deepdoctection
v.0.37.3

Deep Doctection เป็นไลบรารี Python ที่จัดทำการแยกเอกสารและงานวิเคราะห์เค้าโครงเอกสารโดยใช้แบบจำลองการเรียนรู้ลึก มันไม่ได้ใช้โมเดล แต่ช่วยให้คุณสามารถสร้างท่อโดยใช้ไลบรารีที่ได้รับการยอมรับอย่างสูงสำหรับการตรวจจับวัตถุ OCR และงาน NLP ที่เลือกและให้เฟรมเวิร์กแบบบูรณาการสำหรับการปรับแต่งการประเมินและการวิ่ง สำหรับงานการประมวลผลข้อความที่เฉพาะเจาะจงมากขึ้นใช้หนึ่งในห้องสมุด NLP ที่ยอดเยี่ยมอื่น ๆ อีกมากมาย
Deep Doctection มุ่งเน้นไปที่การใช้งานและทำขึ้นสำหรับผู้ที่ต้องการแก้ไขปัญหาในโลกแห่งความเป็นจริงที่เกี่ยวข้องกับการสกัดเอกสารจาก PDF หรือสแกนในรูปแบบภาพต่างๆ
ตรวจสอบการสาธิตของการวิเคราะห์เค้าโครงเอกสารด้วย OCR บน: กอด: กอดพื้นที่ใบหน้า
Deep Doctection ให้แบบจำลองของห้องสมุดที่รองรับสำหรับงานต่าง ๆ ที่จะรวมเข้ากับท่อ ฟังก์ชั่นหลักของมันไม่ได้ขึ้นอยู่กับห้องสมุดการเรียนรู้ลึกใด ๆ ที่เฉพาะเจาะจง รุ่นที่เลือกสำหรับงานต่อไปนี้ได้รับการสนับสนุนในขณะนี้:
Deep Doctection ให้วิธีการด้านบนของวิธีการสำหรับการประมวลผลอินพุตล่วงหน้าไปยังรุ่นเช่นการปลูกพืชหรือการปรับขนาดและผลลัพธ์หลังกระบวนการเช่นการตรวจสอบผลลัพธ์ที่ซ้ำกัน, คำที่เกี่ยวข้องกับคำที่ตรวจพบเซ็กเมนต์หรือคำสั่งซื้อเป็นข้อความที่ต่อเนื่องกัน คุณจะได้รับผลลัพธ์ในรูปแบบ JSON ที่คุณสามารถปรับแต่งได้ด้วยตัวเอง
ดู สมุดบันทึกแนะนำ ในสมุดบันทึกเพื่อเริ่มต้นได้ง่าย
ตรวจสอบ บันทึกประจำรุ่น สำหรับการอัปเดตล่าสุด
Deep Doctection หรือ Libraries สนับสนุนให้รุ่นที่ผ่านการฝึกอบรมมาก่อนซึ่งอยู่ในกรณีส่วนใหญ่ที่มีอยู่ที่ Hugging Face Model Hub หรือที่จะดาวน์โหลดโดยอัตโนมัติเมื่อมีการร้องขอ ตัวอย่างเช่นคุณสามารถค้นหาแบบจำลองการตรวจจับวัตถุที่ผ่านการฝึกอบรมมาก่อนจากเฟรมเวิร์ก Tensorpack หรือ Detectron2 สำหรับการวิเคราะห์เค้าโครงหยาบการตรวจจับเซลล์ตารางและการจดจำตาราง
การฝึกอบรมเป็นส่วนสำคัญในการเตรียมท่อให้พร้อมในโดเมนเฉพาะบางอย่างปล่อยให้มันเป็นการวิเคราะห์เค้าโครงเอกสารการจำแนกเอกสารหรือ NER Deep Doctection ให้สคริปต์การฝึกอบรมสำหรับแบบจำลองที่อยู่บนพื้นฐานของผู้ฝึกสอนที่พัฒนาจากห้องสมุดที่โฮสต์รหัสรุ่น ยิ่งไปกว่านั้น DEEP Doctection Host Code สำหรับชุดข้อมูลที่จัดตั้งขึ้นอย่างดีเช่น PublayNet ที่ทำให้ง่ายต่อการทดลอง นอกจากนี้ยังมีการแมปจากรูปแบบข้อมูลที่ใช้กันอย่างแพร่หลายเช่น Coco และมีเฟรมเวิร์กชุดข้อมูล (คล้ายกับ ชุดข้อมูล เพื่อให้การตั้งค่าการฝึกอบรมในชุดข้อมูลที่กำหนดเองกลายเป็นเรื่องง่ายมาก โน้ตบุ๊กนี้ แสดงวิธีการทำเช่นนี้
Deep Doctection มาพร้อมกับกรอบการทำงานที่ช่วยให้คุณประเมินการคาดการณ์ของแบบจำลองเดียวหรือหลายรุ่นในไปป์ไลน์กับความจริงพื้นฐานบางอย่าง ตรวจสอบอีกครั้ง ที่นี่ ว่าทำอย่างไร
การตั้งค่าไปป์ไลน์จะต้องใช้รหัสสองสามบรรทัดในการสร้างอินสแตนซ์ไปป์ไลน์และหลังจากการวนรอบสำหรับทุกหน้าจะถูกประมวลผลผ่านไปป์ไลน์
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

มี เอกสาร มากมายที่มีอยู่ในบทเรียนแนวคิดการออกแบบและ API เราต้องการนำเสนอสิ่งต่าง ๆ อย่างครอบคลุมและเข้าใจได้มากที่สุด อย่างไรก็ตามเราทราบว่ายังมีอีกหลายพื้นที่ที่สามารถปรับปรุงได้อย่างมีนัยสำคัญในแง่ของความชัดเจนไวยากรณ์และความถูกต้อง เราหวังว่าจะได้คำใบ้และความคิดเห็นทุกครั้งที่เพิ่มคุณภาพของเอกสาร
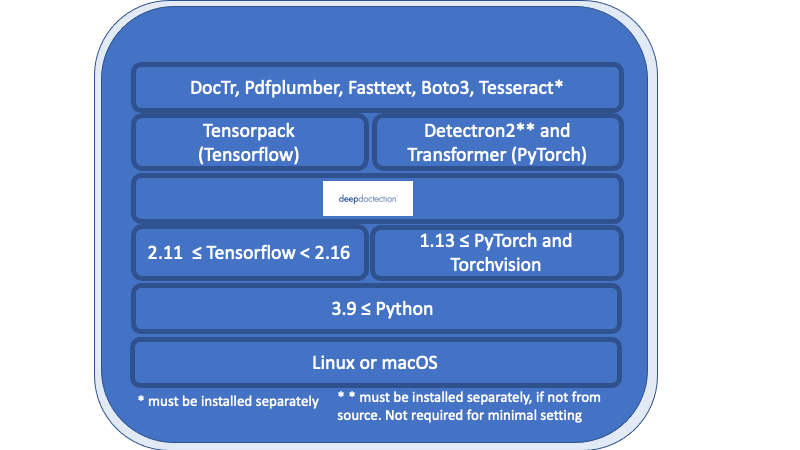
ทุกอย่างในภาพรวมที่ระบุไว้ด้านล่างชั้นแพทย์ ลึก เป็นข้อกำหนดที่จำเป็นและต้องติดตั้งแยกต่างหาก
Linux หรือ MacOS (ไม่รองรับ Windows แต่มี DockerFile ให้บริการ)
Python> = 3.9
1.13 <= pytorch หรือ 2.11 <= tensorflow <2.16 (สำหรับรุ่น Tensorflow ที่ต่ำกว่ารหัสจะทำงานบน GPU เท่านั้น) โดยทั่วไปหากคุณต้องการฝึกอบรมหรือปรับแต่งแบบจำลองจำเป็นต้องใช้ GPU
ด้วยความเคารพต่อกรอบการเรียนรู้อย่างลึกซึ้งคุณต้องตัดสินใจระหว่าง Tensorflow และ Pytorch
เครื่องยนต์ Tesseract OCR จะถูกใช้ผ่านเสื้อคลุม Python ต้องติดตั้งเอ็นจิ้นหลักแยกต่างหาก
สำหรับการเปิดตัว v.0.34.0 และด้านล่าง Deep Doctection ใช้ wrappers Python สำหรับ Poppler เพื่อแปลงเอกสาร PDF เป็นรูปภาพ สำหรับ Release v.0.35.0 การพึ่งพานี้จะเป็นทางเลือก
ภาพรวมต่อไปนี้แสดงความพร้อมใช้งานของโมเดลร่วมกับเฟรมเวิร์ก DL
| งาน | pytorch | คลังแสง | เทนเซอร์โฟลว์ |
|---|---|---|---|
| การตรวจจับเค้าโครงผ่าน Detectron2/Tensorpack | ✅ (CPU เท่านั้น) | ✅ (GPU เท่านั้น) | |
| การจดจำตารางผ่าน Detectron2/Tensorpack | ✅ (CPU เท่านั้น) | ✅ (GPU เท่านั้น) | |
| โต๊ะหม้อแปลงผ่านหม้อแปลง | |||
| DOCTR | |||
| layoutlm (v1, v2, v3, xlm) ผ่านหม้อแปลง |
เราขอแนะนำให้ใช้สภาพแวดล้อมเสมือนจริง คุณสามารถติดตั้งแพ็คเกจผ่าน PIP หรือจากแหล่งที่มา
หาก คุณต้องการเริ่มต้นด้วยการตั้งค่าขั้นต่ำ (เช่นการใช้ตัววิเคราะห์ Deep Doctect
pip install deepdoctection
หากคุณต้องการใช้เฟรมเวิร์ก TensorFlow โปรดติดตั้ง TensorPack แยกกัน Detectron2 จะไม่ได้รับการติดตั้งและรูปแบบการจดจำรูปแบบ/ การจดจำตารางจะทำงานด้วย Torchscript บน CPU
การติดตั้งต่อไปนี้จะช่วยให้คุณทุกรุ่นที่มีอยู่ในกรอบการเรียนรู้ลึกรวมถึงทุกรุ่นที่เป็นอิสระจาก TensorFlow/Pytorch โปรดทราบว่าการพึ่งพานั้นซับซ้อนมาก เราพยายามอย่างหนักเพื่อให้ข้อกำหนดทันสมัยอยู่เสมอ
สำหรับ tensorflow วิ่ง
pip install deepdoctection[tf]
สำหรับ Pytorch
การติดตั้งครั้งแรก Detectron2 แยกต่างหากเนื่องจากไม่ได้กระจายผ่าน PYPI ตรวจสอบคำแนะนำที่นี่ จากนั้นวิ่ง
pip install deepdoctection[pt]
สิ่งนี้จะติดตั้งแพทย์ ลึก ด้วยการพึ่งพาทั้งหมดที่ระบุไว้เหนือชั้นแพทย์ ลึก ใช้การตั้งค่านี้หากคุณต้องการเริ่มต้นหรือต้องการสำรวจคุณสมบัติทั้งหมด
หากคุณต้องการควบคุมมากขึ้นด้วยการติดตั้งของคุณและกำลังมองหาการพึ่งพาน้อยลงให้ติดตั้ง DEEP DOCTECTION ด้วยการตั้งค่าพื้นฐานเท่านั้น
pip install deepdoctection
สิ่งนี้จะไม่สนใจไลบรารีโมเดลทั้งหมด (เลเยอร์เหนือชั้นแพทย์ ลึก ในแผนภาพ) และคุณจะต้องรับผิดชอบในการติดตั้งด้วยตัวเอง โปรดทราบว่าคุณจะไม่สามารถเรียกใช้ไปป์ไลน์ใด ๆ ด้วยการตั้งค่านี้
สำหรับข้อมูลเพิ่มเติมโปรดปรึกษา คำแนะนำการติดตั้งเต็มรูปแบบ
ดาวน์โหลดที่เก็บหรือโคลนผ่าน
git clone https://github.com/deepdoctection/deepdoctection.git
ในการเริ่มต้นด้วย tensorflow , Run:
cd deepdoctection
pip install ".[tf]"
การติดตั้งการตั้ง ค่า pytorch แบบเต็มจากแหล่งที่มาจะติดตั้ง detectron2 สำหรับคุณ:
cd deepdoctection
pip install ".[source-pt]"
เริ่มต้นจาก release v.0.27.0 ภาพนักเทียบท่าที่มีอยู่แล้วสามารถดาวน์โหลดได้จาก Docker Hub
docker pull deepdoctection/deepdoctection:<release_tag>
ในการเริ่มต้นคอนเทนเนอร์คุณสามารถใช้ไฟล์ Docker Compose ./docker/pytorch-gpu/docker-compose.yaml ในไฟล์ .env ให้ระบุไดเรกทอรีโฮสต์ที่ควรเก็บแคชของ Deep Doctection ไดเรกทอรีนี้จะติดตั้ง นอกจากนี้ให้ระบุไดเรกทอรีการทำงานเพื่อติดตั้งไฟล์เพื่อประมวลผลลงในคอนเทนเนอร์
docker compose up -d
จะเริ่มคอนเทนเนอร์
เราขอขอบคุณห้องสมุดทุกแห่งที่ให้รหัสคุณภาพสูงและรุ่นที่ผ่านการฝึกอบรมมาก่อน หากปราศจากมันคงเป็นไปไม่ได้ที่จะพัฒนากรอบนี้
เราพยายามอย่างหนักที่จะกำจัดข้อบกพร่อง เรารู้ด้วยว่ารหัสไม่ได้เป็นปัญหา เรายินดีต้อนรับทุกประเด็นที่เกี่ยวข้องกับ repo นี้และพยายามที่จะจัดการกับพวกเขาโดยเร็วที่สุด การแก้ไขข้อผิดพลาดหรือการปรับปรุงจะถูกปรับใช้ในรุ่นใหม่ทุก 10 ถึง 12 สัปดาห์
... คุณสามารถสนับสนุนโครงการได้อย่างง่ายดายโดยทำให้มองเห็นได้มากขึ้น การออกจากดาราหรือคำแนะนำจะช่วยได้
แจกจ่ายภายใต้ใบอนุญาต Apache 2.0 ตรวจสอบใบอนุญาตสำหรับข้อมูลเพิ่มเติม


