deepdoctection
v.0.37.3

Deep Doctction ist eine Python -Bibliothek, die Aufgaben der Dokumentextraktion und Dokumentlayoutanalyse unter Verwendung von Deep -Learning -Modellen orchestriert. Es wird keine Modelle implementiert, ermöglicht es Ihnen, Pipelines mit hochanerkannten Bibliotheken für Objekterkennung, OCR und ausgewählte NLP-Aufgaben zu erstellen und bietet einen integrierten Framework für Feinabstimmungen, Bewertung und Ausführen von Modellen. Für spezifischere Textverarbeitungsaufgaben verwenden Sie eine der vielen anderen großartigen NLP -Bibliotheken.
Deep Doctction konzentriert sich auf Anwendungen und wird für diejenigen hergestellt, die Probleme mit realen Welt in Bezug auf die Dokumentenextraktion aus PDFs oder Scans in verschiedenen Bildformaten lösen möchten.
Überprüfen Sie die Demo einer Dokument -Layout -Analyse -Pipeline mit OCR auf: Umarmungen: Umarmung von Gesichtsräumen .
Deep Doctction bietet Modellverpackungen von unterstützten Bibliotheken, damit verschiedene Aufgaben in Pipelines integriert werden können. Die Kernfunktion hängt nicht von einer bestimmten Deep -Learning -Bibliothek ab. Ausgewählte Modelle für die folgenden Aufgaben werden derzeit unterstützt:
Deep Doctction liefert zu diesen Methoden zur Vorverarbeitung von Eingaben in Modelle wie Zuschneiden oder Größe und zur Postverarbeitungsergebnisse, z. Sie erhalten eine Ausgabe im JSON -Format, das Sie noch weiter anpassen können.
Schauen Sie sich das Einführung Notebook im Notebook -Repo für einen einfachen Start an.
Überprüfen Sie die Versionshinweise für aktuelle Updates.
Deep Doctction oder ihre Support-Bibliotheken bieten vorgeschriebene Modelle, die in den meisten Fällen im Umarmungs-Face-Modell-Hub verfügbar sind oder automatisch heruntergeladen werden. Beispielsweise finden Sie vorgebildete Objekterkennungsmodelle aus dem Tensorpack- oder DETECTRON2-Framework für die grobe Layoutanalyse, die Tabellenzellerkennung und die Tabellenerkennung.
Das Training ist ein wesentlicher Bestandteil, um Pipelines auf einer bestimmten Domäne vorzubereiten. Es sei Dokumentlayoutanalyse, Dokumentklassifizierung oder NER. Deep Doctction bietet Schulungsskripte für Modelle, die auf Trainern basieren, die aus der Bibliothek entwickelt wurden, in der der Modellcode gehostet wird. Darüber hinaus veranstaltet Deep Doctction Code auf einige gut etablierte Datensätze wie PublayNet , die das Experimentieren erleichtern. Es enthält auch Zuordnungen aus weit verbreiteten Datenformaten wie Coco und verfügt über ein Datensatz -Framework (ähnlich wie Datensätze , sodass das Einrichten von Schulungen in einem benutzerdefinierten Datensatz sehr einfach wird. Dieses Notebook zeigt Ihnen, wie dies zu tun.
Deep Doctction ist mit einem Rahmen ausgestattet, mit dem Sie Vorhersagen eines einzelnen oder mehrere Modelle in einer Pipeline gegen eine Grundwahrheit bewerten können. Überprüfen Sie hier noch einmal, wie es gemacht wird.
Nachdem Sie eine Pipeline eingerichtet haben, benötigen Sie einige Codezeilen, um die Pipeline zu instanziieren, und nach einer für die Schleife werden alle Seiten über die Pipeline verarbeitet.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

Es gibt eine umfangreiche Dokumentation mit Tutorials, Designkonzepten und der API. Wir wollen Dinge so umfassend und verständlich wie möglich darstellen. Wir sind uns jedoch bewusst, dass es immer noch viele Bereiche gibt, in denen in Bezug auf Klarheit, Grammatik und Korrektheit erhebliche Verbesserungen vorgenommen werden können. Wir freuen uns auf jeden Hinweis und Kommentar, der die Qualität der Dokumentation erhöht.
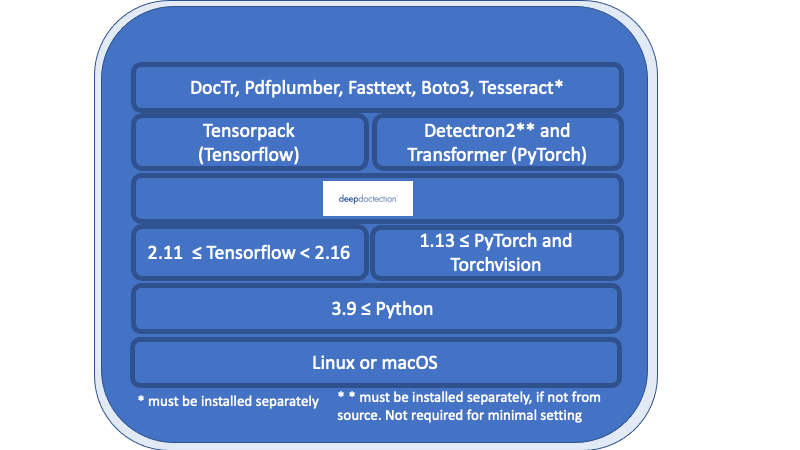
Alles in der unter der tiefen Doktionsschicht aufgeführten Übersicht sind notwendige Anforderungen und müssen separat installiert werden.
Linux oder MacOS. (Windows wird nicht unterstützt, aber es gibt eine Dockerfile)
Python> = 3,9
1.13 <= Pytorch oder 2.11 <= TensorFlow <2,16. (Für niedrigere Tensorflow -Versionen wird der Code nur auf einer GPU ausgeführt.) Wenn Sie im Allgemeinen Modelle trainieren oder feinstimmen möchten, ist eine GPU erforderlich.
In Bezug auf den Deep -Lern -Framework müssen Sie sich zwischen TensorFlow und Pytorch entscheiden.
Der Tesseract -OCR -Motor wird über eine Python -Verpackung verwendet. Der Kernmotor muss separat installiert werden.
Für die Veröffentlichung v.0.34.0 und unter Deep Doctction verwendet Python -Wrapper für Poppler, um PDF -Dokumente in Bilder umzuwandeln. Für die Veröffentlichung v.0.35.0 ist diese Abhängigkeit optional.
Die folgende Übersicht zeigt die Verfügbarkeit der Modelle in Verbindung mit dem DL -Framework.
| Aufgabe | Pytorch | Torchscript | Tensorflow |
|---|---|---|---|
| Layout -Erkennung über DETECTRON2/TENSORPACK | ✅ | ✅ (nur CPU) | ✅ (nur GPU) |
| Tabellenerkennung über DETECTRON2/Tensorpack | ✅ | ✅ (nur CPU) | ✅ (nur GPU) |
| Tabellentransformator über Transformatoren | ✅ | ||
| Doktr | ✅ | ✅ | |
| Layoutlm (V1, V2, V3, XLM) über Transformatoren | ✅ |
Wir empfehlen die Verwendung einer virtuellen Umgebung. Sie können das Paket über PIP oder aus Quelle installieren.
Wenn Sie mit einer minimalen Einstellung beginnen möchten (z. B. das Ausführen des Deep Doctction Analyzer mit Standardkonfiguration oder das "Erste -Start -Notebook"), installieren Sie die Deep Doctction mit einer tiefen Doktion mit
pip install deepdoctection
Wenn Sie das TensorFlow -Framework verwenden möchten, installieren Sie TensorPack separat. DETECRON2 wird nicht installiert und Layout -Modelle/ Tabellenerkennungsmodelle werden mit Torchscript auf einer CPU ausgeführt.
Die folgende Installation erhalten Sie alle im Deep Learning Framework verfügbaren Modelle sowie alle Modelle, die unabhängig von TensorFlow/Pytorch sind. Bitte beachten Sie, dass die Abhängigkeiten sehr komplex sind. Wir bemühen uns jedoch, die Anforderungen auf dem neuesten Stand zu halten.
Für TensorFlow laufen
pip install deepdoctection[tf]
Für pytorch ,
Installieren Sie zuerst DETECTRON2 GREENTE, da er nicht über PYPI verteilt wird. Überprüfen Sie die Anweisung hier. Dann rennen
pip install deepdoctection[pt]
Dadurch wird eine tiefe Doktion mit allen oben aufgeführten Abhängigkeiten installiert. Verwenden Sie diese Einstellung, wenn Sie anfangen möchten oder alle Funktionen erkunden möchten.
Wenn Sie mehr Kontrolle über Ihre Installation haben möchten und nach weniger Abhängigkeiten suchen, installieren Sie nur eine tiefe Doktion mit dem Basis -Setup.
pip install deepdoctection
Dies ignoriert alle Modellbibliotheken (Schichten über der tiefen Doktionsschicht im Diagramm) und Sie sind dafür verantwortlich, sie selbst zu installieren. Beachten Sie, dass Sie mit diesem Setup keine Pipeline ausführen können.
Weitere Informationen finden Sie in den vollständigen Installationsanweisungen .
Laden Sie das Repository oder den Klon durch
git clone https://github.com/deepdoctection/deepdoctection.git
Um mit TensorFlow zu beginnen, rennen Sie:
cd deepdoctection
pip install ".[tf]"
Durch die Installation des vollständigen Pytorch -Setups von Source werden auch DETECRON2 für Sie installiert:
cd deepdoctection
pip install ".[source-pt]"
Ab Version v.0.27.0 können bereits bestehende Docker-Bilder aus dem Docker-Hub heruntergeladen werden.
docker pull deepdoctection/deepdoctection:<release_tag>
Um den Container zu starten, können Sie die Docker Compose-Datei ./docker/pytorch-gpu/docker-compose.yaml verwenden. Geben Sie in der vorgesehenen .env -Datei das Hostverzeichnis an, in dem der Cache von Deep Doctction gespeichert werden sollte. Dieses Verzeichnis wird montiert. Geben Sie außerdem ein Arbeitsverzeichnis an, um Dateien zu montieren, die in den Container verarbeitet werden sollen.
docker compose up -d
startet den Container.
Wir danken allen Bibliotheken, die qualitativ hochwertige Code und vorgeborene Modelle bieten. Ohne wäre es unmöglich gewesen, diesen Rahmen zu entwickeln.
Wir bemühen uns, Fehler zu beseitigen. Wir wissen auch, dass der Code nicht frei von Problemen ist. Wir begrüßen alle für dieses Repo relevanten Probleme und versuchen, sie so schnell wie möglich anzusprechen. Fehlerbehebungen oder Verbesserungen werden alle 10 bis 12 Wochen in einer neuen Version eingesetzt.
... Sie können das Projekt leicht unterstützen, indem Sie es sichtbarer machen. Ein Stern oder eine Empfehlung zu verlassen, hilft.
Unter der Apache 2.0 -Lizenz verteilt. Überprüfen Sie die Lizenz für zusätzliche Informationen.


