LLMBook zh.github.io
1.0.0
Auteur: Zhao Xin, Li Junyi, Zhou Kun, Tang Tianyi, Wen Jirong
À la fin de 2022, Chatgpt a été lancé choquant et la technologie du modèle à grande langue a rapidement "balayé" toute la société, et la technologie de l'intelligence artificielle a inauguré un progrès important. Face aux performances puissantes des modèles de grands langues, nous ne pouvons pas nous empêcher de demander: quelle est exactement la technologie derrière ces modèles? Cette question est sans aucun doute devenue l'objectif de la réflexion pour de nombreux chercheurs scientifiques. Il faut souligner que la technologie des grands modèles n'est pas réalisée du jour au lendemain. Son histoire de développement a succédé successivement à plusieurs étapes de développement telles que les modèles de langage statistique, les modèles de langage de réseau neuronal et les modèles de langage pré-formés. Chaque étape de développement a condensé les efforts et les réalisations de nombreux chercheurs scientifiques. En tant que promoteur important de la technologie des modèles de grande langue, OpenAI a exploré un grand nombre de détails techniques liés à celle-ci dans le passé et a finalement lancé la série de modèles GPT, menant ce changement technologique.
Cependant, depuis GPT-3, l'équipe OpenAI a rarement mentionné les détails techniques pertinents dans le matériel public, et de nombreux rapports techniques introduisent principalement le contenu lié à la révision. Jusqu'à présent, la technologie de base sur le modèle de la série GPT est toujours difficile à décrypter complètement. À l'heure actuelle, le principal défi auquel sont confrontés la communauté académique est qu'il existe très peu d'équipes ayant suffisamment de ressources pour explorer pleinement la formation de modèles de langues, ce qui entraîne un manque d'expérience de première main et de difficulté à mener directement des recherches connexes. La formation en grande partie implique de nombreux détails de formation, qui ne sont souvent pas directement obtenus à partir de documents de recherche scientifique existants. En raison de ses nombreux paramètres, composants complexes et processus de formation relativement complexe, des explorations expérimentales précoces peuvent entraîner une augmentation exponentielle du nombre d'expériences si aucune connaissance préalable n'est introduite. Il est particulièrement difficile de maîtriser l'expérience de la technologie des grands modèles, sans parler de l'exploration des problèmes de recherche scientifique connexes à partir de zéro, limitant considérablement le rôle joué par la communauté académique dans cette vague artificielle. À l'heure actuelle, les grands modèles de langue avec des capacités solides sont essentiellement dérivés de l'industrie, et cette tendance peut devenir plus évidente au fil du temps. Le "savoir-faire" est très important pour les chercheurs scientifiques de l'expérience de première main. Ce n'est qu'en apprenant à connaître le cœur de la technologie que nous pouvons vraiment comprendre quels problèmes sont significatifs et trouver des solutions.
Il est gratifiant que les gens aient progressivement réalisé l'importance de "l'ouverture" dans le monde universitaire et l'industrie, et peuvent voir de plus en plus de modèles de base, de codes techniques et de documents universitaires, qui ont effectivement favorisé la "transparence" de la technologie des grands modèles. Ce n'est que par l'ouverture et le partage que nous pouvons rassembler la sagesse de toute l'humanité et promouvoir conjointement le développement de la technologie de l'intelligence artificielle. En fait, selon les informations publiques existantes, la technologie des grands modèles est également "avec des règles à suivre", telles que le processus de formation global, les méthodes de nettoyage des données, la technologie de réglage fin des instructions, les algorithmes d'alignement des préférences humaines, etc. Selon ces technologies, avec le soutien des ressources informatiques, le personnel de la R&D a été en mesure de terminer le processus de formation global du grand modèle en douceur et d'atteindre les résultats du modèle bon. Avec la révélation et l'ouverture de plus de technologies de base, la «transparence» de la technologie à grand modèle sera encore améliorée.
En bref, la technologie à grand modèle est à un stade de développement rapide et les principes de base doivent être explorés et les technologies clés doivent être améliorées. Pour les chercheurs scientifiques, les travaux de recherche de gros modèles sont pleins d'imagination et fascinant. Avec le progrès continu et le partage et l'ouverture de la technologie, nous avons des raisons de croire que la technologie de l'intelligence artificielle fera de plus grandes progrès à l'avenir et aura un impact plus profond dans plus de domaines. Ce livre vise à fournir aux lecteurs une compréhension complète de la technologie des grands modèles, y compris ses principes de base, ses technologies clés et ses prospects d'application. Grâce à des recherches et une pratique approfondies, nous pouvons continuellement explorer et améliorer la technologie des modèles à grande échelle et contribuer au développement du domaine de l'intelligence artificielle. Nous espérons que les lecteurs pourront profondément comprendre la situation actuelle et les tendances futures de la technologie des grands modèles en lisant ce livre et fournir des conseils et une inspiration pour leur recherche et leur pratique. Travaillons ensemble pour promouvoir le développement de la technologie de l'intelligence artificielle et contribuer à la construction d'un avenir plus intelligent et plus durable.

Contenu du livre : "Big Language Model" (mis à jour 2024-04-15)
Document de révision en anglais : llmsurvey
Llmbox : bibliothèque de code
Yulan Mockup : Bibliothèque de code
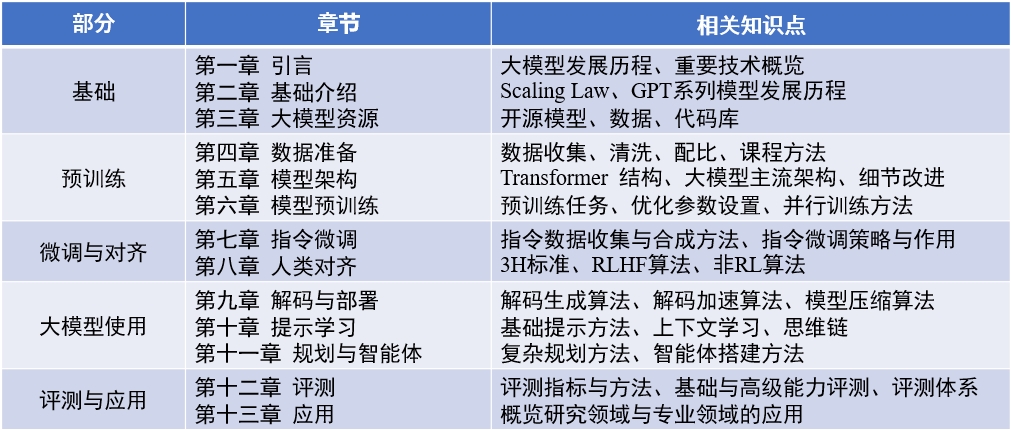
赵鑫,李军毅,周昆,唐天一,文继荣,大语言模型,https://llmbook-zh.github.io/,2024.
@book{LLMBook,
title = {大语言模型},
year = {2024},
author = {赵鑫, 李军毅, 周昆, 唐天一, 文继荣},
address = {北京},
url = {https://llmbook-zh.github.io/},
}
La liste des principales personnes responsables et participants dans chaque chapitre de ce livre est la suivante:
De plus, grâce à d'autres étudiants qui ont participé à la compilation et à la relecture de ce livre. Ils (triés par Pinyin) sont Cao Qian, Cao Zhanshuo, Chen Jie, Cheng Jiayaqi, Dai Sunhao, Deng Xin, Ding Yijie, Feng Xueyang, Gao Zefeng, Gou Zhibin, Gu Zihui, Guo Geyang, He Dongnan, hou xinming, Hu yiwen, li binkin, li, hou xinming, hu yiwen, li binquqan, hou xinming, hu yiwen, li binquqan, hou xinming Chengyuan, Li ging-yuan, Liu Enze, Liu Jiongnan, Liu Zihan, Luo Wenyang, Mei Lang, ou Keshan, Peng Han, Ruan Kai, Su Weihang, Sun Yiding, Tang Yiru, Wang Jiapeng, Wang Lei, Wang Shoting, Yao Feng, Yin Yanbin, Zhan Yuliang, Zhan Jingsen, Zhang Liang, Zhu Tianyu et Zhu Yutao.
Au cours du processus d'écriture, ce livre a été soutenu par les ressources informatiques de la plate-forme de partage d'instruments scientifiques à grande échelle de l'Université Renmin de Chine. Je voudrais exprimer mes sincères remerciements aux trois professeurs Chen Yueguo, Lu Weizheng et Shi Yuan.
L'image de couverture de ce livre est générée par les outils AI et est produite par Xu Lanling.
Dans le processus de préparation des livres chinois, nous lisons largement les articles classiques existants, les codes et les manuels connexes, les concepts de base extraits, les algorithmes et modèles traditionnels, et les avons organisés et introduits systématiquement. Nous avons révisé plusieurs fois la première ébauche de chaque chapitre, nous nous efforçant de clarifier et des expressions précises. Cependant, pendant le processus d'écriture, nous ressentons profondément les limites de nos propres capacités et connaissances. Bien que nous ayons fait de grands efforts, il y aura inévitablement des omissions ou des points inappropriés. La première édition de ce livre n'est qu'un point de départ. Nous prévoyons de continuer à mettre à jour et à améliorer le contenu en ligne, et nous accueillons particulièrement les lecteurs à faire de précieuses critiques et suggestions. Nous remercierons également les lecteurs qui font de précieux suggestions sur le site Web en même temps. Nous considérons le processus d'écriture de ce livre comme notre propre processus d'apprentissage, et nous espérons également avoir une communication approfondie avec les lecteurs à travers ce livre et apprendre de plus de pairs de l'industrie.
Si vous avez des commentaires, des commentaires et des suggestions (confirmez d'abord si la dernière version a été corrigée), veuillez fournir des commentaires via la page des problèmes de Github ou l'envoyer par e-mail à l'adresse e-mail de l'auteur Batmanfly à QQ.com , Lijunyi à Ruc.edu.cn , Francis_kun_zhou à Ruc.edu.cn , Steentianyitang à Outlook.com .


