deepdoctection
v.0.37.3

Deep Doctction est une bibliothèque Python qui orchestre les tâches d'extraction de documents et d'analyse de mise en page de documents à l'aide de modèles d'apprentissage en profondeur. Il n'implémente pas de modèles mais vous permet de créer des pipelines à l'aide de bibliothèques très reconnues pour la détection d'objets, l'OCR et les tâches NLP sélectionnées et fournit un cadre intégré pour le réglage fin, l'évaluation et l'exécution de modèles. Pour des tâches de traitement de texte plus spécifiques, utilisez l'une des nombreuses autres grandes bibliothèques NLP.
Deep Doctction se concentre sur les applications et est conçu pour ceux qui souhaitent résoudre des problèmes réels liés à l'extraction de documents à partir de PDF ou de scans dans divers formats d'images.
Vérifiez la démo d'un pipeline d'analyse de disposition de documents avec OCR sur: HUGS: Emballage Face Spaces .
Deep Doctction fournit des emballages modèles de bibliothèques prises en charge pour que diverses tâches soient intégrées dans les pipelines. Sa fonction principale ne dépend pas d'une bibliothèque d'apprentissage en profondeur spécifique. Les modèles sélectionnés pour les tâches suivants sont actuellement pris en charge:
Deep Doctction fournit en plus de ces méthodes de prétraitement des entrées à des modèles tels que la culture ou le redimensionnement et les résultats post-processus, comme valider les sorties en double, reliant les mots aux segments de mise en page détectés ou en ordonnant des mots dans du texte contigu. Vous obtiendrez une sortie au format JSON que vous pourrez personnaliser encore plus par vous-même.
Jetez un œil au cahier d'introduction dans le référentiel du cahier pour un démarrage facile.
Vérifiez les notes de publication pour les mises à jour récentes.
Deep Doctction ou ses bibliothèques de support fournissent des modèles pré-formés qui figurent dans la plupart des cas disponibles au Hugging Face Model Hub ou qui seront automatiquement téléchargés une fois demandés. Par exemple, vous pouvez trouver des modèles de détection d'objets pré-formés à partir du cadre TensorPack ou Detectron2 pour l'analyse de mise en page grossière, la détection des cellules de table et la reconnaissance du tableau.
La formation est une partie substantielle pour préparer les pipelines sur un domaine spécifique, que ce soit une analyse de mise en page, une classification des documents ou un NER. Deep Doctction fournit des scripts de formation pour les modèles basés sur des formateurs développés à partir de la bibliothèque qui héberge le code du modèle. De plus, Deep Doctction héberge le code à certains ensembles de données bien établis comme PublayNet qui facilite l'expérimentation. Il contient également des mappages à partir de formats de données largement utilisés comme CoCo et il a un cadre de jeu de données (semblable à des ensembles de données afin que la mise en place de la formation sur un ensemble de données personnalisé devienne très facile. Ce carnet vous montre comment procéder.
Deep Doctction est équipé d'un cadre qui vous permet d'évaluer les prédictions d'un modèle unique ou multiple dans un pipeline contre une vérité au sol. Vérifiez ici comment cela se fait.
Après avoir configuré un pipeline, il vous faut quelques lignes de code pour instancier le pipeline et après une boucle pour toutes les pages sera traitée via le pipeline.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
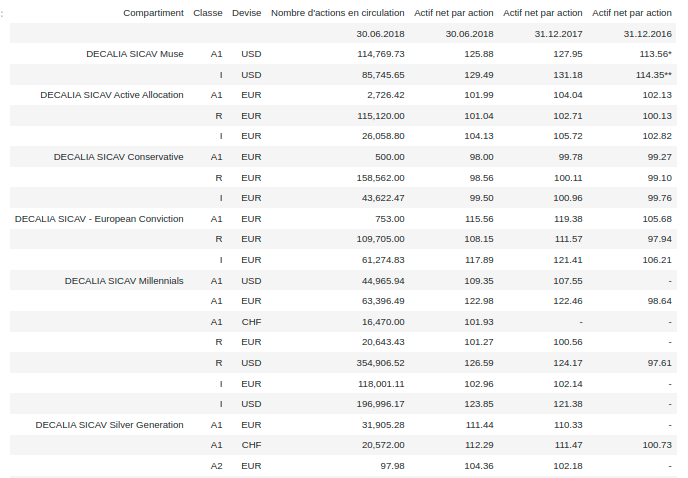
print(page.text)

Il existe une documentation approfondie contenant des tutoriels, des concepts de conception et l'API. Nous voulons présenter des choses aussi de manière complète et compréhensible que possible. Cependant, nous sommes conscients qu'il existe encore de nombreux domaines où des améliorations significatives peuvent être apportées en termes de clarté, de grammaire et d'exactitude. Nous attendons avec impatience chaque indice et commentaire qui augmente la qualité de la documentation.
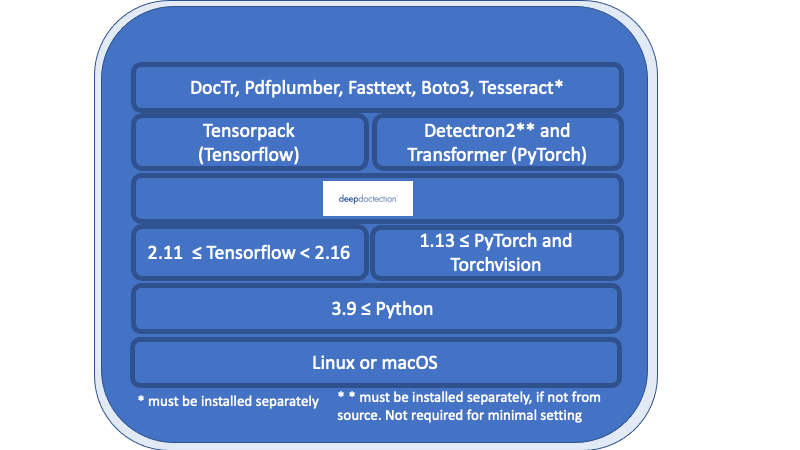
Tout dans l'aperçu énuméré sous la couche de médecine profonde est des exigences nécessaires et doit être installée séparément.
Linux ou macOS. (Windows n'est pas pris en charge mais il y a un dockerfile disponible)
Python> = 3,9
1.13 <= pytorch ou 2.11 <= Tensorflow <2,16. (Pour les versions TensorFlow inférieures, le code ne s'exécutera que sur un GPU). En général, si vous souhaitez entraîner ou affiner des modèles, un GPU est requis.
En ce qui concerne le cadre d'apprentissage en profondeur, vous devez décider entre TensorFlow et Pytorch.
Le moteur Tesseract OCR sera utilisé par un wrapper Python. Le moteur de base doit être installé séparément.
Pour la version v.0.34.0 et en dessous du docteur profond utilise des emballages Python pour Poppler afin de convertir les documents PDF en images. Pour la version v.0.35.0 cette dépendance sera facultative.
L'aperçu suivant montre la disponibilité des modèles en conjonction avec le cadre DL.
| Tâche | Pytorch | Torchscript | Tensorflow |
|---|---|---|---|
| Détection de mise en page via Detectron2 / Tensorpack | ✅ | ✅ (CPU uniquement) | ✅ (GPU uniquement) |
| Reconnaissance de la table via Detectron2 / Tensorpack | ✅ | ✅ (CPU uniquement) | ✅ (GPU uniquement) |
| Transformateur de table via les transformateurs | ✅ | ||
| Doctr | ✅ | ✅ | |
| Layoutlm (v1, v2, v3, xlm) via les transformateurs | ✅ |
Nous vous recommandons d'utiliser un environnement virtuel. Vous pouvez installer le package via PIP ou depuis Source.
Si vous souhaitez démarrer avec un réglage minimal (par exemple, exécuter l'analyseur de docteur Deep avec une configuration par défaut ou d'essayer le `` Get Startebook ''), installez Deep Doctction avec
pip install deepdoctection
Si vous souhaitez utiliser le framework TensorFlow, veuillez installer TensorPack séparément. Detectron2 ne sera pas installé et les modèles de mise en page / les modèles de reconnaissance de table fonctionneront avec TorchScript sur un CPU.
L'installation suivante vous offrira tous les modèles disponibles dans le cadre de Deep Learning ainsi que tous les modèles indépendants de TensorFlow / Pytorch. Veuillez noter que les dépendances sont très complexes. Nous nous efforçons cependant de maintenir les exigences à jour.
Pour Tensorflow , courez
pip install deepdoctection[tf]
Pour pytorch ,
Installez d'abord Detectron2 séparément car il n'est pas distribué via PYPI. Vérifiez les instructions ici. Puis courez
pip install deepdoctection[pt]
Cela installera Deep Doctction avec toutes les dépendances énumérées au-dessus de la couche de médecine profonde . Utilisez ce paramètre, si vous souhaitez démarrer ou si vous souhaitez explorer toutes les fonctionnalités.
Si vous souhaitez avoir plus de contrôle avec votre installation et recherchez moins de dépendances, installez Deep Doctction avec la configuration de base uniquement.
pip install deepdoctection
Cela ignorera toutes les bibliothèques de modèles (couches au-dessus de la couche de médecine profonde dans le diagramme) et vous serez responsable de les installer par vous-même. Remarquez que vous ne pourrez exécuter aucun pipeline avec cette configuration.
Pour plus d'informations, veuillez consulter les instructions d'installation complètes .
Téléchargez le référentiel ou le clone via
git clone https://github.com/deepdoctection/deepdoctection.git
Pour commencer avec TensorFlow , exécutez:
cd deepdoctection
pip install ".[tf]"
L'installation de la configuration complète de Pytorch à partir de la source installera également Detectron2 pour vous:
cd deepdoctection
pip install ".[source-pt]"
À partir de la version v.0.27.0 , les images docker préexistantes peuvent être téléchargées à partir du Docker Hub.
docker pull deepdoctection/deepdoctection:<release_tag>
Pour démarrer le conteneur, vous pouvez utiliser le fichier Docker Compose ./docker/pytorch-gpu/docker-compose.yaml . Dans le fichier .env fourni, spécifiez le répertoire de l'hôte où le cache de Deep Doctction doit être stocké. Ce répertoire sera monté. De plus, spécifiez un répertoire de travail pour monter des fichiers à traiter dans le conteneur.
docker compose up -d
Démarrera le conteneur.
Nous remercions toutes les bibliothèques qui fournissent du code de haute qualité et des modèles pré-formés. Sans, il aurait été impossible de développer ce cadre.
Nous nous efforçons d'éliminer les bogues. Nous savons également que le code n'est pas exempt de problèmes. Nous accueillons tous les problèmes pertinents pour ce dépôt et essayons de les résoudre le plus rapidement possible. Des corrections ou des améliorations de bogues seront déployées dans une nouvelle version toutes les 10 à 12 semaines.
... Vous pouvez facilement soutenir le projet en le rendant plus visible. Laisser une étoile ou une recommandation aidera.
Distribué sous la licence Apache 2.0. Vérifiez la licence pour plus d'informations.


