deepdoctection
v.0.37.3

Deep Pettection es una biblioteca de Python que orquesta la extracción de documentos y las tareas de análisis de diseño de documentos utilizando modelos de aprendizaje profundo. No implementa modelos, pero le permite construir tuberías utilizando bibliotecas altamente reconocidas para la detección de objetos, OCR y tareas de PNL seleccionadas y proporciona un marco integrado para ajustar, evaluar y ejecutar modelos. Para tareas de procesamiento de texto más específicas, use una de las muchas otras grandes bibliotecas de PNL.
Deep Pettection se centra en las aplicaciones y está hecho para aquellos que desean resolver problemas del mundo real relacionados con la extracción de documentos de PDF o escaneos en varios formatos de imagen.
Consulte la demostración de una tubería de análisis de diseño de documento con OCR ON: Abrazos: Spaces Face Spaces .
Deep Pettection proporciona envoltorios de modelos de bibliotecas admitidas para diversas tareas que se integran en las tuberías. Su función central no depende de ninguna biblioteca de aprendizaje profundo específico. Los modelos seleccionados para las siguientes tareas son compatibles actualmente:
Deep Pettection proporciona además esos métodos para el procesamiento previo de las entradas con modelos como el cultivo o el cambio de tamaño y para los resultados posteriores al procesamiento, como validar salidas duplicadas, relacionarse con palabras con segmentos de diseño detectados u ordenar palabras en texto contiguo. Obtendrá una salida en formato JSON que puede personalizar aún más por sí mismo.
Eche un vistazo al cuaderno de introducción en el repositorio del cuaderno para un comienzo fácil.
Verifique las notas de la versión para obtener actualizaciones recientes.
Las bibliotecas de la médica profunda o sus bibliotecas de soporte proporcionan modelos previamente capacitados que se encuentran en la mayoría de los casos disponibles en el Hub Model Model Hub o que se descargarán automáticamente una vez que se solicite. Por ejemplo, puede encontrar modelos de detección de objetos previamente capacitados del marco TensorPack o Detectron2 para el análisis de diseño grueso, detección de células de tabla y reconocimiento de tabla.
La capacitación es una parte sustancial para preparar tuberías en algún dominio específico, que sea un análisis de diseño de documentos, clasificación de documentos o NER. Deep Pettects proporciona scripts de capacitación para modelos basados en entrenadores desarrollados a partir de la biblioteca que aloja el código del modelo. Además, la médica profunda aloja el código a algunos conjuntos de datos bien establecidos como Publaynet que facilita el experimento. También contiene asignaciones de formatos de datos ampliamente utilizados como Coco y tiene un marco de conjunto de datos (similar a los conjuntos de datos para que configurar la capacitación en un conjunto de datos personalizado se vuelva muy fácil. Este cuaderno le muestra cómo hacerlo.
La médica profunda viene equipada con un marco que le permite evaluar predicciones de un solo o múltiples modelos en una tubería contra alguna verdad terrestre. Consulte de nuevo aquí cómo se hace.
Habiendo configurado una tubería, le lleva unas pocas líneas de código para instanciar la tubería y después de un bucle for bucle, todas las páginas se procesarán a través de la tubería.
import deepdoctection as dd
from IPython . core . display import HTML
from matplotlib import pyplot as plt
analyzer = dd . get_dd_analyzer () # instantiate the built-in analyzer similar to the Hugging Face space demo
df = analyzer . analyze ( path = "/path/to/your/doc.pdf" ) # setting up pipeline
df . reset_state () # Trigger some initialization
doc = iter ( df )
page = next ( doc )
image = page . viz ()
plt . figure ( figsize = ( 25 , 17 ))
plt . axis ( 'off' )
plt . imshow ( image )
HTML(page.tables[0].html)
print(page.text)

Hay una amplia documentación disponible que contiene tutoriales, conceptos de diseño y la API. Queremos presentar las cosas de la manera más integral y comprensible posible. Sin embargo, somos conscientes de que todavía hay muchas áreas donde se pueden hacer mejoras significativas en términos de claridad, gramática y corrección. Esperamos cada pista y comentarios que aumenten la calidad de la documentación.
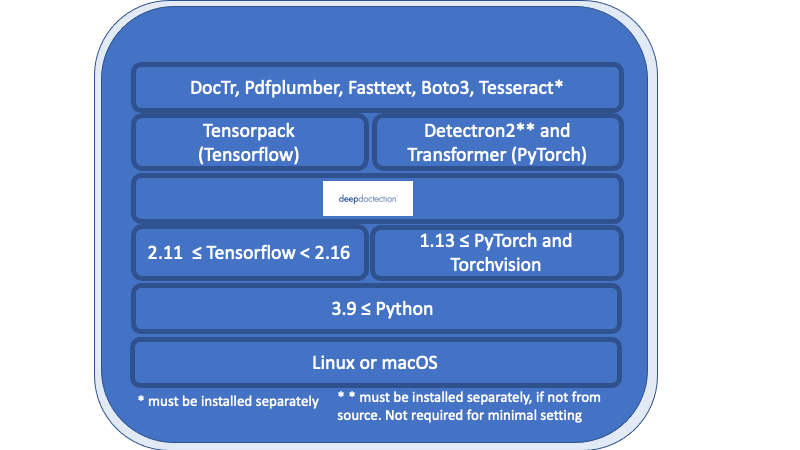
Todo en la descripción general enumerada debajo de la capa de médica profunda son los requisitos necesarios y deben instalarse por separado.
Linux o macOS. (Windows no es compatible pero hay un Dockerfile disponible)
Python> = 3.9
1.13 <= Pytorch o 2.11 <= TensorFlow <2.16. (Para las versiones más bajas de TensorFlow, el código solo se ejecutará en una GPU). En general, si desea entrenar o ajustar modelos, se requiere una GPU.
Con respecto al marco de aprendizaje profundo, debe decidir entre TensorFlow y Pytorch.
El motor Tesseract OCR se usará a través de un envoltorio de Python. El motor central debe instalarse por separado.
Para la liberación v.0.34.0 y debajo de la médica profunda utiliza envoltorios de Python para Poppler para convertir los documentos PDF en imágenes. Para la versión v.0.35.0 Esta dependencia será opcional.
La siguiente descripción general muestra la disponibilidad de los modelos junto con el marco DL.
| Tarea | Pytorch | Antorchscript | Flujo tensor |
|---|---|---|---|
| Detección de diseño a través de Detectron2/TensorPack | ✅ | ✅ (solo CPU) | ✅ (solo GPU) |
| Reconocimiento de la tabla a través de Detectron2/TensorPack | ✅ | ✅ (solo CPU) | ✅ (solo GPU) |
| Transformador de tabla a través de Transformers | ✅ | ||
| Doctrar | ✅ | ✅ | |
| Layoutlm (V1, V2, V3, XLM) a través de Transformers | ✅ |
Recomendamos usar un entorno virtual. Puede instalar el paquete a través de PIP o desde la fuente.
Si desea comenzar con una configuración mínima (por ejemplo, ejecutar el analizador de médicos profundos con la configuración predeterminada o probar el 'portátil iniciado'), instale la médica profunda con
pip install deepdoctection
Si desea utilizar el marco TensorFlow, instale TensorPack por separado. Detectron2 no se instalará y los modelos de diseño/ modelos de reconocimiento de tabla se ejecutarán con TorchScript en una CPU.
La siguiente instalación le brindará todos los modelos disponibles dentro del marco de aprendizaje profundo, así como todos los modelos que son independientes de TensorFlow/Pytorch. Tenga en cuenta que las dependencias son muy complejas. Sin embargo, nos esforzamos por mantener los requisitos actualizados.
Para TensorFlow , corre
pip install deepdoctection[tf]
Para Pytorch ,
Primero instale Detectron2 por separado, ya que no se distribuye a través de PYPI. Revise las instrucciones aquí. Luego corre
pip install deepdoctection[pt]
Esto instalará una médica profunda con todas las dependencias enumeradas por encima de la capa de médica profunda . Use esta configuración, si desea comenzar o desea explorar todas las funciones.
Si desea tener más control con su instalación y está buscando menos dependencias, instale un médico profundo con la configuración básica solamente.
pip install deepdoctection
Esto ignorará todas las bibliotecas de modelos (capas sobre la capa de doctección profunda en el diagrama) y usted será responsable de instalarlas usted mismo. Tenga en cuenta que no podrá ejecutar ninguna tubería con esta configuración.
Para obtener más información, consulte las instrucciones de instalación completas .
Descargue el repositorio o el clon a través de
git clone https://github.com/deepdoctection/deepdoctection.git
Para comenzar con TensorFlow , corre:
cd deepdoctection
pip install ".[tf]"
La instalación de la configuración completa de Pytorch desde la fuente también instalará Detectron2 para usted:
cd deepdoctection
pip install ".[source-pt]"
A partir del lanzamiento v.0.27.0 , las imágenes de Docker preexistentes se pueden descargar desde Docker Hub.
docker pull deepdoctection/deepdoctection:<release_tag>
Para iniciar el contenedor, puede usar el archivo Docker Compose ./docker/pytorch-gpu/docker-compose.yaml . En el archivo .env proporcionado, especifique el directorio de host donde se debe almacenar el caché de la médica profunda . Este directorio se montará. Además, especifique un directorio de trabajo para montar archivos que se procesarán en el contenedor.
docker compose up -d
comenzará el contenedor.
Agradecemos a todas las bibliotecas que proporcionan código de alta calidad y modelos previamente capacitados. Sin, hubiera sido imposible desarrollar este marco.
Nos esforzamos por eliminar los errores. También sabemos que el código no está libre de problemas. Agradecemos todos los problemas relevantes para este repositorio e intentamos abordarlos lo más rápido posible. Las correcciones o mejoras de errores se implementarán en una nueva versión cada 10 a 12 semanas.
... Puede apoyar fácilmente el proyecto haciéndolo más visible. Dejar una estrella o una recomendación ayudará.
Distribuido bajo la licencia Apache 2.0. Consulte la licencia para obtener información adicional.


