LLMBook zh.github.io
1.0.0
著者:Zhao Xin、Li Junyi、Zhou Kun、Tang Tianyi、Wen Jirong
2022年の終わりに、ChatGptは衝撃的に開始され、大規模な言語モデルテクノロジーは社会全体をすぐに「席巻」し、人工知能技術は重要な進歩を遂げました。大規模な言語モデルの強力なパフォーマンスに直面して、私たちは尋ねずにはいられません。これらのモデルの背後にあるテクノロジーは何ですか?この質問は間違いなく多くの科学研究者にとって考えることの焦点になっています。大きなモデルテクノロジーは一晩では達成されていないことを指摘する必要があります。その開発履歴は、統計言語モデル、ニューラルネットワーク言語モデル、事前に訓練された言語モデルなどの複数の開発段階を連続して経験してきました。開発の各ステップは、多くの科学研究者の努力と成果を凝縮しました。大規模な言語モデルテクノロジーの重要なプロモーターとして、Openaiは過去に関連する多数の技術的詳細を調査し、最終的にGPTシリーズのモデルを開始し、この技術的変化をリードしました。
ただし、GPT-3以来、Openaiチームは公共資料に関連する技術的詳細についてめったに言及しておらず、多くの技術レポートが主にレビュー関連のコンテンツを導入しています。これまでのところ、GPTシリーズモデルに関するコアテクノロジーを完全に復号化することは依然として困難です。現在、学術コミュニティが直面している主要な課題は、大規模な言語モデルトレーニングを完全に探索するのに十分なリソースを持つチームが非常に少ないことです。大規模なモデルトレーニングには、多くのトレーニングの詳細が含まれます。これには、既存の科学研究論文から直接取得されないことがよくあります。多数のパラメーター、複雑なコンポーネント、および比較的複雑なトレーニングプロセスにより、初期の実験的探索は、事前知識が導入されていない場合、実験数の指数関数的な増加につながる可能性があります。これにより、関連する科学研究の問題をゼロから探索することは言うまでもなく、この人工波で学術コミュニティが果たす役割を大幅に制限することは言うまでもなく、大きなモデルテクノロジーの経験を習得することが特に困難になります。現在、強力な能力を備えた大規模な言語モデルは基本的に業界から派生しており、この傾向は時間とともにより明白になる可能性があります。 「ノウハウ」は、科学研究者にとって直接の経験から非常に重要です。テクノロジーの核心を知ることによってのみ、どの問題が意味のあるかを本当に理解し、解決策を見つけることができます。
人々が学界と産業の両方において「開放性」の重要性を徐々に実現し、より多くの公共の基本モデル、技術コード、学術論文を見ることができることは嬉しいです。開放性と共有を通してのみ、すべての人類の知恵を集め、人工知能技術の開発を共同で促進することができます。実際、既存の公開情報によれば、ビッグモデルテクノロジーは、全体的なトレーニングプロセス、データクリーニング方法、命令微調整技術、人間の好みの調整アルゴリズムなど、「従うべきルールを備えています」。これらのテクノロジーによると、R&D担当者は、大きなモデルの全体的なトレーニングプロセスを比較的円滑に達成し、良いモデルの結果を達成することができました。より多くのコアテクノロジーの公開と開放により、大規模なモデルテクノロジーの「透明性」がさらに改善されます。
要するに、大規模なモデル技術は急速な発展の段階にあり、基本原則を調査する必要があり、重要な技術を改善する必要があります。科学研究者にとって、大きなモデル研究作業は想像力と魅力的なものに満ちています。継続的な進歩とテクノロジーの共有と開放により、人工知能技術が将来より大きな進歩を遂げ、より多くの分野でより大きな影響を与えると信じる理由があります。この本の目的は、基本原則、主要なテクノロジー、アプリケーションの見通しなど、読者に大きなモデルテクノロジーを包括的に理解することを目指しています。詳細な研究と実践を通じて、大規模なモデル技術を継続的に調査および改善し、人工知能の分野の開発に貢献できます。読者がこの本を読むことで、大きなモデルテクノロジーの現在の状況と将来の傾向を深く理解し、研究と実践のためのガイダンスとインスピレーションを提供できることを願っています。人工知能技術の開発を促進するために協力し、よりスマートでより持続可能な未来の構築に貢献しましょう。

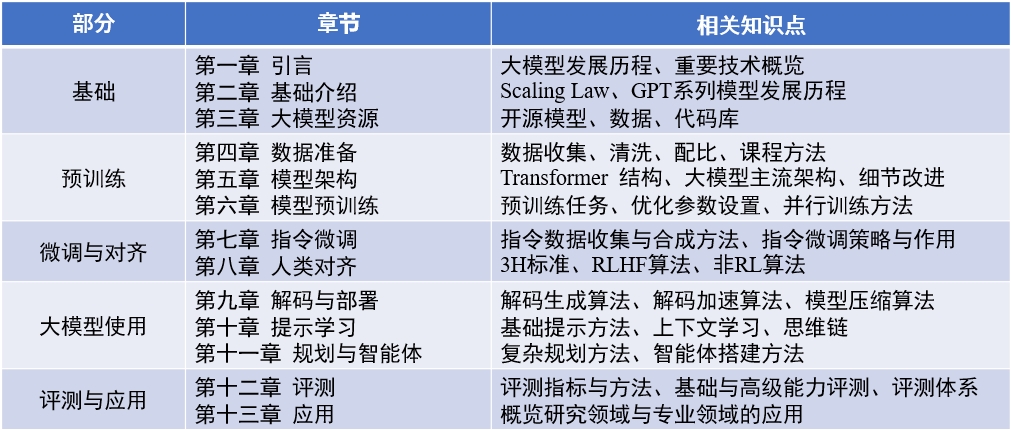
本の内容: 「ビッグ言語モデル」 (2024-04-15更新)
英語レビューペーパー:llmsurvey
LLMBOX :コードライブラリ
Yulan Mockup :コードライブラリ
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
この本の各章の主な責任者と参加者のリストは次のとおりです。
また、この本の編集と校正に参加した他の学生に感謝します。彼ら(ピニインによってソートされた)は、カオチアン、カオ・ザンシュオ、チェン・ジー、チェン・ジアヤキ、ダイ・スンハオ、デン・シン、ディン・イジー、フェン・シュアヤン、ガオ・ゼフェン、グー・ズヒビン、グザイフイ、グー・ジェヤン、hu Xinming、hou fu yienan Chengyuan、Li Ging-Yuan、Liu Enze、Liu Jiongnan、Liu Zihan、Luo Wenyang、Mei Lang、Ou Keshan、Peng Han、Ruan Kai、Su Weihang、Sun Yiding、Tang Yiru、Wang Jiapeng、Wang Lei、wanジンセン、チャン・リアン、Zhu Tianyu、Zhu Yutao。
執筆プロセス中、この本は、中国のRenmin Universityの大規模な科学機器共有プラットフォームからリソースを計算することによってサポートされていました。 3人の教師のチェン・ユエグオ、ルー・ワイゼン、シュイアンに感謝します。
この本のカバー画像は、AIツールによって生成され、Xu Lanlingによって作成されます。
中国の本を準備する過程で、既存の古典的な論文、関連コード、教科書を広範囲に読み、コアコンセプト、主流のアルゴリズムとモデルを抽出し、体系的に整理および導入しました。各章の最初のドラフトを何度も修正し、明確で正確な表現を明確にするよう努めています。しかし、執筆プロセス中に、私たちは自分の能力と知識の限界を深く感じています。私たちは多大な努力をしましたが、必然的に省略または不適切なポイントがあります。この本の初版は出発点にすぎません。私たちはオンラインでコンテンツを更新および改善し続けることを計画しており、特に貴重な批判や提案をする読者を歓迎します。また、ウェブサイトで貴重な提案を同時に行う読者にも感謝します。私たちはこの本を書くプロセスを私たち自身の学習プロセスと見なしており、また、この本を通して読者と深いコミュニケーションを取り、より多くの業界の仲間から学ぶことを望んでいます。
コメント、コメント、提案がある場合(最初に最新バージョンが修正されたかどうかを確認)、GitHubの問題ページを介してフィードバックを提供するか、著者の電子メールアドレスQQ.comのbatmanfly 、 ruc.edu.cnのlijunyi 、 francis_kun_zhouのruc.edu.cn 、 Steventianyitang at Outlook.cnに電子メールを送信してください。


