LLMBook zh.github.io
1.0.0
Author: Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
At the end of 2022, ChatGPT was launched shockingly, and large-language model technology quickly "swept" the entire society, and artificial intelligence technology has ushered in an important progress. Faced with the powerful performance of large language models, we can’t help but ask: What exactly is the technology behind these models? This question has undoubtedly become the focus of thinking for many scientific researchers. It must be pointed out that big model technology is not achieved overnight. Its development history has successively experienced multiple development stages such as statistical language models, neural network language models, and pre-trained language models. Each step of development has condensed the efforts and achievements of many scientific researchers. As an important promoter of large language model technology, OpenAI has explored a large number of technical details related to it in the past and finally launched the GPT series of models, leading this technological change.
However, since GPT-3, the OpenAI team has rarely mentioned relevant technical details in public materials, and many technical reports mainly introduce review-related content. So far, the core technology about the GPT series model is still difficult to fully decrypt. At present, the major challenge facing the academic community is that there are very few teams with sufficient resources to fully explore large language model training, which leads to lack of first-hand experience and difficulty in directly conducting related research. Large model training involves many training details, which are often not directly obtained from existing scientific research papers. Due to its numerous parameters, complex components, and relatively complex training process, early experimental explorations may lead to an exponential increase in the number of experiments if no prior knowledge is introduced. This makes it particularly difficult to master the experience of big model technology, not to mention exploring related scientific research issues from scratch, greatly limiting the role played by the academic community in this artificial wave. At present, large language models with strong capabilities are basically derived from the industry, and this trend may become more obvious over time. "Know-How" is very important for scientific researchers from first-hand experience. Only by getting to know the core of technology can we truly understand which problems are meaningful and find solutions.
It is gratifying that people have gradually realized the importance of "openness" in both academia and industry, and can see more and more public basic models, technical codes and academic papers, which have effectively promoted the "transparency" of big model technology. Only through openness and sharing can we gather the wisdom of all mankind and jointly promote the development of artificial intelligence technology. In fact, according to existing public information, big model technology is also "with rules to follow", such as overall training process, data cleaning methods, instruction fine-tuning technology, human preference alignment algorithms, etc. According to these technologies, with the support of computing resources, R&D personnel have been able to complete the overall training process of the big model relatively smoothly and achieve good model results. With the reveal and opening up of more core technologies, the "transparency" of large-model technology will be further improved.
In short, large-model technology is in a stage of rapid development, and basic principles need to be explored and key technologies need to be improved. For scientific researchers, big model research work is full of imagination and fascinating. With the continuous advancement and sharing and opening up of technology, we have reason to believe that artificial intelligence technology will make greater progress in the future and will have a more profound impact in more fields. This book aims to provide readers with a comprehensive understanding of the big model technology, including its basic principles, key technologies and application prospects. Through in-depth research and practice, we can continuously explore and improve large-scale model technology and contribute to the development of the field of artificial intelligence. We hope that readers can deeply understand the current situation and future trends of big model technology by reading this book, and provide guidance and inspiration for their research and practice. Let us work together to promote the development of artificial intelligence technology and contribute to building a smarter and more sustainable future.

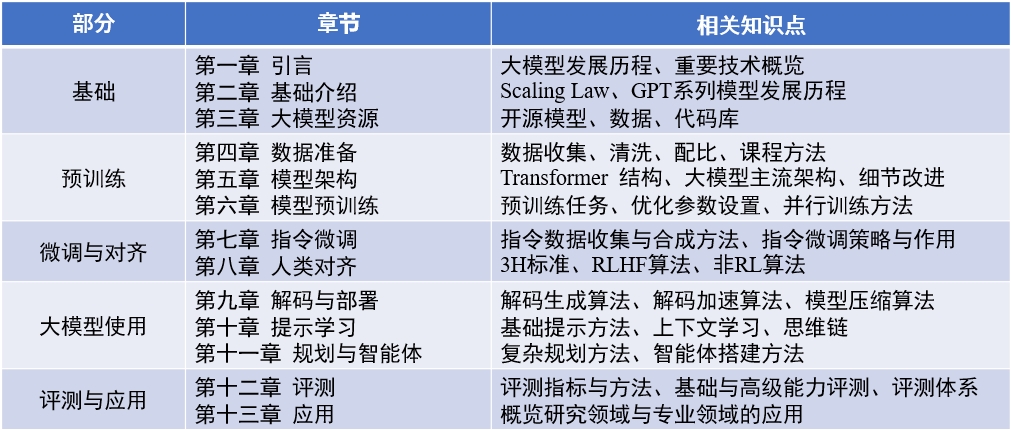
Content of the book : "Big Language Model" (updated 2024-04-15)
English review paper : LLMSurvey
LLMBox : Code library
YuLan Mockup : Code Library
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
The list of the main responsible persons and participants in each chapter of this book is as follows:
Also, thanks to other students who participated in the compilation and proofreading of this book. They (sorted by pinyin) are Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zhibin, Gu Zihui, Guo Geyang, He Dongnan, Hou Xinming, Hu Yiwen, Li Bingqian, Li Chengyuan, Li Ging-yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, Ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Tang Yiru, Wang Jiapeng, Wang Lei, Wang Shuting, Yao Feng, Yin Yanbin, Zhan Yuliang, Zhang Jingsen, Zhang Liang, Zhu Tianyu and Zhu Yutao.
During the writing process, this book was supported by computing resources from the large-scale scientific instrument sharing platform of Renmin University of China. I would like to express my sincere thanks to the three teachers Chen Yueguo, Lu Weizheng and Shi Yuan.
The cover image of this book is generated by AI tools and is produced by Xu Lanling.
In the process of preparing Chinese books, we read extensively the existing classic papers, related codes and textbooks, extracted core concepts, mainstream algorithms and models, and organized and introduced them systematically. We have revised the first draft of each chapter many times, striving to clarify and accurate expressions. However, during the writing process, we deeply feel the limitations of our own abilities and knowledge. Although we have made great efforts, there will inevitably be omissions or inappropriate points. The first edition of this book is only a starting point. We plan to continue to update and improve the content online, and we especially welcome readers to make valuable criticisms and suggestions. We will also give thanks to readers who make valuable suggestions on the website at the same time. We regard the process of writing this book as our own learning process, and we also hope to have in-depth communication with readers through this book and learn from more industry peers.
If you have any comments, comments, and suggestions (first confirm whether the latest version has been corrected), please provide feedback through GitHub's Issues page, or email it to the author's email address batmanfly at qq.com , lijunyi at ruc.edu.cn , francis_kun_zhou at ruc.edu.cn , steventianyitang at outlook.com .


