deepdoctection
v.0.37.3

Deep Doctection هي مكتبة Python التي تنظم مهام استخراج المستندات ومهام تحليل تخطيط المستندات باستخدام نماذج التعلم العميقة. إنه لا ينفذ النماذج ولكنه يمكّنك من إنشاء خطوط أنابيب باستخدام مكتبات معترف بها للغاية للكشف عن الكائنات ، و OCR ومهام NLP المحددة وتوفر إطارًا متكاملًا للضبط وتقييم وتقييم النماذج. لمزيد من مهام معالجة النصوص ، استخدم واحدة من العديد من مكتبات NLP العديدة الأخرى.
يركز Deep Doctection على التطبيقات ويتم صنعه لأولئك الذين يرغبون في حل مشاكل العالم الحقيقي المتعلقة باستخراج المستندات من PDFs أو عمليات المسح في تنسيقات الصور المختلفة.
تحقق من العرض التوضيحي لخط أنابيب تحليل تخطيط المستندات مع ON: Hugs: Lugging Face Spaces .
يوفر Deep Doctection أغلفة نموذجية للمكتبات المدعومة لمختلف المهام التي سيتم دمجها في خطوط الأنابيب. لا تعتمد وظيفتها الأساسية على أي مكتبة تعليمية عميقة محددة. نماذج مختارة للمهام التالية مدعومة حاليًا:
يوفر Deep Doctection علاوة على تلك الطرق لمدخلات ما قبل المعالجة لنماذج مثل زراعة أو تغيير حجمها ونتائج ما بعد العملية ، مثل التحقق من صحة المخرجات المكررة ، أو الكلمات المتعلقة بالكلمات التي تم اكتشافها أو ترتيب الكلمات إلى نص متصمم. ستحصل على إخراج بتنسيق JSON الذي يمكنك تخصيصه بنفسك.
إلقاء نظرة على دفتر المقدمة في دفتر دفتر الملاحظات لبداية سهلة.
تحقق من ملاحظات الإصدار للحصول على التحديثات الأخيرة.
توفر Deep Doctection أو مكتبات الدعم نماذج مدربة مسبقًا والتي تتوفر في معظم الحالات المتوفرة في Hugging Face Model Hub أو التي سيتم تنزيلها تلقائيًا بمجرد طلبها. على سبيل المثال ، يمكنك العثور على نماذج اكتشاف الكائنات المدربة مسبقًا من إطار Tensorpack أو Detectron2 لتحليل التصميم الخشن ، واكتشاف خلايا الجدول والتعرف على الجدول.
يعد التدريب جزءًا كبيرًا لإعداد خطوط الأنابيب في مجال معين ، فليكن تحليل تخطيط المستند أو تصنيف المستندات أو NER. يوفر Deep Doctection البرامج النصية التدريبية للنماذج التي تستند إلى المدربين الذين تم تطويرهم من المكتبة التي تستضيف رمز النموذج. علاوة على ذلك ، يستضيف Deep Doctection رمزًا لبعض مجموعات البيانات الراسخة مثل PublayNet مما يجعل من السهل تجربته. كما أنه يحتوي على تعيينات من تنسيقات البيانات المستخدمة على نطاق واسع مثل COCO ولديه إطار عمل لمجموعة البيانات (أقرب إلى مجموعات البيانات بحيث يصبح إعداد التدريب على مجموعة بيانات مخصصة أمرًا سهلاً للغاية. يوضح لك هذا الكمبيوتر الدفتري كيفية القيام بذلك.
يأتي Deep Doctection مزودًا بإطار يتيح لك تقييم تنبؤات نماذج واحدة أو متعددة في خط أنابيب مقابل بعض الحقيقة الأرضية. تحقق مرة أخرى هنا كيف يتم ذلك.
بعد إعداد خط أنابيب ، يستغرق الأمر بضعة أسطر من التعليمات البرمجية لإنشاء إنشاء خط أنابيب وبعد معالجة جميع الصفحات من خلال خط الأنابيب.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

هناك وثائق شاملة متوفرة تحتوي على دروس ومفاهيم التصميم وواجهة برمجة التطبيقات. نريد أن نقدم الأشياء بشكل شامل ومفهوم قدر الإمكان. ومع ذلك ، نحن ندرك أنه لا يزال هناك العديد من المجالات التي يمكن إجراء تحسينات كبيرة من حيث الوضوح والقواعد والصحة. نتطلع إلى كل تلميح والتعليق الذي يزيد من جودة الوثائق.
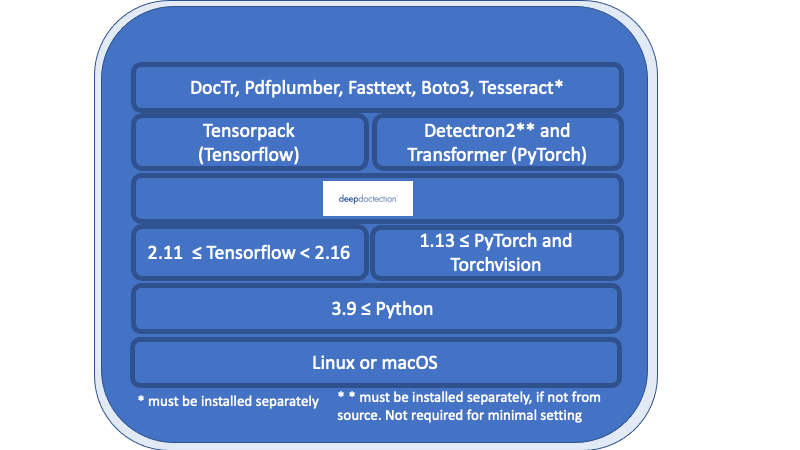
كل شيء في النظرة العامة المذكورة أسفل طبقة الدكتوراه العميقة هو المتطلبات اللازمة ويجب تثبيتها بشكل منفصل.
Linux أو MacOS. (Windows غير مدعوم ولكن هناك dockerfile متاح)
بيثون> = 3.9
1.13 <= pytorch أو 2.11 <= TensorFlow <2.16. (لانخفاض إصدارات TensorFlow ، سيتم تشغيل الكود فقط على وحدة معالجة الرسومات). بشكل عام ، إذا كنت ترغب في تدريب نماذج أو ضبطها ، مطلوب وحدة معالجة الرسومات.
فيما يتعلق بإطار التعلم العميق ، يجب أن تقرر بين TensorFlow و Pytorch.
سيتم استخدام محرك Tesseract OCR من خلال غلاف Python. يجب تثبيت المحرك الأساسي بشكل منفصل.
للإصدار v.0.34.0 وتحت الدكتوراه العميقة يستخدم أغلفة Python لـ Poppler لتحويل مستندات PDF إلى صور. للإصدار v.0.35.0 ستكون هذه التبعية اختيارية.
تعرض النظرة العامة التالية توفر النماذج بالتزامن مع إطار DL.
| مهمة | Pytorch | Torchscript | Tensorflow |
|---|---|---|---|
| اكتشاف التصميم عن طريق detectron2/tensorpack | ✅ | ✅ (وحدة المعالجة المركزية فقط) | ✅ (GPU فقط) |
| التعرف على الجدول عبر detectron2/tensorpack | ✅ | ✅ (وحدة المعالجة المركزية فقط) | ✅ (GPU فقط) |
| محول الجدول عبر المحولات | ✅ | ||
| Doctr | ✅ | ✅ | |
| layoutlm (v1 ، v2 ، v3 ، xlm) عبر المحولات | ✅ |
نوصي باستخدام بيئة افتراضية. يمكنك تثبيت الحزمة عبر PIP أو من المصدر.
إذا كنت ترغب في البدء بإعداد الحد الأدنى (على سبيل المثال ، قم بتشغيل محلل الدكتوراه العميقة مع التكوين الافتراضي أو تجربة "Get Particle Notebook") ، فقم بتثبيت الدكتوراه العميقة مع
pip install deepdoctection
إذا كنت ترغب في استخدام إطار عمل TensorFlow ، فيرجى تثبيت Tensorpack بشكل منفصل. لن يتم تثبيت Detectron2 وسيتم تشغيل نماذج التعرف على الجدول مع Torchscript على وحدة المعالجة المركزية.
سيمنحك التثبيت التالي جميع النماذج المتاحة في إطار التعلم العميق بالإضافة إلى جميع النماذج المستقلة عن Tensorflow/Pytorch. يرجى ملاحظة أن التبعيات معقدة للغاية. نحاول جاهدين الحفاظ على المتطلبات محدثة.
من أجل TensorFlow ، قم بالتشغيل
pip install deepdoctection[tf]
ل Pytorch ،
أول تثبيت Detectron2 بشكل منفصل لأنه لا يتم توزيعه عبر PYPI. تحقق من التعليمات هنا. ثم ركض
pip install deepdoctection[pt]
سيؤدي ذلك إلى تثبيت الدكتوراه العميقة مع جميع التبعيات المدرجة فوق طبقة الدكتوراه العميقة . استخدم هذا الإعداد ، إذا كنت ترغب في البدء أو ترغب في استكشاف جميع الميزات.
إذا كنت ترغب في الحصول على مزيد من التحكم في التثبيت وتبحث عن عدد أقل من التبعيات ، فقم بتثبيت الدكتوراه العميقة مع الإعداد الأساسي فقط.
pip install deepdoctection
سيتجاهل هذا جميع مكتبات النماذج (الطبقات فوق طبقة الدكتوراه العميقة في الرسم البياني) وستكون مسؤولاً عن تثبيتها بنفسك. لاحظ أنك لن تتمكن من تشغيل أي خط أنابيب باستخدام هذا الإعداد.
لمزيد من المعلومات ، يرجى الرجوع إلى تعليمات التثبيت الكاملة .
قم بتنزيل المستودع أو الاستنساخ عبر
git clone https://github.com/deepdoctection/deepdoctection.git
للبدء في TensorFlow ، قم بالتشغيل:
cd deepdoctection
pip install ".[tf]"
سيؤدي تثبيت إعداد Pytorch الكامل من المصدر أيضًا إلى تثبيت Detectron2 لك:
cd deepdoctection
pip install ".[source-pt]"
بدءًا من الإصدار v.0.27.0 ، يمكن تنزيل صور Docker الموجودة مسبقًا من Docker Hub.
docker pull deepdoctection/deepdoctection:<release_tag>
لبدء الحاوية ، يمكنك استخدام ملف Docker ./docker/pytorch-gpu/docker-compose.yaml . في ملف .env المقدم ، حدد دليل المضيف حيث يجب تخزين ذاكرة التخزين المؤقت لـ Deep Doctection. سيتم تركيب هذا الدليل. بالإضافة إلى ذلك ، حدد دليلًا عملًا لتركيب الملفات المراد معالجتها في الحاوية.
docker compose up -d
سيبدأ الحاوية.
نشكر جميع المكتبات التي توفر رمزًا عالي الجودة ونماذج مدربة مسبقًا. بدون ، كان من المستحيل تطوير هذا الإطار.
نحاول بجد التخلص من الحشرات. نعلم أيضًا أن الرمز ليس خاليًا من القضايا. نرحب بجميع المشكلات ذات الصلة بهذا الريبو ونحاول معالجتها في أسرع وقت ممكن. سيتم نشر إصلاحات الأخطاء أو التحسينات في إصدار جديد كل 10 إلى 12 أسبوعًا.
... يمكنك دعم المشروع بسهولة بجعله أكثر وضوحًا. ترك نجم أو توصية سوف يساعد.
موزعة تحت رخصة Apache 2.0. تحقق من الترخيص للحصول على معلومات إضافية.


