deepdoctection
v.0.37.3

Deep Doctection은 딥 러닝 모델을 사용하여 문서 추출 및 문서 레이아웃 분석 작업을 오케스트레이션하는 Python 라이브러리입니다. 모델을 구현하지는 않지만 객체 감지, OCR 및 선택된 NLP 작업을 위해 고도로 인정 된 라이브러리를 사용하여 파이프 라인을 구축 할 수 있으며 미세 조정, 평가 및 실행 실행을위한 통합 프레임 워크를 제공합니다. 보다 구체적인 텍스트 처리 작업은 다른 많은 훌륭한 NLP 라이브러리 중 하나를 사용하십시오.
Deep Doctection은 응용 프로그램에 중점을두고 PDFS 또는 다양한 이미지 형식의 스캔과 관련된 실제 문제를 해결하려는 사람들을 위해 만들어집니다.
OCR ON : Hugs : Hugging Face Spaces를 사용하여 문서 레이아웃 분석 파이프 라인의 데모를 확인하십시오.
Deep Doctection은 다양한 작업을 파이프 라인에 통합 할 수 있도록 지원되는 라이브러리의 모델 포장지를 제공합니다. 핵심 기능은 특정 딥 러닝 라이브러리에 의존하지 않습니다. 다음 작업에 대한 선택된 모델은 현재 지원됩니다.
Deep Doctection은 자르기 또는 크기 조정과 같은 모델에 대한 사전 프로세스 입력 및 중복 출력 검증, Word를 감지 된 레이아웃 세그먼트와 관련하여 단어를 연속 텍스트로 주문하는 것과 같은 사전 프로세싱 입력을 제공하는 방법을 제공합니다. JSON 형식의 출력을 직접 사용자 정의 할 수 있습니다.
쉬운 출발을 위해 노트북 repo의 소개 노트북을 살펴보십시오.
최근 업데이트에 대한 릴리스 노트를 확인하십시오.
Deep Doctection 또는 지원 라이브러리는 대부분의 경우 Hugging Face Model Hub 에서 사용 가능한 경우 또는 요청되면 자동으로 다운로드 할 예정인 미리 훈련 된 모델을 제공합니다. 예를 들어, 거친 레이아웃 분석, 테이블 셀 감지 및 테이블 인식을위한 Tensorpack 또는 Detectron2 프레임 워크에서 미리 훈련 된 객체 감지 모델을 찾을 수 있습니다.
교육은 일부 특정 도메인에서 파이프 라인을 준비하는 데 실질적인 부분입니다. 문서 레이아웃 분석, 문서 분류 또는 NER이되도록하십시오. Deep Doctection은 모델 코드를 호스팅하는 라이브러리에서 개발 된 트레이너를 기반으로하는 모델에 대한 교육 스크립트를 제공합니다. 또한 Deep Doctection은 Publaynet 과 같은 잘 확립 된 데이터 세트에 코드를 호스팅하여 쉽게 실험 할 수 있습니다. 또한 Coco와 같은 널리 사용되는 데이터 형식의 매핑이 포함되어 있으며 데이터 세트 프레임 워크가 있습니다 ( 데이터 세트 와 유사하게 사용자 정의 데이터 세트에서 교육을 설정하는 것이 매우 쉬워집니다. 이 노트북은 이를 수행하는 방법을 보여줍니다.
Deep Doctection에는 일부 근거 진실에 대한 파이프 라인에서 단일 또는 여러 모델의 예측을 평가할 수있는 프레임 워크가 장착되어 있습니다. 여기서 어떻게 수행되었는지 다시 확인하십시오.
파이프 라인을 설정하면 파이프 라인을 인스턴스화하기 위해 몇 줄의 코드가 필요하며 For Loop 후 모든 페이지는 파이프 라인을 통해 처리됩니다.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

자습서, 디자인 개념 및 API가 포함 된 광범위한 문서가 있습니다. 우리는 가능한 한 포괄적이고 이해할 수있는 것들을 제시하고 싶습니다. 그러나 우리는 명확성, 문법 및 정확성 측면에서 상당한 개선이 이루어질 수있는 많은 영역이 있다는 것을 알고 있습니다. 우리는 문서의 품질을 높이는 모든 힌트와 의견을 기대합니다.
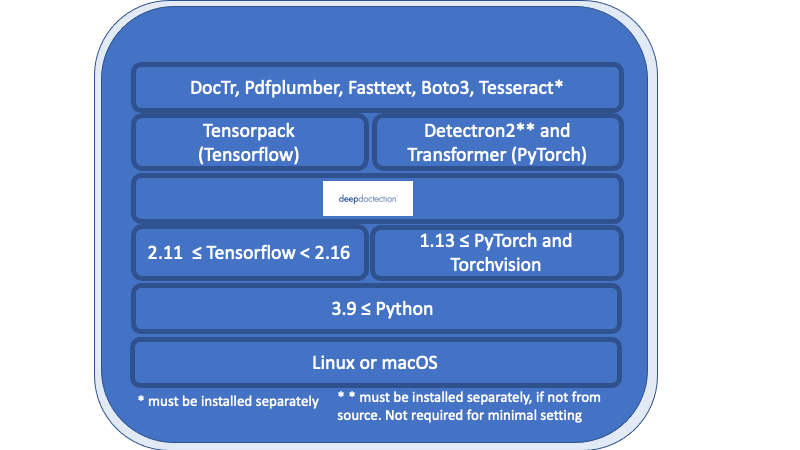
딥 문서 계층 아래에 나열된 개요의 모든 것은 필요한 요구 사항이며 별도로 설치해야합니다.
리눅스 또는 마코. (Windows는 지원되지 않지만 사용 가능한 Dockerfile이 있습니다)
파이썬> = 3.9
1.13 <= pytorch 또는 2.11 <= 텐서 플로우 <2.16. (낮은 텐서 플로우 버전의 경우 코드는 GPU에서만 실행됩니다). 일반적으로 모델을 훈련 시키거나 미세 조정하려면 GPU가 필요합니다.
딥 러닝 프레임 워크와 관련하여 Tensorflow와 Pytorch를 결정해야합니다.
Tesseract OCR 엔진은 파이썬 래퍼를 통해 사용됩니다. 코어 엔진은 별도로 설치해야합니다.
릴리스 v.0.34.0 이하의 딥 문서는 팝플러의 파이썬 포장지를 사용하여 PDF 문서를 이미지로 변환합니다. 릴리스 v.0.35.0 의 경우이 종속성은 선택 사항입니다.
다음 개요는 DL 프레임 워크와 함께 모델의 가용성을 보여줍니다.
| 일 | Pytorch | 토치 스크립트 | 텐서 플로 |
|---|---|---|---|
| Detectron2/Tensorpack을 통한 레이아웃 감지 | ✅ | ✅ (CPU 만 해당) | ✅ (GPU 만 해당) |
| Detectron2/Tensorpack을 통한 테이블 인식 | ✅ | ✅ (CPU 만 해당) | ✅ (GPU 만 해당) |
| 변압기를 통한 테이블 변압기 | ✅ | ||
| 교리 | ✅ | ✅ | |
| 변압기를 통한 Layoutlm (v1, v2, v3, xlm) | ✅ |
가상 환경을 사용하는 것이 좋습니다. PIP 또는 소스에서 패키지를 설치할 수 있습니다.
최소한의 설정으로 시작하려면 (예 : 기본 구성으로 Deep Doctection Analyzer를 실행하거나 '시작 노트북을 사용해보십시오) Deep Doctection을 설치하십시오.
pip install deepdoctection
Tensorflow 프레임 워크를 사용하려면 Tensorpack을 별도로 설치하십시오. Detectron2는 설치되지 않으며 레이아웃 모델/ 테이블 인식 모델은 CPU에서 Torchscript와 함께 실행됩니다.
다음 설치는 딥 러닝 프레임 워크 내에서 사용할 수있는 모든 모델과 Tensorflow/Pytorch와 무관 한 모든 모델을 제공합니다. 의존성은 매우 복잡합니다. 우리는 요구 사항을 최신 상태로 유지하려고 노력합니다.
Tensorflow 의 경우 실행하십시오
pip install deepdoctection[tf]
Pytorch 의 경우
먼저 PYPI를 통해 배포되지 않으므로 Detectron2를 별도로 설치하십시오. 여기에서 지시 사항을 확인하십시오. 그런 다음 실행하십시오
pip install deepdoctection[pt]
이것은 딥 문서 층 위에 나열된 모든 종속성을 갖춘 딥 문서를 설치합니다. 시작하거나 모든 기능을 탐색하려면이 설정을 사용하십시오.
설치에 대해 더 많은 제어를 원하고 적은 의존성을 찾고 있다면 기본 설정만으로 깊은 문서를 설치하십시오.
pip install deepdoctection
이것은 모든 모델 라이브러리 (다이어그램의 딥 문서 층 위의 계층)를 무시하고 직접 설치해야합니다. 이 설정으로 파이프 라인을 실행할 수 없습니다.
자세한 내용은 전체 설치 지침을 참조하십시오.
저장소 또는 클론을 통해 다운로드하십시오
git clone https://github.com/deepdoctection/deepdoctection.git
Tensorflow 를 시작하려면 실행하십시오.
cd deepdoctection
pip install ".[tf]"
소스에서 전체 Pytorch 설정을 설치하면 Detctron2가 설치됩니다.
cd deepdoctection
pip install ".[source-pt]"
릴리스 v.0.27.0 에서 시작하여 기존 Docker 이미지를 Docker Hub에서 다운로드 할 수 있습니다.
docker pull deepdoctection/deepdoctection:<release_tag>
컨테이너를 시작하려면 Docker Compose 파일 ./docker/pytorch-gpu/docker-compose.yaml 을 사용할 수 있습니다. 제공된 .env 파일에서 Deep Doctection의 캐시를 저장 해야하는 호스트 디렉토리를 지정하십시오. 이 디렉토리는 장착됩니다. 또한 컨테이너로 처리 할 파일을 마운트하는 작업 디렉토리를 지정하십시오.
docker compose up -d
컨테이너를 시작합니다.
고품질 코드와 미리 훈련 된 모델을 제공하는 모든 라이브러리에 감사드립니다. 이 프레임 워크를 개발하는 것은 불가능했을 것입니다.
우리는 버그를 제거하기 위해 열심히 노력합니다. 우리는 또한 코드에 문제가 없다는 것을 알고 있습니다. 우리는이 저장소와 관련된 모든 문제를 환영하며 가능한 빨리 해결하려고 노력합니다. 버그 수정 또는 개선 사항은 10 주에서 12 주마다 새 릴리스에 배치됩니다.
... 프로젝트를보다 눈에 띄게 만들어 프로젝트를 쉽게 지원할 수 있습니다. 별을 떠나거나 추천을 남기면 도움이됩니다.
Apache 2.0 라이센스에 따라 배포됩니다. 추가 정보는 라이센스를 확인하십시오.


