deepdoctection
v.0.37.3

Глубокая документация - это библиотека Python, которая организует задачи извлечения документов и анализ макета документов с использованием моделей глубокого обучения. Он не реализует модели, но позволяет создавать трубопроводы, используя высоко признанные библиотеки для обнаружения объектов, OCR и выбранных задач NLP и обеспечивает интегрированную структуру для точной настройки, оценки и запуска моделей. Для более конкретных задач обработки текста используйте одну из многих других великих библиотек NLP.
Deep Doctection фокусируется на приложениях и предназначена для тех, кто хочет решить проблемы реального мира, связанные с извлечением документов из PDFS или сканирования в различных форматах изображений.
Проверьте демонстрацию конвейера анализа макета документа с OCR на: объятия: обнимающие пространства для лица .
Deep Doctection предоставляет модельные обертки поддерживаемых библиотек для различных задач, которые должны быть интегрированы в трубопроводы. Его основная функция не зависит от какой -либо конкретной библиотеки глубокого обучения. В настоящее время поддерживаются выбранные модели для следующих задач:
Глубокая документация обеспечивает в дополнение к этим методам предварительной обработки входов для таких моделей, как обрезка или изменение размера, и результаты после обработки, такие как проверка дублирующих выходов, связывание слов с обнаруженными сегментами макета или упорядочению слов в смежный текст. Вы получите результат в формате JSON, который вы можете настроить еще дальше сами.
Посмотрите на вводной ноутбук в записной книжке для легкого старта.
Проверьте заметки о выпуске для недавних обновлений.
Глубокая документация или его библиотеки поддержки предоставляют предварительно обученные модели, которые находятся в большинстве случаев, доступных в модели Hug Face Face , или которые будут автоматически загружены после запроса. Например, вы можете найти предварительно обученные модели обнаружения объектов из рамки Tensorpack или Detectron2 для анализа грубых макетов, обнаружения таблиц и распознавания таблицы.
Обучение является существенной частью для подготовки трубопроводов в какой -то конкретной области, пусть он будет анализом макета документов, классификацией документов или NER. Deep Doctection предоставляет тренировочные сценарии для моделей, основанных на тренерах, разработанных из библиотеки, которая размещает код модели. Более того, код Deep Doctection Code для некоторых хорошо установленных наборов данных, таких как Publaynet , которые позволяют легко экспериментировать. Он также содержит сопоставления из широко используемых форматов данных, таких как Coco, и имеет структуру набора данных (сродни наборам данных , так что настройка обучения на пользовательском наборе данных становится очень простым. В этом ноутбуке показано, как это сделать.
Глубокая документация оснащена рамкой, которая позволяет оценивать прогнозы единых или нескольких моделей в трубопроводе против какой -то наземной истины. Проверьте еще раз, как это делается.
Установив трубопровод, вам понадобится несколько строк кода для создания трубопровода и после цикла для цикла, все страницы будут обрабатываться через трубопровод.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

Существует обширная документация , содержащая учебные пособия, концепции дизайна и API. Мы хотим представить вещи максимально и понятно, насколько это возможно. Тем не менее, мы знаем, что есть еще много областей, где можно сделать значительные улучшения с точки зрения ясности, грамматики и правильности. Мы с нетерпением ждем каждого подсказки и комментариев, которые повышают качество документации.
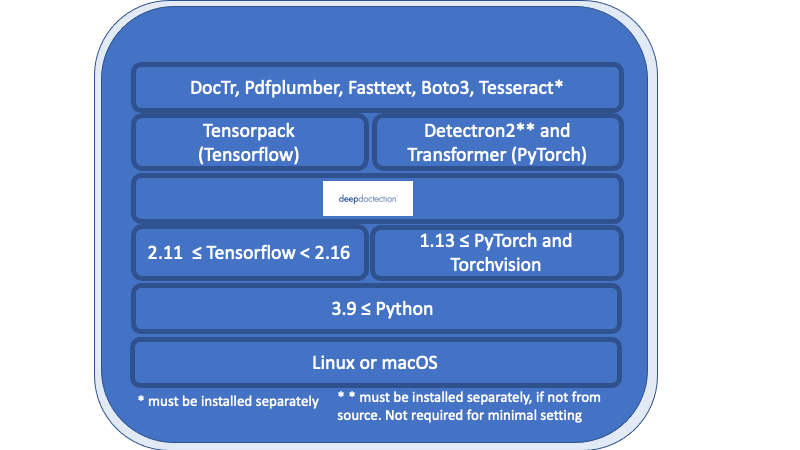
Все в обзоре, перечисленном ниже глубокого уровня документа, является необходимым требованием и должно быть установлено отдельно.
Linux или macOS. (Windows не поддерживается, но есть Dockerfile)
Python> = 3,9
1.13 <= pytorch или 2,11 <= tensorflow <2,16. (Для более низких версий TensorFlow код будет работать только на GPU). В общем, если вы хотите тренировать или настраивать модели, требуется графический процессор.
Что касается глубокого обучения, вы должны выбрать между Tensorflow и Pytorch.
Двигатель Tesseract OCR будет использоваться через обертку Python. Двигатель банального двигателя должен быть установлен отдельно.
Для выпуска v.0.34.0 и ниже Deep Doctection использует Python Frappers для Poppler для преобразования документов PDF в изображения. Для выпуска v.0.35.0 эта зависимость будет необязательной.
Следующий обзор показывает доступность моделей в сочетании с структурой DL.
| Задача | Пирог | TorchScript | Tensorflow |
|---|---|---|---|
| Обнаружение макета через Detectron2/Tensorpack | ✅ | ✅ (только процессор) | ✅ (только GPU) |
| Распознавание таблицы через Detectron2/Tensorpack | ✅ | ✅ (только процессор) | ✅ (только GPU) |
| Трансформатор таблицы через трансформаторы | ✅ | ||
| Доктр | ✅ | ✅ | |
| Layoutlm (V1, V2, V3, XLM) через трансформаторы | ✅ |
Мы рекомендуем использовать виртуальную среду. Вы можете установить пакет через PIP или из источника.
Если вы хотите начать с минимальной настройки (например, запустив анализ Deep Doctection с конфигурацией по умолчанию или попробовать «Начало ноутбука»), установите Deep Doctection с
pip install deepdoctection
Если вы хотите использовать структуру TensorFlow, пожалуйста, установите Tensorpack отдельно. Detectron2 не будет установлен, а модели макета/ модели распознавания таблиц будут работать с TorchScript на процессоре.
Следующая установка даст вам все модели, доступные в рамках глубокого обучения, а также все модели, которые не зависят от Tensorflow/Pytorch. Обратите внимание, что зависимости очень сложны. Мы изо всех сил стараемся держать требования в курсе.
Для TensorFlow , бегите
pip install deepdoctection[tf]
Для Pytorch ,
Сначала установите Detectron2 отдельно, так как он не распространяется через PYPI. Проверьте инструкцию здесь. Затем беги
pip install deepdoctection[pt]
Это установит глубокую документацию со всеми зависимостями, перечисленными выше глубокого уровня документации. Используйте эту настройку, если вы хотите начать или хотите изучить все функции.
Если вы хотите иметь больше управления с вашей установкой и ищете меньше зависимостей, установите Deep Dopection только с базовой настройкой.
pip install deepdoctection
Это будет игнорировать все библиотеки моделей (слои выше глубокого уровня документации на диаграмме), и вы будете нести ответственность за установку их самостоятельно. Обратите внимание, что вы не сможете запустить какой -либо трубопровод с этой настройкой.
Для получения дополнительной информации, пожалуйста, проконсультируйтесь с полными инструкциями по установке .
Загрузите репозиторий или клон через
git clone https://github.com/deepdoctection/deepdoctection.git
Чтобы начать с TensorFlow , беги:
cd deepdoctection
pip install ".[tf]"
Установка полной настройки Pytorch из Source также установит Detectron2 для вас:
cd deepdoctection
pip install ".[source-pt]"
Начиная с выпуска v.0.27.0 , ранее существовавшие изображения Docker можно загрузить из Docker Hub.
docker pull deepdoctection/deepdoctection:<release_tag>
Чтобы запустить контейнер, вы можете использовать файл Docker Compose ./docker/pytorch-gpu/docker-compose.yaml . В предоставленном .env . Этот каталог будет установлен. Кроме того, укажите рабочий каталог для монтажа файлов, которые будут обработаны в контейнер.
docker compose up -d
Начнем контейнер.
Мы благодарим все библиотеки, которые предоставляют высококачественный код и предварительно обученные модели. Без, было бы невозможно разработать эту структуру.
Мы изо всех сил стараемся устранить ошибки. Мы также знаем, что код не свободен от проблем. Мы приветствуем все вопросы, имеющие отношение к этому репо и стараемся решить их как можно быстрее. Исправление или усовершенствования ошибок будут развернуты в новом выпуске каждые 10-12 недель.
... Вы можете легко поддержать проект, сделав его более заметным. Оставление звезды или рекомендация поможет.
Распределено по лицензии Apache 2.0. Проверьте лицензию на получение дополнительной информации.


