LLMBook zh.github.io
1.0.0
Autor: Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
A finales de 2022, ChatGPT se lanzó sorprendentemente, y la tecnología modelo de gran lenguaje "barrió" a toda la sociedad, y la tecnología de inteligencia artificial ha marcado el comienzo de un progreso importante. Ante el poderoso rendimiento de los modelos de idiomas grandes, no podemos evitar preguntar: ¿Cuál es exactamente la tecnología detrás de estos modelos? Esta pregunta, sin duda, se ha convertido en el foco de pensamiento para muchos investigadores científicos. Debe señalarse que la tecnología de modelo grande no se logra de la noche a la mañana. Su historial de desarrollo ha experimentado sucesivamente múltiples etapas de desarrollo, como modelos de lenguaje estadístico, modelos de lenguaje de redes neuronales y modelos de lenguaje previamente capacitados. Cada paso de desarrollo ha condensado los esfuerzos y logros de muchos investigadores científicos. Como un promotor importante de la tecnología de modelos de lenguaje grande, OpenAI ha explorado una gran cantidad de detalles técnicos relacionados en el pasado y finalmente lanzó la serie de modelos GPT, liderando este cambio tecnológico.
Sin embargo, desde GPT-3, el equipo de Operai rara vez ha mencionado detalles técnicos relevantes en materiales públicos, y muchos informes técnicos introducen principalmente contenido relacionado con la revisión. Hasta ahora, la tecnología central sobre el modelo de la serie GPT sigue siendo difícil de descifrar completamente. En la actualidad, el principal desafío que enfrenta la comunidad académica es que hay muy pocos equipos con recursos suficientes para explorar completamente la capacitación de modelos de idiomas grandes, lo que lleva a la falta de experiencia de primera mano y dificultad para realizar directamente investigaciones relacionadas. La capacitación en modelo grande implica muchos detalles de capacitación, que a menudo no se obtienen directamente de los trabajos de investigación científicos existentes. Debido a sus numerosos parámetros, componentes complejos y un proceso de entrenamiento relativamente complejo, las exploraciones experimentales tempranas pueden conducir a un aumento exponencial en el número de experimentos si no se introducen conocimientos previos. Esto hace que sea particularmente difícil dominar la experiencia de la tecnología de los grandes modelos, sin mencionar la exploración de los problemas de investigación científica relacionados desde cero, lo que limita en gran medida el papel desempeñado por la comunidad académica en esta ola artificial. En la actualidad, los modelos de idiomas grandes con fuertes capacidades se derivan básicamente de la industria, y esta tendencia puede ser más obvia con el tiempo. "Know-how" es muy importante para los investigadores científicos de la experiencia de primera mano. Solo al conocer el núcleo de la tecnología podemos entender realmente qué problemas son significativos y encontrar soluciones.
Es gratificante que las personas se hayan dado cuenta gradualmente de la importancia de la "apertura" tanto en la academia como en la industria, y puedan ver más y más modelos básicos públicos, códigos técnicos y documentos académicos, que han promovido efectivamente la "transparencia" de la tecnología de modelos grandes. Solo a través de la apertura y el intercambio podemos reunir la sabiduría de toda la humanidad y promover conjuntamente el desarrollo de la tecnología de inteligencia artificial. De hecho, de acuerdo con la información pública existente, la tecnología de modelos de grandes también es "con reglas a seguir", como el proceso general de capacitación, los métodos de limpieza de datos, la tecnología de ajuste de instrucción, los algoritmos de alineación de preferencias humanas, etc. de acuerdo con estas tecnologías, con el soporte de recursos informáticos, el personal de I + D ha podido completar el proceso de entrenamiento general del modelo grande relativamente suavemente y lograr los buenos resultados del modelo. Con la revelación y la apertura de más tecnologías centrales, la "transparencia" de la tecnología de modelos grandes mejorará aún más.
En resumen, la tecnología de modelos grandes se encuentra en una etapa de desarrollo rápido, y deben explorarse los principios básicos y las tecnologías clave deben mejorarse. Para los investigadores científicos, el trabajo de investigación de grandes modelos está lleno de imaginación y fascinante. Con el avance continuo y el intercambio y la apertura de la tecnología, tenemos razones para creer que la tecnología de inteligencia artificial hará un mayor progreso en el futuro y tendrá un impacto más profundo en más campos. Este libro tiene como objetivo proporcionar a los lectores una comprensión integral de la gran tecnología de modelos, incluidos sus principios básicos, tecnologías clave y perspectivas de aplicaciones. A través de una investigación y práctica en profundidad, podemos explorar continuamente y mejorar la tecnología modelo a gran escala y contribuir al desarrollo del campo de la inteligencia artificial. Esperamos que los lectores puedan comprender profundamente la situación actual y las tendencias futuras de la gran tecnología de modelos al leer este libro y proporcionar orientación e inspiración para su investigación y práctica. Trabajemos juntos para promover el desarrollo de la tecnología de inteligencia artificial y contribuir a construir un futuro más inteligente y sostenible.

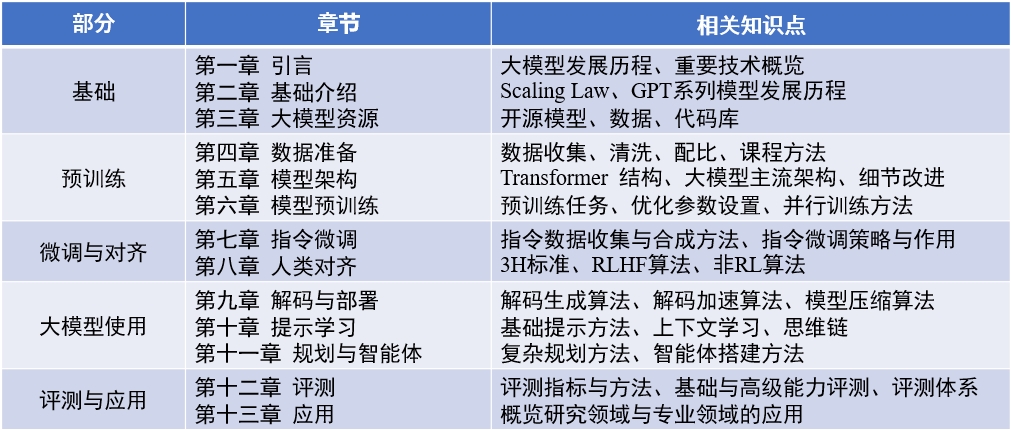
Contenido del libro : "Big Language Model" (actualizado 2024-04-15)
Documento de revisión en inglés : Llmsurvey
LLMBOX : Biblioteca de códigos
Maqueta de Yulan : biblioteca de códigos
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
La lista de las principales personas y participantes responsables en cada capítulo de este libro es la siguiente:
Además, gracias a otros estudiantes que participaron en la compilación y la revisión de este libro. They (sorted by pinyin) are Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zhibin, Gu Zihui, Guo Geyang, He Dongnan, Hou Xinming, Hu Yiwen, Li Bingqian, Li Chengyuan, Li Ging-yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, Ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Tang Yiru, Wang Jiapeng, Wang Lei, Wang Waling, Yao Feng, Yin Yinbin, Zhang, Zhang, Zhang, Zang, Zang, Zang, Yin Yinbin, Zhang, Zhang, Zhang, Zang, Zang, Wang, Yin Yinbin, Zhang, Zhang, Zhang, Zang, Zang, Yin Yinbin, Zhang, Zhang, Zang, Zang, zhang, zhanger Jingsen, Zhang Liang, Zhu Tianyu y Zhu Yutao.
Durante el proceso de escritura, este libro fue respaldado por la computación de los recursos de la plataforma de intercambio de instrumentos científicos a gran escala de la Universidad Renmin de China. Me gustaría expresar mi sincero agradecimiento a los tres maestros Chen Yueguo, Lu Weizheng y Shi Yuan.
La imagen de portada de este libro es generada por AI Tools y es producida por Xu Lanling.
En el proceso de preparación de libros chinos, leemos ampliamente los documentos clásicos existentes, códigos y libros de texto relacionados, los conceptos centrales extraídos, algoritmos y modelos convencionales, y los organizamos e introdujeron sistemáticamente. Hemos revisado el primer borrador de cada capítulo muchas veces, luchando por aclarar y expresiones precisas. Sin embargo, durante el proceso de escritura, sentimos profundamente las limitaciones de nuestras propias habilidades y conocimientos. Aunque hemos hecho grandes esfuerzos, inevitablemente habrá omisiones o puntos inapropiados. La primera edición de este libro es solo un punto de partida. Planeamos continuar actualizando y mejorando el contenido en línea, y damos la bienvenida especialmente a los lectores para hacer valiosas críticas y sugerencias. También daremos gracias a los lectores que hacen sugerencias valiosas en el sitio web al mismo tiempo. Consideramos el proceso de escribir este libro como nuestro propio proceso de aprendizaje, y también esperamos tener una comunicación profunda con los lectores a través de este libro y aprender de más compañeros de la industria.
Si tiene algún comentario, comentario y sugerencia (confirme primero si la última versión ha sido corregida), proporcione comentarios a través de la página de problemas de GitHub, o envíelo por correo electrónico a la dirección de correo electrónico del autor Batmanfly en QQ.com , Lijunyii en Ruc.edu.cn , francis_kun_zhou en Ruc.edu.cn , Steventianyitang en Outlook.com .


