deepdoctection
v.0.37.3

Deep Dectionは、ドキュメント抽出およびドキュメントレイアウト分析タスクを、ディープラーニングモデルを使用して文書レイアウト分析タスクを調整するPythonライブラリです。モデルを実装するのではなく、オブジェクト検出、OCR、選択されたNLPタスクのために強く認められたライブラリを使用してパイプラインを構築でき、微調整、評価、ランニングモデルの統合フレームワークを提供します。より具体的なテキスト処理タスクには、他の多くの優れたNLPライブラリのいずれかを使用しています。
Deep Dectionはアプリケーションに焦点を当てており、PDFからの文書抽出またはさまざまな画像形式でのスキャンに関連する現実世界の問題を解決したい人のために作られています。
OCRを使用したドキュメントレイアウト分析パイプラインのデモを確認します。
Deep Dectionは、パイプラインに統合されるさまざまなタスクのサポートされているライブラリのモデルラッパーを提供します。そのコア関数は、特定の深い学習ライブラリに依存しません。現在、次のタスクの選択されたモデルがサポートされています。
Deep Dectionは、トリミングやサイズ変更などのモデルや、重複出力の検証、単語の検出されたレイアウトセグメントに関連する、または隣接テキストに単語を注文するなど、プロセス後の結果を前処理する方法に加えて提供します。 JSON形式で出力を取得し、自分でさらにカスタマイズできます。
簡単なスタートを切るために、ノートブックリポジトリの紹介ノートブックをご覧ください。
最近の更新については、リリースノートを確認してください。
Deep Dectionまたはそのサポートライブラリは、ほとんどのケースで抱き合っているフェイスモデルハブで利用可能な事前に訓練されたモデルを提供します。たとえば、粗いレイアウト分析、テーブルセル検出、テーブル認識のためのTensorpackまたはDetectron2フレームワークから事前に訓練されたオブジェクト検出モデルを見つけることができます。
トレーニングは、特定のドメインでパイプラインを準備するための相当な部分です。ドキュメントレイアウト分析、ドキュメント分類、またはNERとします。 Deep Dectionは、モデルコードをホストするライブラリから開発されたトレーナーに基づいたモデルのトレーニングスクリプトを提供します。さらに、 Deep Dectionは、実験が容易になるPublayNetのようないくつかの十分に確立されたデータセットのコードをホストしています。また、COCOなどの広く使用されているデータ形式のマッピングが含まれており、データセットフレームワークがあります(データセットに似ているため、カスタムデータセットでのトレーニングのセットアップが非常に簡単になります。このノートブックは、これを行う方法を示しています。
Deep Dectionには、パイプライン内の単一または複数のモデルの予測を何らかのグラウンドトゥルースに対して評価できるフレームワークが装備されています。ここでそれがどのように行われるかをもう一度確認してください。
パイプラインをセットアップすると、パイプラインをインスタンス化するために数行のコードが必要になり、ループの後、すべてのページがパイプラインを介して処理されます。
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

チュートリアル、デザインコンセプト、APIを含む広範なドキュメントが利用可能です。私たちは、可能な限り包括的かつ理解できるように物事を提示したいと考えています。ただし、明確さ、文法、正確性の観点から、大幅な改善ができる多くの分野がまだあることを認識しています。ドキュメントの品質を高めるすべてのヒントとコメントを楽しみにしています。
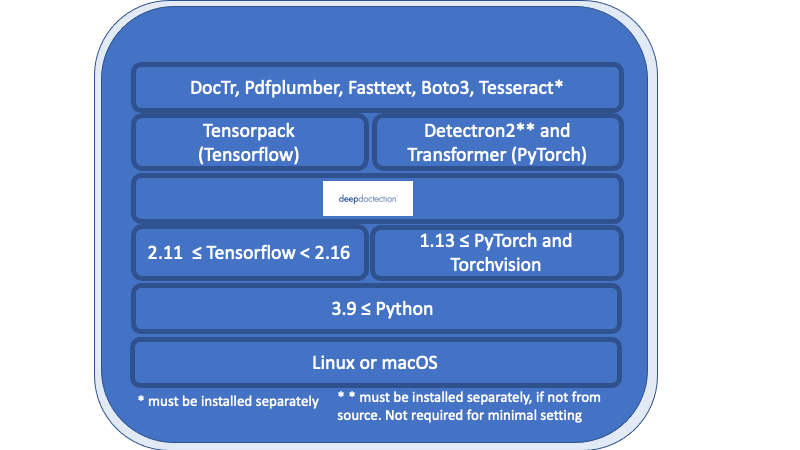
深い医師層の下にリストされている概要のすべては、必要な要件であり、個別にインストールする必要があります。
LinuxまたはmacOS。 (Windowsはサポートされていませんが、利用可能なDockerFileがあります)
Python> = 3.9
1.13 <= pytorchまたは2.11 <= tensorflow <2.16。 (低いTensorflowバージョンの場合、コードはGPUでのみ実行されます)。一般に、モデルをトレーニングまたは微調整する場合は、GPUが必要です。
深い学習フレームワークに関しては、TensorflowとPytorchを決定する必要があります。
Tesseract OCRエンジンは、Pythonラッパーを介して使用されます。コアエンジンは個別にインストールする必要があります。
リリースv.0.34.0以下では、 Deep DectectionではPopplerにPythonラッパーを使用してPDFドキュメントを画像に変換します。リリースv.0.35.0の場合、この依存関係はオプションになります。
次の概要は、DLフレームワークと組み合わせてモデルの可用性を示しています。
| タスク | Pytorch | Torchscript | Tensorflow |
|---|---|---|---|
| detectron2/tensorpack経由のレイアウト検出 | ✅ | ✅(CPUのみ) | ✅(GPUのみ) |
| detectron2/tensorpack経由のテーブル認識 | ✅ | ✅(CPUのみ) | ✅(GPUのみ) |
| トランス経由のテーブルトランス | ✅ | ||
| 教義 | ✅ | ✅ | |
| Transformersを介してLayoutlm(V1、V2、V3、XLM) | ✅ |
仮想環境を使用することをお勧めします。 PIPまたはソースからパッケージをインストールできます。
最小限の設定を始めたい場合(例:デフォルトの構成を備えたDeep Dectection Analyzerを実行するか、「Get start Notebook」を試してください)。
pip install deepdoctection
Tensorflowフレームワークを使用する場合は、Tensorpackを個別にインストールしてください。 detectron2はインストールされず、レイアウトモデル/テーブル認識モデルは、CPUでTorchscriptを使用して実行されます。
次のインストールでは、深い学習フレームワーク内で利用可能なすべてのモデルと、Tensorflow/Pytorchに依存しないすべてのモデルが提供されます。依存関係は非常に複雑であることに注意してください。しかし、私たちは要件を最新の状態に保つように一生懸命努力しています。
Tensorflowについては、実行してください
pip install deepdoctection[tf]
Pytorchのために、
Pypiを介して分布していないため、最初にDetectron2を個別にインストールします。ここで指示を確認してください。その後、実行します
pip install deepdoctection[pt]
これにより、深い医師層の上にリストされているすべての依存関係を備えた深い医師がインストールされます。開始したい場合、またはすべての機能を検討したい場合は、この設定を使用してください。
インストールでより多くのコントロールを持ち、より少ない依存関係を探している場合は、基本的なセットアップのみで深い医師をインストールしてください。
pip install deepdoctection
これにより、すべてのモデルライブラリ(図の深い医師層の上の層)が無視され、自分でインストールする責任があります。このセットアップでパイプラインを実行できないことに注意してください。
詳細については、完全なインストール手順を参照してください。
リポジトリまたはクローンをダウンロードします
git clone https://github.com/deepdoctection/deepdoctection.git
Tensorflowを始めるには、実行してください。
cd deepdoctection
pip install ".[tf]"
ソースから完全なpytorchセットアップをインストールすると、 detectron2もインストールします。
cd deepdoctection
pip install ".[source-pt]"
リリースv.0.27.0から始めて、Dockerハブから既存のDocker画像をダウンロードできます。
docker pull deepdoctection/deepdoctection:<release_tag>
コンテナを起動するには、Docker Composeファイル./docker/pytorch-gpu/docker-compose.yamlを使用できます。提供されている.envファイルで、 Deep Dectionのキャッシュを保存する必要があるホストディレクトリを指定します。このディレクトリはマウントされます。さらに、コンテナに処理するファイルをマウントする作業ディレクトリを指定します。
docker compose up -d
コンテナを起動します。
高品質のコードと事前に訓練されたモデルを提供するすべてのライブラリに感謝します。それがなければ、このフレームワークを開発することは不可能だったでしょう。
バグを排除するために一生懸命努力します。また、コードには問題がないこともわかっています。このリポジトリに関連するすべての問題を歓迎し、できるだけ早くそれらに対処しようとします。バグの修正または拡張機能は、10〜12週間ごとに新しいリリースで展開されます。
...プロジェクトをより目立たせることで、プロジェクトを簡単にサポートできます。星を離れるか、推奨を残すことが役立ちます。
Apache 2.0ライセンスの下で配布。追加情報については、ライセンスを確認してください。


