deepdoctection
v.0.37.3

A Deep Doctection é uma biblioteca Python que orquestra a extração de documentos e as tarefas de análise de layout de documentos usando modelos de aprendizado profundo. Ele não implementa modelos, mas permite criar pipelines usando bibliotecas altamente reconhecidas para detecção de objetos, OCR e tarefas selecionadas de NLP e fornece uma estrutura integrada para ajustes finos, avaliação e execução de modelos. Para tarefas de processamento de texto mais específicas, use uma das muitas outras ótimas bibliotecas de PNL.
A profunda médica se concentra em aplicativos e é feita para quem deseja resolver problemas do mundo real relacionados à extração de documentos de PDFs ou digitalizações em vários formatos de imagem.
Verifique a demonstração de um pipeline de análise de layout do documento com OCR On: abraços: abraçando espaços de rosto .
A Deep Doctection fornece a Model Wrappers de bibliotecas suportadas para que várias tarefas sejam integradas aos pipelines. Sua função principal não depende de nenhuma biblioteca específica de aprendizado profundo. Os modelos selecionados para as seguintes tarefas são suportados atualmente:
A profunda Docteção fornece sobre esses métodos para insumos de pré-processamento para modelos como corte ou redimensionamento e resultados pós-processo, como validar saídas duplicadas, relacionar palavras aos segmentos de layout detectados ou ordenar palavras em texto contíguo. Você obterá uma saída no formato JSON que poderá personalizar ainda mais por si mesmo.
Dê uma olhada no caderno de introdução no repositório de notebooks para um começo fácil.
Verifique as notas de lançamento para obter atualizações recentes.
O Deep Doctection ou suas bibliotecas de suporte fornecem modelos pré-treinados que estão na maioria dos casos disponíveis no Hub de Modelo de Face Hugging ou que serão baixados automaticamente uma vez solicitados. Por exemplo, você pode encontrar modelos de detecção de objetos pré-treinados da estrutura Tensorpack ou Detectron2 para análise de layout grossa, detecção de células de tabela e reconhecimento de tabela.
O treinamento é uma parte substancial para preparar os pipelines em algum domínio específico, que seja análise de layout de documentos, classificação de documentos ou NER. A Deep Doctection fornece scripts de treinamento para modelos baseados em treinadores desenvolvidos a partir da biblioteca que hospeda o código do modelo. Além disso, o Deep Doctecção hospeda o código de alguns conjuntos de dados bem estabelecidos, como o PublayNet , que facilitam a experiência. Ele também contém mapeamentos de formatos de dados amplamente utilizados como Coco e possui uma estrutura de dados (semelhante aos conjuntos de dados, para que a configuração de treinamento em um conjunto de dados personalizado se torne muito fácil. Este notebook mostra como fazer isso.
A profunda médica vem equipada com uma estrutura que permite avaliar previsões de um único ou múltiplo modelos em um pipeline contra alguma verdade do terreno. Verifique novamente aqui como é feito.
Tendo configurado um pipeline, leva algumas linhas de código para instanciar o pipeline e após um loop para loop, todas as páginas serão processadas através do pipeline.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
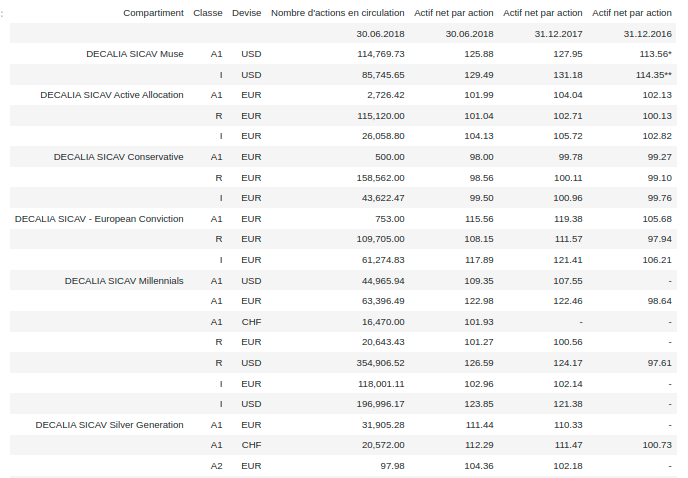
HTML(page.tables[0].html)
print(page.text)

Há uma extensa documentação disponível contendo tutoriais, conceitos de design e a API. Queremos apresentar as coisas da maneira mais abrangente e compreensível possível. No entanto, estamos cientes de que ainda existem muitas áreas em que melhorias significativas podem ser feitas em termos de clareza, gramática e correção. Estamos ansiosos por cada dica e comentário que aumente a qualidade da documentação.
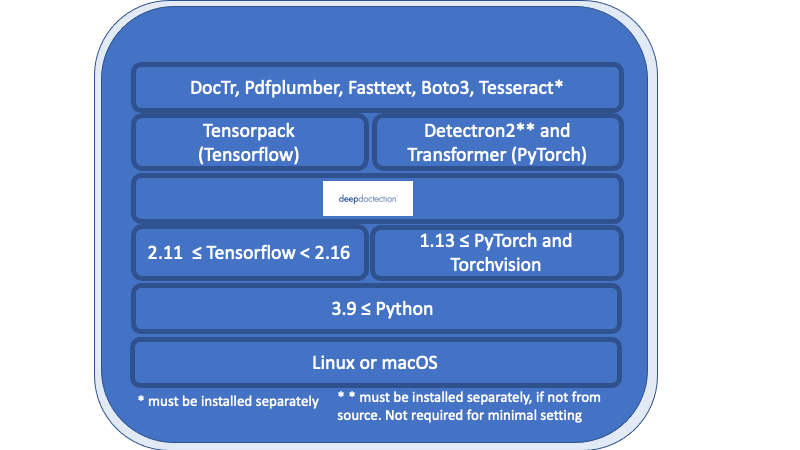
Tudo na visão geral listada abaixo da camada médica profunda são os requisitos necessários e deve ser instalada separadamente.
Linux ou macOS. (O Windows não é suportado, mas há um DockerFile disponível)
Python> = 3.9
1.13 <= pytorch ou 2.11 <= tensorflow <2.16. (Para versões mais baixas do tensorflow, o código será executado apenas em uma GPU). Em geral, se você deseja treinar ou ajustar modelos, é necessária uma GPU.
Com relação à estrutura de aprendizado profundo, você deve decidir entre o Tensorflow e o Pytorch.
O mecanismo TESSERACT OCR será usado através de um invólucro python. O mecanismo principal deve ser instalado separadamente.
Para a liberação v.0.34.0 e abaixo da profunda Docteção, usa invólucros de python para o PopPler converter documentos em PDF em imagens. Para a versão v.0.35.0 essa dependência será opcional.
A visão geral a seguir mostra a disponibilidade dos modelos em conjunto com a estrutura DL.
| Tarefa | Pytorch | Torchscript | Tensorflow |
|---|---|---|---|
| Detecção de layout via Detectron2/Tensorpack | ✅ | ✅ (somente CPU) | ✅ (somente GPU) |
| Reconhecimento de tabela via Detectron2/Tensorpack | ✅ | ✅ (somente CPU) | ✅ (somente GPU) |
| Transformador de tabela via Transformers | ✅ | ||
| Doutr | ✅ | ✅ | |
| Layoutlm (v1, v2, v3, xlm) via Transformers | ✅ |
Recomendamos usar um ambiente virtual. Você pode instalar o pacote via PIP ou a partir da fonte.
Se você deseja começar com uma configuração mínima (por exemplo , executando o Analisador de Doctção Deep com configuração padrão ou experimentando o 'Notebook para iniciar
pip install deepdoctection
Se você deseja usar o TensorFlow Framework, instale o Tensorpack separadamente. O Detectron2 não será instalado e os modelos de layout/ reconhecimento de tabela serão executados com o TorchScript em uma CPU.
A instalação a seguir fornecerá todos os modelos disponíveis na estrutura de aprendizado profundo, bem como em todos os modelos independentes do Tensorflow/Pytorch. Observe que as dependências são muito complexas. Tentamos muito manter os requisitos atualizados.
Para Tensorflow , execute
pip install deepdoctection[tf]
Para Pytorch ,
Primeiro instale o Detectron2 separadamente, pois não é distribuído via PYPI. Verifique a instrução aqui. Em seguida, corra
pip install deepdoctection[pt]
Isso instalará uma médica profunda com todas as dependências listadas acima da camada médica profunda . Use essa configuração, se você deseja começar ou deseja explorar todos os recursos.
Se você deseja ter mais controle com sua instalação e está procurando menos dependências, instale apenas a médica profunda com a configuração básica.
pip install deepdoctection
Isso ignorará todas as bibliotecas de modelos (camadas acima da camada médica profunda no diagrama) e você será responsável por instalá -las sozinho. Observe que você não poderá executar nenhum pipeline com esta configuração.
Para mais informações, consulte as instruções completas de instalação .
Baixar o repositório ou clone via
git clone https://github.com/deepdoctection/deepdoctection.git
Para começar com o TensorFlow , execute:
cd deepdoctection
pip install ".[tf]"
A instalação da configuração completa do Pytorch a partir da fonte também instalará o Detectron2 para você:
cd deepdoctection
pip install ".[source-pt]"
A partir da versão v.0.27.0 , as imagens pré-existentes do Docker podem ser baixadas no Hub do Docker.
docker pull deepdoctection/deepdoctection:<release_tag>
Para iniciar o contêiner, você pode usar o arquivo de composição do docker ./docker/pytorch-gpu/docker-compose.yaml . No arquivo .env fornecido, especifique o diretório do host em que o cache da profunda doutção deve ser armazenado. Este diretório será montado. Além disso, especifique um diretório de trabalho para montar arquivos a serem processados no contêiner.
docker compose up -d
Iniciará o contêiner.
Agradecemos a todas as bibliotecas que fornecem código de alta qualidade e modelos pré-treinados. Sem, teria sido impossível desenvolver essa estrutura.
Tentamos muito eliminar os bugs. Também sabemos que o código não está livre de problemas. Congratulamo -nos com todas as questões relevantes para este repositório e tentamos abordá -las o mais rápido possível. As correções ou aprimoramentos de bugs serão implantados em uma nova versão a cada 10 a 12 semanas.
... Você pode apoiar facilmente o projeto, tornando -o mais visível. Deixar uma estrela ou uma recomendação ajudará.
Distribuído sob a licença Apache 2.0. Verifique a licença para obter informações adicionais.


