deepdoctection
v.0.37.3

Deep Doctection adalah perpustakaan Python yang mengatur ekstraksi dokumen dan tugas analisis tata letak dokumen menggunakan model pembelajaran yang mendalam. Itu tidak mengimplementasikan model tetapi memungkinkan Anda untuk membangun jaringan pipa menggunakan perpustakaan yang sangat diakui untuk deteksi objek, OCR dan tugas NLP yang dipilih dan menyediakan kerangka kerja terintegrasi untuk menyempurnakan, mengevaluasi, dan menjalankan model. Untuk tugas pemrosesan teks yang lebih spesifik, gunakan salah satu dari banyak perpustakaan NLP hebat lainnya.
Deep Doctection berfokus pada aplikasi dan dibuat untuk mereka yang ingin menyelesaikan masalah dunia nyata yang terkait dengan ekstraksi dokumen dari PDF atau pemindaian dalam berbagai format gambar.
Periksa demo pipa analisis tata letak dokumen dengan OCR pada: pelukan: memeluk ruang wajah .
Deep Doctection menyediakan pembungkus model perpustakaan yang didukung untuk berbagai tugas untuk diintegrasikan ke dalam jaringan pipa. Fungsi intinya tidak tergantung pada perpustakaan pembelajaran mendalam tertentu. Model terpilih untuk tugas -tugas berikut saat ini didukung:
Deep Doctection menyediakan di atas metode tersebut untuk input pra-pemrosesan ke model seperti pemangkasan atau pengubah ukuran dan untuk hasil pasca-proses, seperti memvalidasi output duplikat, mengaitkan kata-kata dengan segmen tata letak yang terdeteksi atau memesan kata ke dalam teks yang berdekatan. Anda akan mendapatkan output dalam format JSON yang dapat Anda sesuaikan lebih jauh sendiri.
Lihatlah buku catatan pengantar dalam repo notebook untuk awal yang mudah.
Periksa catatan rilis untuk pembaruan terbaru.
Deep Doctection atau pustaka dukungannya menyediakan model pra-terlatih yang ada di sebagian besar kasus yang tersedia di hub Model Face Hugging atau yang akan secara otomatis diunduh setelah diminta. Misalnya, Anda dapat menemukan model deteksi objek pra-terlatih dari kerangka Tensorpack atau Detectron2 untuk analisis tata letak kasar, deteksi sel tabel dan pengenalan tabel.
Pelatihan adalah bagian substansial untuk menyiapkan saluran pipa pada beberapa domain tertentu, biarkan itu menjadi analisis tata letak dokumen, klasifikasi dokumen atau NER. Deep Doctection menyediakan skrip pelatihan untuk model yang didasarkan pada pelatih yang dikembangkan dari perpustakaan yang meng -host kode model. Selain itu, Deep Doctection Hosts Code ke beberapa set data yang mapan seperti Publaynet yang membuatnya mudah bereksperimen. Ini juga berisi pemetaan dari format data yang banyak digunakan seperti Coco dan memiliki kerangka kerja dataset (mirip dengan set data sehingga pengaturan pelatihan pada dataset khusus menjadi sangat mudah. Buku catatan ini menunjukkan kepada Anda bagaimana melakukan ini.
Deep Doctection dilengkapi dengan kerangka kerja yang memungkinkan Anda untuk mengevaluasi prediksi model tunggal atau ganda dalam pipa terhadap beberapa kebenaran dasar. Periksa lagi di sini bagaimana hal itu dilakukan.
Setelah menyiapkan pipa, Anda membawa beberapa baris kode untuk membuat instantiate pipa dan setelah loop untuk semua halaman akan diproses melalui pipa.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

Ada dokumentasi luas yang tersedia yang berisi tutorial, konsep desain dan API. Kami ingin menyajikan hal -hal sebesar mungkin dan dapat dimengerti. Namun, kami sadar bahwa masih ada banyak bidang di mana perbaikan yang signifikan dapat dilakukan dalam hal kejelasan, tata bahasa dan kebenaran. Kami menantikan setiap petunjuk dan komentar yang meningkatkan kualitas dokumentasi.
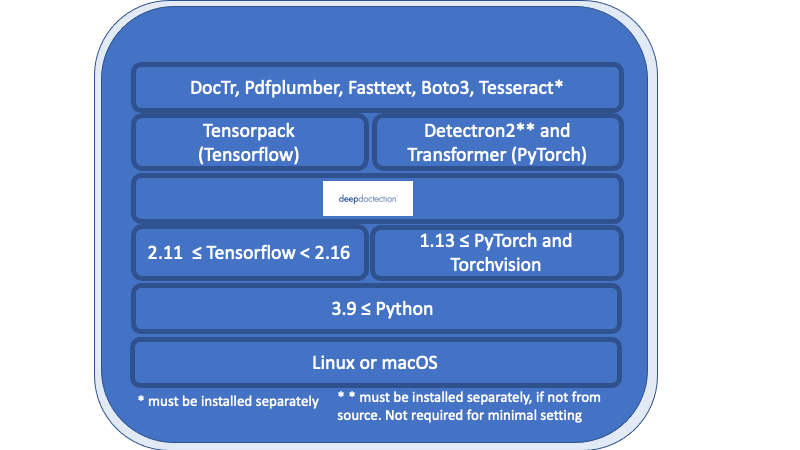
Segala sesuatu dalam ikhtisar yang tercantum di bawah lapisan Dokter yang dalam adalah persyaratan yang diperlukan dan harus dipasang secara terpisah.
Linux atau MacOS. (Windows tidak didukung tetapi ada dockerfile yang tersedia)
Python> = 3.9
1.13 <= pytorch atau 2.11 <= TensorFlow <2.16. (Untuk versi TensorFlow yang lebih rendah Kode ini hanya akan berjalan pada GPU). Secara umum, jika Anda ingin melatih atau menyempurnakan model, diperlukan GPU.
Sehubungan dengan kerangka pembelajaran yang mendalam, Anda harus memutuskan antara TensorFlow dan Pytorch.
Mesin Tesseract OCR akan digunakan melalui pembungkus ular surut. Mesin inti harus dipasang secara terpisah.
Untuk rilis v.0.34.0 dan di bawah Deptection Deep menggunakan pembungkus python untuk poppler untuk mengubah dokumen PDF menjadi gambar. Untuk rilis v.0.35.0 ketergantungan ini akan opsional.
Tinjauan berikut menunjukkan ketersediaan model bersamaan dengan kerangka kerja DL.
| Tugas | Pytorch | Torchscript | Tensorflow |
|---|---|---|---|
| Deteksi tata letak melalui detectron2/tenorpack | ✅ | ✅ (CPU saja) | ✅ (hanya GPU) |
| Pengenalan tabel melalui detectron2/tensorpack | ✅ | ✅ (CPU saja) | ✅ (hanya GPU) |
| Transformator tabel melalui transformator | ✅ | ||
| Doktr | ✅ | ✅ | |
| Layoutlm (V1, V2, V3, XLM) Via Transformers | ✅ |
Kami merekomendasikan menggunakan lingkungan virtual. Anda dapat menginstal paket melalui PIP atau dari sumber.
Jika Anda ingin memulai dengan pengaturan minimal (misalnya menjalankan penganalisa dokter yang dalam dengan konfigurasi default atau mencoba 'Mulai Notebook'), pasang Dokter yang dalam dengan
pip install deepdoctection
Jika Anda ingin menggunakan kerangka TensorFlow, silakan instal Tensorpack secara terpisah. Detectron2 tidak akan diinstal dan model tata letak/ model pengenalan tabel akan berjalan dengan Torchscript pada CPU.
Instalasi berikut akan memberi Anda semua model yang tersedia dalam kerangka pembelajaran yang mendalam serta semua model yang tidak tergantung pada TensorFlow/Pytorch. Harap dicatat, bahwa dependensi sangat kompleks. Kami berusaha keras untuk menjaga agar persyaratan tetap mutakhir.
Untuk TensorFlow , jalankan
pip install deepdoctection[tf]
Untuk pytorch ,
First Instal Detectron2 secara terpisah karena tidak didistribusikan melalui PYPI. Periksa instruksi di sini. Lalu jalankan
pip install deepdoctection[pt]
Ini akan memasang Dokter yang dalam dengan semua dependensi yang tercantum di atas lapisan Dokter yang dalam . Gunakan pengaturan ini, jika Anda ingin memulai atau ingin menjelajahi semua fitur.
Jika Anda ingin memiliki lebih banyak kontrol dengan instalasi Anda dan mencari lebih sedikit dependensi, lalu pasang Deptectect Dept Doctection dengan pengaturan dasar saja.
pip install deepdoctection
Ini akan mengabaikan semua perpustakaan model (lapisan di atas lapisan dokter dalam dalam diagram) dan Anda akan bertanggung jawab untuk menginstalnya sendiri. Perhatikan, bahwa Anda tidak akan dapat menjalankan pipa apa pun dengan pengaturan ini.
Untuk informasi lebih lanjut, silakan berkonsultasi dengan instruksi instalasi lengkap .
Unduh repositori atau klon melalui
git clone https://github.com/deepdoctection/deepdoctection.git
Untuk memulai dengan TensorFlow , jalankan:
cd deepdoctection
pip install ".[tf]"
Menginstal pengaturan PyTorch lengkap dari Source juga akan menginstal Detectron2 untuk Anda:
cd deepdoctection
pip install ".[source-pt]"
Mulai dari rilis v.0.27.0 , gambar Docker yang sudah ada sebelumnya dapat diunduh dari hub Docker.
docker pull deepdoctection/deepdoctection:<release_tag>
Untuk memulai wadah, Anda dapat menggunakan file Docker Compose ./docker/pytorch-gpu/docker-compose.yaml . Dalam file .env yang disediakan, tentukan direktori host di mana cache yang dalam harus disimpan. Direktori ini akan dipasang. Selain itu, tentukan direktori yang berfungsi untuk memasang file yang akan diproses ke dalam wadah.
docker compose up -d
akan memulai wadah.
Kami berterima kasih kepada semua perpustakaan yang menyediakan kode berkualitas tinggi dan model pra-terlatih. Tanpa, tidak mungkin untuk mengembangkan kerangka kerja ini.
Kami berusaha keras untuk menghilangkan bug. Kami juga tahu bahwa kode tersebut tidak bebas dari masalah. Kami menyambut semua masalah yang relevan dengan repo ini dan mencoba mengatasinya secepat mungkin. Perbaikan atau peningkatan bug akan digunakan dalam rilis baru setiap 10 hingga 12 minggu.
... Anda dapat dengan mudah mendukung proyek dengan membuatnya lebih terlihat. Meninggalkan bintang atau rekomendasi akan membantu.
Didistribusikan di bawah lisensi Apache 2.0. Periksa lisensi untuk informasi tambahan.


