textclassification-keras
รหัสที่เก็บข้อมูลนี้ใช้ รูปแบบการเรียนรู้ที่ หลากหลายสำหรับ การจำแนกประเภทข้อความ โดยใช้ Keras Framework ซึ่งรวมถึง: fasttext , textcnn , textrnn , textbirnn , textattbirnn , han , rcnn , rcnnvariant ฯลฯ นอกเหนือจากการใช้งานแบบจำลอง
คำแนะนำ
- สิ่งแวดล้อม
- การใช้งาน
- แบบอย่าง
- Fastext
- ข้อความ
- textrnn
- textbirnn
- Textattbirnn
- ฮั่น
- RCNN
- rcnnvariant
- จะดำเนินการต่อ ...
- อ้างอิง
สิ่งแวดล้อม
- Python 3.7
- numpy 1.17.2
- Tensorflow 2.0.1
การใช้งาน
รหัสทั้งหมดอยู่ในไดเรกทอรี /model และแต่ละรุ่นมีไดเรกทอรีที่สอดคล้องกันซึ่งมีการวางโมเดลและแอปพลิเคชัน
ตัวอย่างเช่นโมเดลและแอปพลิเคชันของ fasttext อยู่ภายใต้ /model/FastText ส่วนโมเดลคือ fast_text.py และส่วนแอปพลิเคชันคือ main.py
แบบอย่าง
1 fasttext
FastText ถูกเสนอในถุงกระดาษสำหรับการจำแนกข้อความที่มีประสิทธิภาพ
1.1 คำอธิบายในกระดาษ
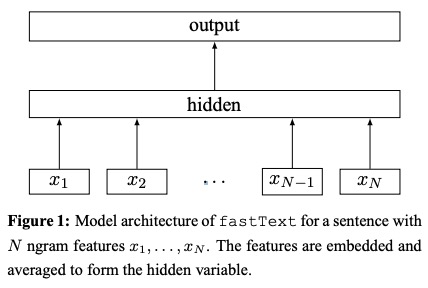
- การใช้ตารางค้นหา กระเป๋าของ NGRAM COVERT เพื่อ การเป็นตัวแทนคำ
- การเป็นตัวแทนของคำจะถูก เฉลี่ย เป็นตัวแทนข้อความซึ่งเป็นตัวแปรที่ซ่อนอยู่
- การแสดงข้อความจะถูกป้อนไปยัง ตัวจําแนกเชิงเส้น
- ใช้ฟังก์ชั่น SoftMax เพื่อคำนวณการกระจายความน่าจะเป็นผ่านคลาสที่กำหนดไว้ล่วงหน้า
1.2 การใช้งานที่นี่
โครงสร้างเครือข่ายของ FastText:
2 textcnn
TextCNN ถูกเสนอในเครือข่ายประสาทแบบ convolutional สำหรับการจำแนกประโยค
2.1 คำอธิบายในกระดาษ
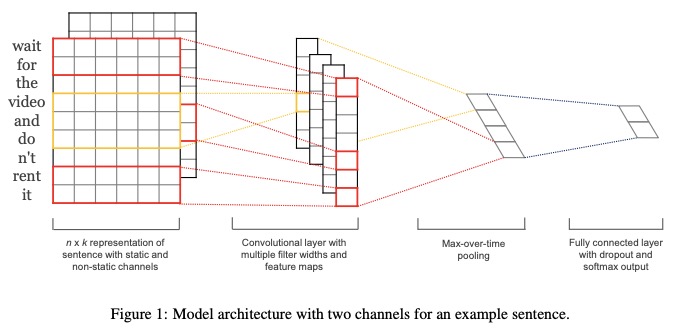
- เป็นตัวแทนประโยคที่มี ช่องสัญญาณคงที่และไม่คงที่
- convolve ด้วยความกว้างของตัวกรองหลายตัวและแผนที่คุณลักษณะ
- ใช้ การรวมสูงสุดเวลา
- ใช้ เลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ ด้วย การออกกลางคัน และ softmax ouput
2.2 การใช้งานที่นี่
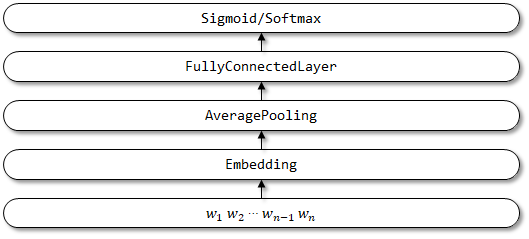
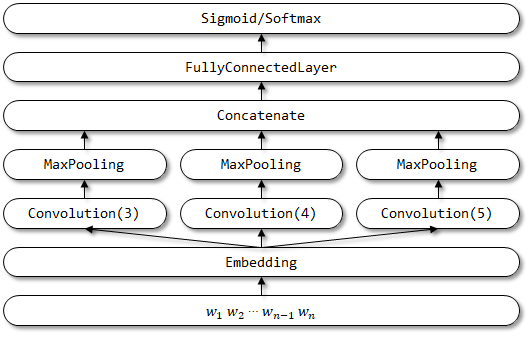
โครงสร้างเครือข่ายของ TextCNN:
3 textrnn
Textrnn ได้รับการกล่าวถึงในเครือข่ายประสาทที่เกิดขึ้นซ้ำสำหรับการจำแนกข้อความด้วยการเรียนรู้แบบหลายงาน
3.1 คำอธิบายในกระดาษ
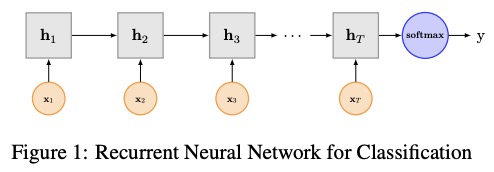
3.2 การใช้งานที่นี่
โครงสร้างเครือข่ายของ textrnn:
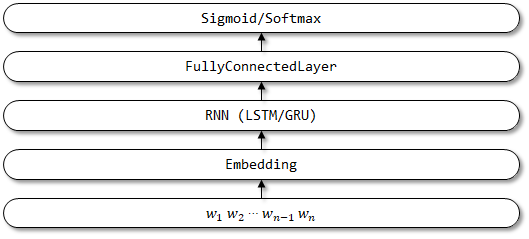
4 textbirnn
TextBirnn เป็นรุ่นที่ได้รับการปรับปรุงตาม textrnn มันปรับปรุงเลเยอร์ RNN ในโครงสร้างเครือข่ายเป็นเลเยอร์ RNN แบบสองทิศทาง หวังว่าไม่เพียง แต่ข้อมูลการเข้ารหัสไปข้างหน้าเท่านั้น แต่ยังสามารถพิจารณาข้อมูลการเข้ารหัสย้อนกลับได้ ยังไม่พบเอกสารที่เกี่ยวข้อง
โครงสร้างเครือข่ายของ textbirnn:
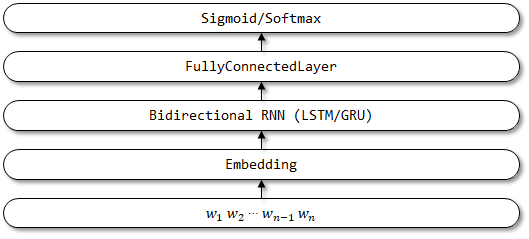
5 Textattbirnn
Textattbirnn เป็นแบบจำลองที่ได้รับการปรับปรุงซึ่งแนะนำกลไกความสนใจตาม TextBirnn สำหรับเวกเตอร์การเป็นตัวแทนที่ได้รับจากการเข้ารหัส RNN แบบสองทิศทางแบบจำลองสามารถมุ่งเน้นไปที่ข้อมูลที่เกี่ยวข้องกับการตัดสินใจผ่านกลไกความสนใจมากที่สุด กลไกความสนใจได้รับการเสนอครั้งแรกในการแปลเครื่องประสาทกระดาษโดยการเรียนรู้ร่วมกันเพื่อจัดตำแหน่งและแปลและการใช้กลไกความสนใจที่นี่จะถูกอ้างถึงเครือข่ายฟีดไปข้างหน้ากระดาษนี้ด้วยความสนใจสามารถแก้ปัญหาหน่วยความจำระยะยาวได้
5.1 คำอธิบายในกระดาษ
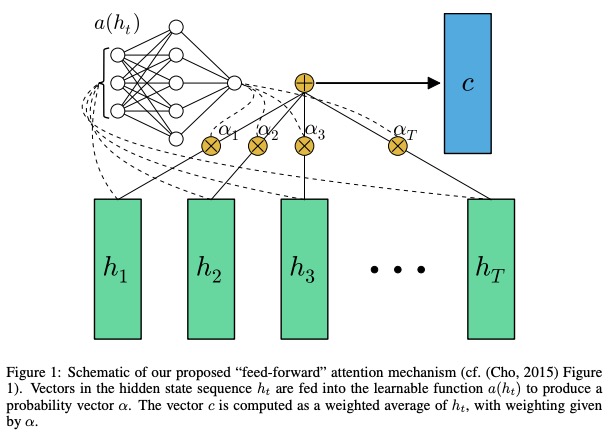
ในเครือข่ายฟีดไปข้างหน้ากระดาษที่ให้ความสนใจสามารถแก้ปัญหาหน่วยความจำระยะยาวได้ ความสนใจไปข้างหน้าฟีด จะง่ายขึ้นดังนี้
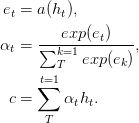
ฟังก์ชั่น a ฟังก์ชั่นที่เรียนรู้ได้รับการยอมรับว่าเป็น เครือข่ายไปข้างหน้าฟีด ในสูตรนี้ความสนใจสามารถมองเห็นได้ว่าเป็นการสร้างการฝังความยาวคงที่ c ของลำดับอินพุตโดยการคำนวณ ค่าเฉลี่ยถ่วงน้ำหนักแบบปรับตัว ของลำดับสถานะ h
5.2 การใช้งานที่นี่
การใช้ความสนใจไม่ได้อธิบายไว้ที่นี่โปรดดูที่ซอร์สโค้ดโดยตรง
โครงสร้างเครือข่ายของ Textattbirnn:

6 ฮั่น
Han ถูกเสนอในเครือข่ายความสนใจแบบลำดับชั้นกระดาษสำหรับการจำแนกเอกสาร
6.1 คำอธิบายในกระดาษ
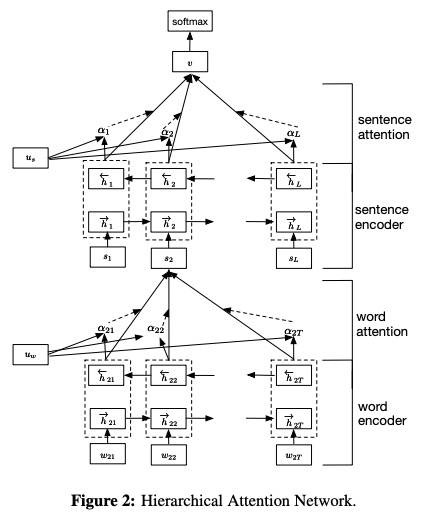
- เครื่องเข้ารหัสคำ การเข้ารหัสโดย GRU แบบสองทิศทาง คำอธิบายประกอบสำหรับคำที่กำหนดนั้นได้มาจากการเชื่อมต่อสถานะซ่อนเร้นไปข้างหน้าและสถานะซ่อนเร้นไปข้างหน้าซึ่งสรุปข้อมูลของประโยคทั้งหมดที่มีศูนย์กลางอยู่ที่คำในขั้นตอนปัจจุบัน
- ความสนใจของคำ ด้วยฟังก์ชั่น MLP และ Softmax แบบหนึ่งชั้นจะเปิดใช้งานการคำนวณน้ำหนักความสำคัญปกติเหนือคำอธิบายประกอบคำก่อนหน้านี้ จากนั้นคำนวณเวกเตอร์ประโยคเป็น ผลรวมถ่วงน้ำหนัก ของคำอธิบายประกอบคำตามน้ำหนัก
- ตัวเข้ารหัสประโยค ในทำนองเดียวกันกับเครื่องเข้ารหัส Word ให้ใช้ GRU แบบสองทิศทาง เพื่อเข้ารหัสประโยคเพื่อรับคำอธิบายประกอบสำหรับประโยค
- ความสนใจประโยค เช่นเดียวกับคำให้ความสนใจของ Word ใช้ฟังก์ชั่น MLP และ Softmax แบบหนึ่งชั้นเพื่อให้ได้น้ำหนักมากกว่าคำอธิบายประกอบประโยค จากนั้นคำนวณ ผลรวมถ่วงน้ำหนัก ของคำอธิบายประกอบประโยคตามน้ำหนักเพื่อรับเวกเตอร์เอกสาร
- การจำแนกเอกสาร ใช้ฟังก์ชั่น SoftMax เพื่อคำนวณความน่าจะเป็นของคลาสทั้งหมด
6.2 การใช้งานที่นี่
การดำเนินการตามความสนใจที่นี่ขึ้นอยู่กับ Feedforwardattention ซึ่งเหมือนกับความสนใจใน Textattbirnn
โครงสร้างเครือข่ายของฮัน:
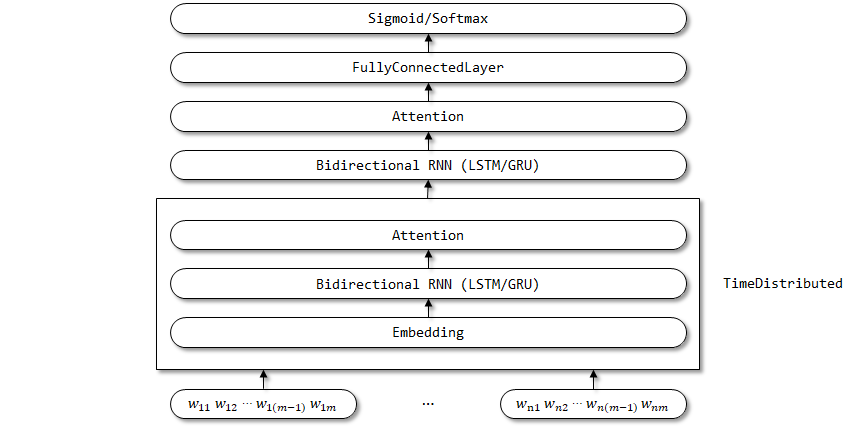
wrapper timedistributed ถูกนำมาใช้ที่นี่เนื่องจากพารามิเตอร์ของการฝัง, RNN แบบสองทิศทางและชั้นความสนใจคาดว่าจะถูกแชร์ในมิติขั้นตอนเวลา
7 RCNN
RCNN ถูกเสนอในเครือข่ายประสาทที่เกิดขึ้นซ้ำของกระดาษสำหรับการจำแนกประเภทข้อความ
7.1 คำอธิบายในกระดาษ
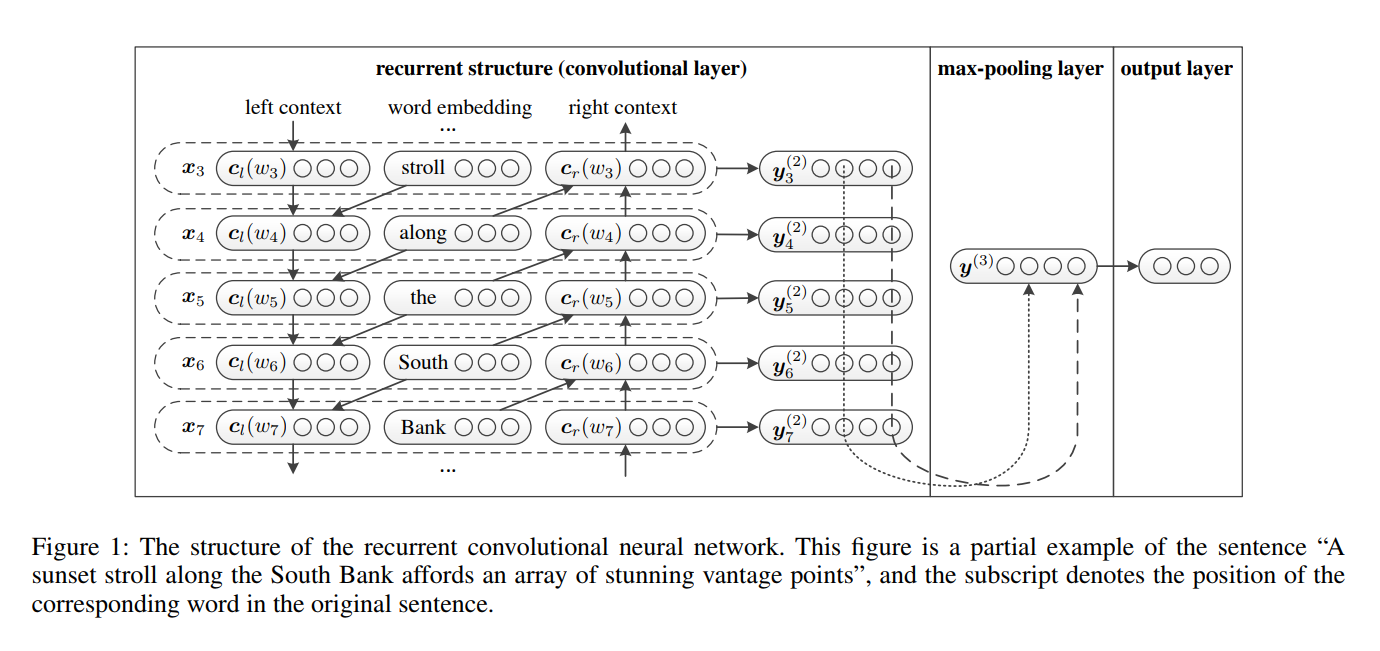
- การเรียนรู้คำเป็นตัวแทน RCNN ใช้โครงสร้างที่เกิดขึ้นอีกซึ่งเป็น เครือข่ายประสาทแบบสองทิศทาง เพื่อจับภาพบริบท จากนั้นรวมคำและบริบทเพื่อนำเสนอคำ และใช้ การเปลี่ยนแปลงเชิงเส้น พร้อมกับการเปิดใช้งาน
tanh fucntion กับการเป็นตัวแทน - การเรียนรู้การแสดงข้อความ เมื่อการคำนวณคำทั้งหมดของคำถูกคำนวณมันจะใช้เลเยอร์ การเจาะสูงสุด องค์ประกอบเพื่อจับภาพข้อมูลที่สำคัญที่สุดตลอดทั้งข้อความ ในที่สุดทำการ แปลงเชิงเส้น และใช้ฟังก์ชั่น SoftMax
7.2 การใช้งานที่นี่
โครงสร้างเครือข่ายของ RCNN:
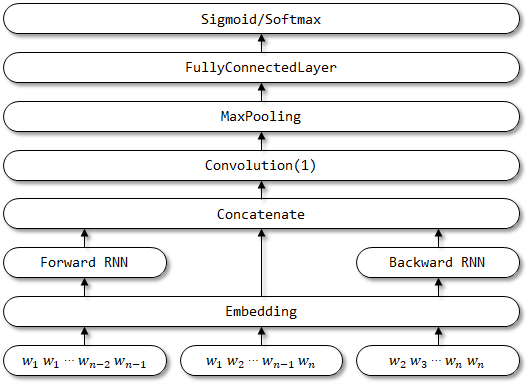
8 rcnnvariant
Rcnnvariant เป็นแบบจำลองที่ได้รับการปรับปรุงโดยใช้ RCNN พร้อมการปรับปรุงต่อไปนี้ ยังไม่พบเอกสารที่เกี่ยวข้อง
- อินพุตทั้งสามถูกเปลี่ยนเป็น อินพุตเดียว อินพุตของบริบทซ้ายและขวาจะถูกลบออก
- ใช้ LSTM/GRU แบบสองทิศทาง แทน RNN แบบดั้งเดิมสำหรับการเข้ารหัสบริบท
- ใช้ CNN แบบหลายช่องทาง เพื่อเป็นตัวแทนของเวกเตอร์ความหมาย
- แทนที่เลเยอร์การเปิดใช้งาน TANH ด้วย เลเยอร์การเปิดใช้งาน RELU
- ใช้ทั้ง AveragePooling และ MaxPooling
โครงสร้างเครือข่ายของ rcnnvariant:
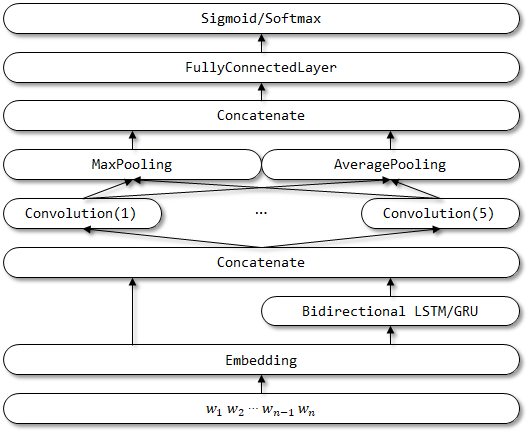
จะดำเนินการต่อ ...
อ้างอิง
- กระเป๋าของเคล็ดลับสำหรับการจำแนกประเภทข้อความที่มีประสิทธิภาพ
- ตัวอย่าง keras imdb fasttext
- เครือข่ายประสาท Convolutional สำหรับการจำแนกประโยค
- ตัวอย่าง keras imdb cnn
- เครือข่ายประสาทกำเริบสำหรับการจำแนกข้อความด้วยการเรียนรู้หลายงาน
- การแปลเครื่องประสาทโดยร่วมกันเรียนรู้ที่จะจัดตำแหน่งและแปล
- เครือข่ายฟีดไปข้างหน้าด้วยความสนใจสามารถแก้ปัญหาหน่วยความจำระยะยาวบางอย่าง
- ความสนใจของ Cbaziotis
- เครือข่ายความสนใจแบบลำดับชั้นสำหรับการจำแนกเอกสาร
- Richard's Han
- เครือข่ายประสาทแบบ convolutional ที่เกิดขึ้นอีกสำหรับการจำแนกประเภทข้อความ
- rcnn ของ Airalcorn2


