TextClassification-Kera
Repositori kode ini mengimplementasikan berbagai model pembelajaran yang mendalam untuk klasifikasi teks menggunakan kerangka keras , yang meliputi: FastText , TextCnn , Textrnn , TextBirnn , TextattBirnn , Han , RCNN , RCNNVariant , dll. Selain implementasi model, aplikasi yang disederhanakan disertakan.
- Dokumen bahasa Inggris
- 中文文档
Panduan
- Lingkungan
- Penggunaan
- Model
- FastText
- Textcnn
- Textrnn
- TextBirnn
- Textattbirnn
- Han
- Rcnn
- Rcnnvariant
- Untuk dilanjutkan ...
- Referensi
Lingkungan
- Python 3.7
- Numpy 1.17.2
- TensorFlow 2.0.1
Penggunaan
Semua kode terletak di direktori /model , dan setiap jenis model memiliki direktori yang sesuai di mana model dan aplikasi ditempatkan.
Misalnya, model dan aplikasi FastText terletak di bawah /model/FastText , bagian modelnya adalah fast_text.py , dan bagian aplikasi adalah main.py
Model
1 FastText
FastText diusulkan dalam kantong kertas trik untuk klasifikasi teks yang efisien.
1.1 Deskripsi di Kertas
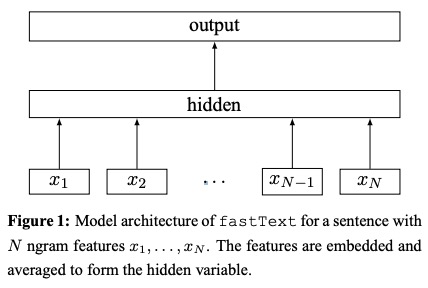
- Menggunakan meja pencarian, tas Ngram yang terselubung ke representasi kata .
- Representasi kata dirata -rata menjadi representasi teks, yang merupakan variabel tersembunyi.
- Representasi teks pada gilirannya diumpankan ke classifier linier .
- Gunakan fungsi softmax untuk menghitung distribusi probabilitas selama kelas yang telah ditentukan.
1.2 Implementasi di sini
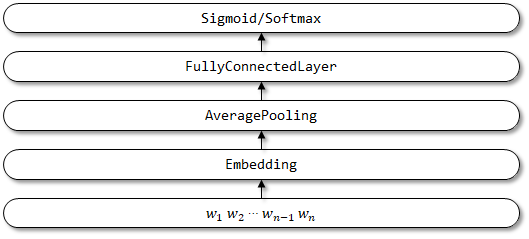
Struktur jaringan FastText:
2 Textcnn
Textcnn diusulkan dalam jaringan neural convolutional networks untuk klasifikasi kalimat.
2.1 Deskripsi di Kertas
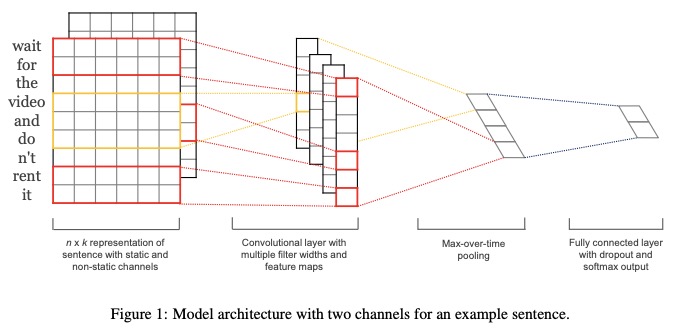
- Mewakili kalimat dengan saluran statis dan non-statis .
- Convolve dengan beberapa lebar filter dan peta fitur.
- Gunakan pooling max-over-time .
- Gunakan lapisan yang sepenuhnya terhubung dengan dropout dan softmax ouput.
2.2 Implementasi di sini
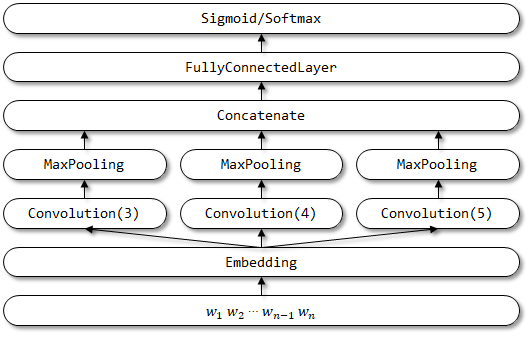
Struktur Jaringan Textcnn:
3 Textrnn
Textrnn telah disebutkan dalam jaringan saraf berulang untuk klasifikasi teks dengan pembelajaran multi-tugas.
3.1 Deskripsi di Kertas
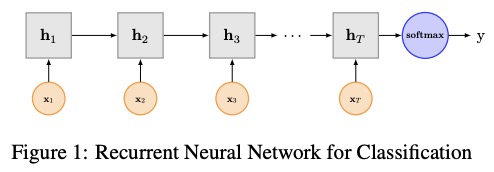
3.2 Implementasi di sini
Struktur Jaringan Textrnn:
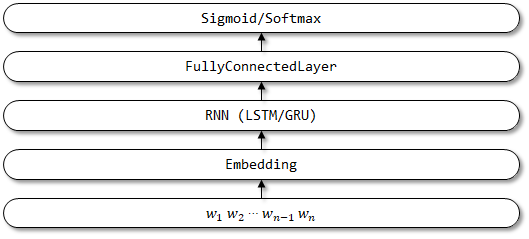
4 TextBirnn
TextBirnn adalah model yang ditingkatkan berdasarkan Textrnn. Ini meningkatkan lapisan RNN dalam struktur jaringan menjadi lapisan RNN dua arah. Diharapkan bahwa tidak hanya informasi penyandian ke depan tetapi juga informasi pengkodean balik dapat dipertimbangkan. Belum ada makalah terkait.
Struktur jaringan TextBirnn:
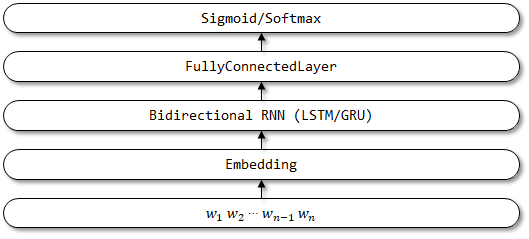
5 Textattbirnn
Textattbirnn adalah model yang lebih baik yang memperkenalkan mekanisme perhatian berdasarkan TextBirnn. Untuk vektor representasi yang diperoleh dengan encoder RNN dua arah, model dapat fokus pada informasi yang paling relevan dengan pengambilan keputusan melalui mekanisme perhatian. Mekanisme perhatian pertama kali diusulkan dalam makalah terjemahan mesin saraf dengan belajar bersama untuk menyelaraskan dan menerjemahkan, dan implementasi mekanisme perhatian di sini dirujuk ke jaringan umpan-depan kertas ini dengan perhatian dapat menyelesaikan beberapa masalah memori jangka panjang.
5.1 Deskripsi di Kertas
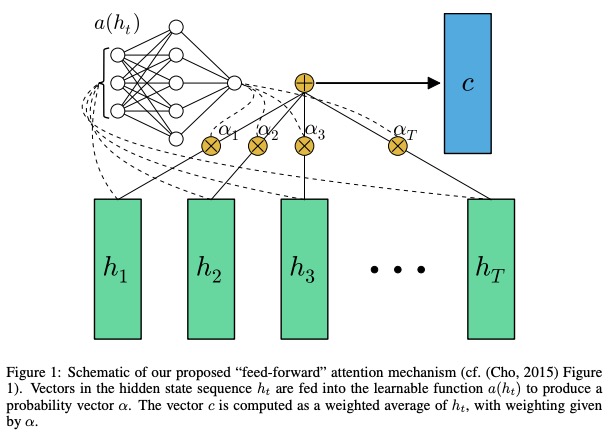
Dalam jaringan feed-forward kertas dengan perhatian dapat menyelesaikan beberapa masalah memori jangka panjang, perhatian ke depan disederhanakan sebagai berikut,
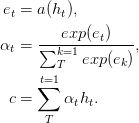
Fungsi a , fungsi yang dapat dipelajari, diakui sebagai jaringan forward forward . Dalam formulasi ini, perhatian dapat dilihat sebagai menghasilkan embedding panjang tetap c dari urutan input dengan menghitung rata-rata tertimbang adaptif dari urutan keadaan h
5.2 Implementasi di sini
Implementasi perhatian tidak dijelaskan di sini, silakan merujuk ke kode sumber secara langsung.
Struktur jaringan Textattbirnn:

6 Han
Han diusulkan dalam jaringan perhatian hirarkis kertas untuk klasifikasi dokumen.
6.1 Deskripsi di Kertas
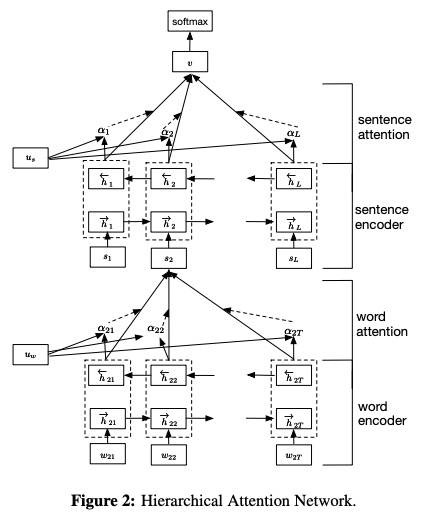
- Word Encoder . Pengkodean oleh Bidirectional Gru , anotasi untuk kata yang diberikan diperoleh dengan menggabungkan keadaan tersembunyi ke depan dan keadaan tersembunyi terbelakang, yang merangkum informasi dari seluruh kalimat yang berpusat di sekitar kata dalam langkah waktu saat ini.
- Perhatian kata . Dengan fungsi MLP dan softmax satu lapis, dimungkinkan untuk menghitung bobot kepentingan yang dinormalisasi dibandingkan anotasi kata sebelumnya. Kemudian, hitung vektor kalimat sebagai jumlah tertimbang dari kata anotasi berdasarkan bobot.
- Encoder kalimat . Dengan cara yang sama dengan Word Encoder, gunakan GRU dua arah untuk menyandikan kalimat untuk mendapatkan anotasi untuk kalimat.
- Perhatian kalimat . Mirip dengan perhatian kata, gunakan fungsi MLP dan softmax satu lapis untuk mendapatkan bobot atas anotasi kalimat. Kemudian, hitung sejumlah tertimbang dari anotasi kalimat berdasarkan bobot untuk mendapatkan vektor dokumen.
- Klasifikasi Dokumen . Gunakan fungsi softmax untuk menghitung probabilitas semua kelas.
6.2 Implementasi di sini
Implementasi perhatian di sini didasarkan pada feedforwardtera, yang sama dengan perhatian dalam tekstbirnn.
Struktur Jaringan Han:
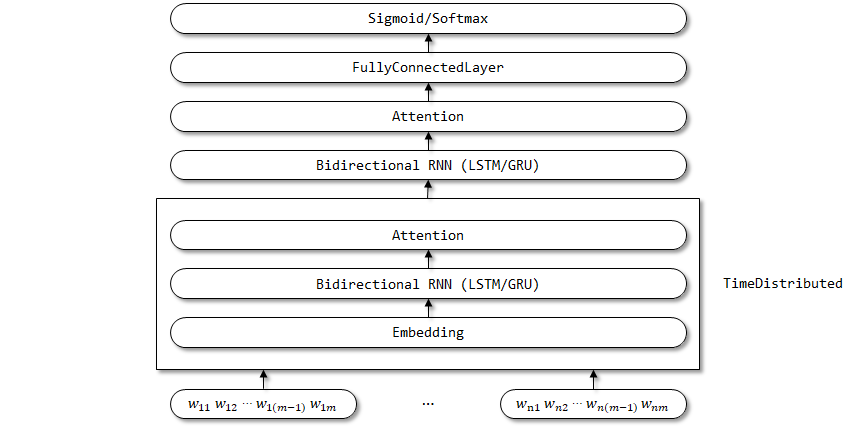
Pembungkus yang didistribusikan diatur di sini digunakan di sini, karena parameter embedding, RNN dua arah, dan lapisan perhatian diharapkan dibagi pada dimensi langkah waktu.
7 rcnn
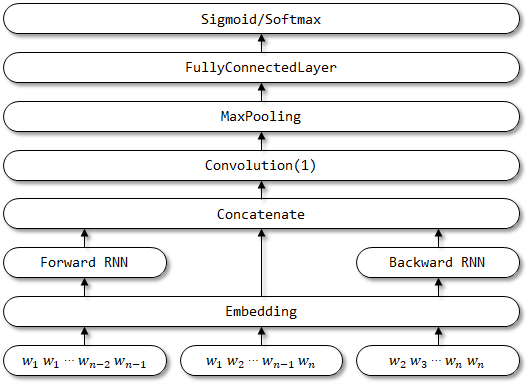
RCNN diusulkan dalam kertas saraf konvolusional berulang untuk klasifikasi teks.
7.1 Deskripsi di Kertas
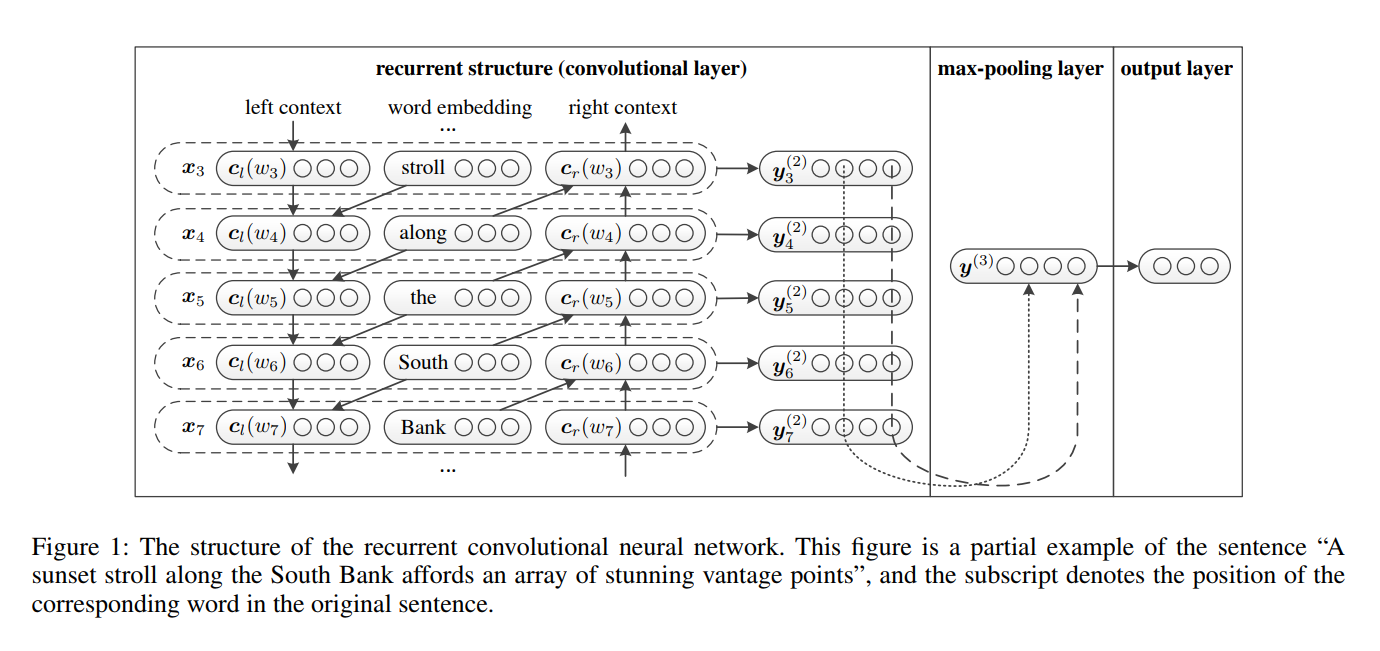
- Pembelajaran Representasi Kata . RCNN menggunakan struktur berulang, yang merupakan jaringan saraf berulang dua arah , untuk menangkap konteks. Kemudian, gabungkan kata dan konteksnya untuk menyajikan kata tersebut. Dan menerapkan transformasi linier bersama dengan aktivasi
tanh ke representasi. - Pembelajaran Representasi Teks . Ketika semua representasi kata dihitung, itu menerapkan lapisan pemecahan-maks elemen untuk menangkap informasi paling penting di seluruh teks. Akhirnya, lakukan transformasi linier dan terapkan fungsi Softmax .
7.2 Implementasi di sini
Struktur Jaringan RCNN:
8 rcnnvariant
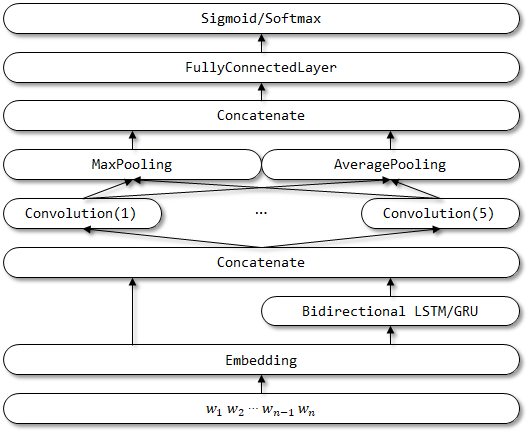
RCNNVariant adalah model yang ditingkatkan berdasarkan RCNN dengan perbaikan berikut. Belum ada makalah terkait.
- Tiga input diubah menjadi input tunggal . Input konteks kiri dan kanan dihapus.
- Gunakan BIDIRECTIONAL LSTM/GRU sebagai ganti RNN tradisional untuk konteks pengkodean.
- Gunakan CNN multi-channel untuk mewakili vektor semantik.
- Ganti lapisan aktivasi TANH dengan lapisan aktivasi relu .
- Gunakan rata -rata rata -rata dan maxpooling .
Struktur jaringan rcnnvariant:
Untuk dilanjutkan ...
Referensi
- Tas trik untuk klasifikasi teks yang efisien
- Contoh keras imdb fasttext
- Jaringan Saraf Konvolusional untuk Klasifikasi Kalimat
- Contoh keras imdb cnn
- Jaringan saraf berulang untuk klasifikasi teks dengan pembelajaran multi-tugas
- Terjemahan mesin saraf dengan belajar bersama untuk menyelaraskan dan menerjemahkan
- Jaringan feed-forward dengan perhatian dapat menyelesaikan beberapa masalah memori jangka panjang
- perhatian cbaziotis
- Jaringan perhatian hierarkis untuk klasifikasi dokumen
- Han Richard
- Jaringan saraf konvolusional berulang untuk klasifikasi teks
- Airalcorn2's RCNN


