lei, Wang Shuting, Yao Feng, Yin Yanbin, Zhan Yuliang, Zhang Jingsen, Zhang Liang, Zhu Tianyu und Zhu Yutao.
Während des Schreibprozesses wurde dieses Buch durch Berechnung von Ressourcen der groß angelegten wissenschaftlichen Instrumenten-Sharing-Plattform der Renmin der Universität China unterstützt. Ich möchte den drei Lehrern Chen YueGuo, Lu Weisheng und Shi Yuan aufrichtig ausdrücken.
Das Titelbild dieses Buches wird von KI -Tools erzeugt und von Xu Lanling erzeugt.
Während der Vorbereitung chinesischer Bücher lesen wir die vorhandenen klassischen Artikel, verwandten Codes und Lehrbücher ausführlich, extrahierten Kernkonzepte, Mainstream -Algorithmen und -modelle und organisierten und stellten sie systematisch vor. Wir haben den ersten Entwurf jedes Kapitels viele Male überarbeitet und bemüht, genaue Ausdrücke zu klären und zu klären. Während des Schreibprozesses spüren wir jedoch die Grenzen unserer eigenen Fähigkeiten und Kenntnisse. Obwohl wir große Anstrengungen unternommen haben, wird es unweigerlich Auslassungen oder unangemessene Punkte geben. Die erste Ausgabe dieses Buches ist nur ein Ausgangspunkt. Wir planen, die Inhalte weiterhin online zu aktualisieren und zu verbessern, und begrüßen insbesondere die Leser, um wertvolle Kritik und Vorschläge zu machen. Wir werden auch Lesern danken, die gleichzeitig wertvolle Vorschläge auf der Website machen. Wir betrachten den Prozess des Schreibens dieses Buches als unseren eigenen Lernprozess und hoffen auch, dass wir durch dieses Buch eingehende Kommunikation mit den Lesern haben und von weiteren Branchenkollegen lernen.
Wenn Sie Kommentare, Kommentare und Vorschläge haben (zuerst bestätigen, ob die neueste Version korrigiert wurde), geben Sie bitte Feedback über Githubs Ausgabenseite oder senden Sie sie per E -Mail an die E -Mail -Adresse des Autors Batmanfly bei qq.com , lijunyi unter ruc.edu.cn , francis_kun_zhou unter ruc.edu.cn , steventianyitang .


