TextClassification-keras
Ce référentiel de code implémente une variété de modèles d'apprentissage en profondeur pour la classification du texte à l'aide du framework Keras , qui comprend: FastText , TextCnn , Textrnn , TextBirnn , TextAttBirnn , Han , RCNN , RCNNVariant , etc. En plus de l'implémentation du modèle, une application simplifiée est incluse.
Conseils
- Environnement
- Usage
- Modèle
- Texte rapide
- Textcnn
- Textrnn
- TextBirnn
- Textattbirnn
- Han
- RCNN
- Rcnnvariant
- À suivre...
- Référence
Environnement
- Python 3.7
- Numpy 1.17.2
- TensorFlow 2.0.1
Usage
Tous les codes sont situés dans le répertoire /model , et chaque type de modèle a un répertoire correspondant dans lequel le modèle et l'application sont placés.
Par exemple, le modèle et l'application de FastText sont situés sous /model/FastText , la partie du modèle est fast_text.py et la partie de l'application est main.py
Modèle
1 FastText
FastText a été proposé dans le sac en papier des astuces pour une classification efficace du texte.
1.1 Description dans le papier
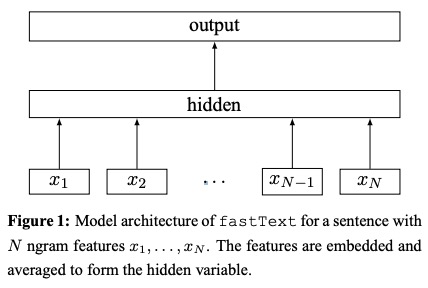
- À l'aide d'une table de recherche, des sacs de Ngram Covert aux représentations de mots .
- Les représentations de mots sont moyennées en une représentation de texte, qui est une variable cachée.
- La représentation du texte est à son tour nourrie en un classificateur linéaire .
- Utilisez la fonction Softmax pour calculer la distribution de probabilité sur les classes prédéfinies.
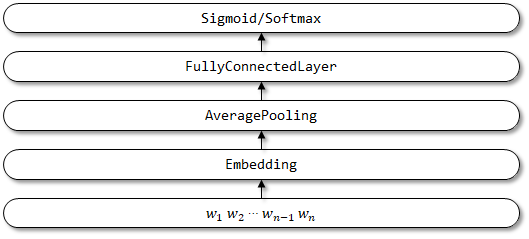
1.2 Implémentation ici
Structure du réseau de FastText:
2 textcnn
TextCNN a été proposé dans les réseaux de neurones convolutionnels du papier pour la classification des phrases.
2.1 Description dans le papier
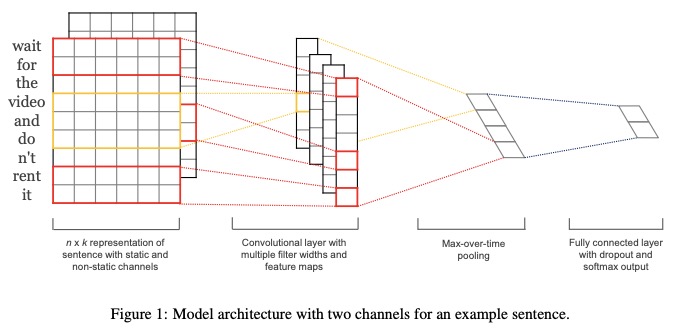
- Représenter une phrase avec des canaux statiques et non statiques .
- Convolutionz avec plusieurs largeurs de filtres et cartes de fonctionnalités.
- Utilisez la mise en commun maximum de temps .
- Utilisez une couche entièrement connectée avec un dépôt et un softmax ouput.
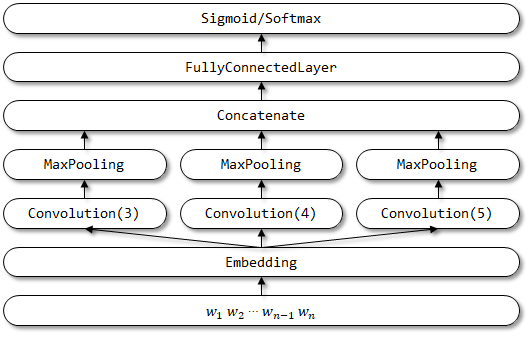
2.2 Implémentation ici
Structure du réseau de textcnn:
3 textrnn
Textrnn a été mentionné dans le réseau de neurones récurrent papier pour la classification du texte avec un apprentissage multi-tâches.
3.1 Description dans le papier
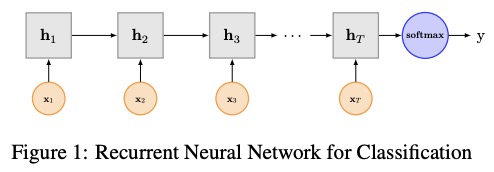
3.2 Implémentation ici
Structure du réseau de Textrnn:
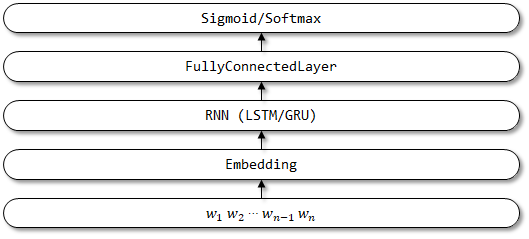
4 textbirnn
TextBirnn est un modèle amélioré basé sur Textrnn. Il améliore la couche RNN dans la structure du réseau en une couche RNN bidirectionnelle. Il est à espérer que non seulement les informations d'encodage vers l'avant, mais aussi les informations d'encodage inverse pourront être prises en compte. Aucun article connexe n'a encore été trouvé.
Structure du réseau de TextBirnn:
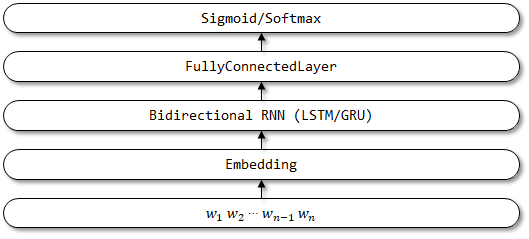
5 textattbirnn
TextAttBirnn est un modèle amélioré qui introduit un mécanisme d'attention basé sur TextBirnn. Pour les vecteurs de représentation obtenus par Encodeur RNN bidirectionnel, le modèle peut se concentrer sur les informations les plus pertinentes pour la prise de décision grâce au mécanisme d'attention. Le mécanisme d'attention a été proposé pour la première fois dans la traduction de la machine neuronale de l'article en apprenant conjointement à s'aligner et à traduire, et la mise en œuvre du mécanisme d'attention ici est référée à ces réseaux d'articles pour les rédacteurs avec l'attention peut résoudre certains problèmes de mémoire à long terme.
5.1 Description dans le papier
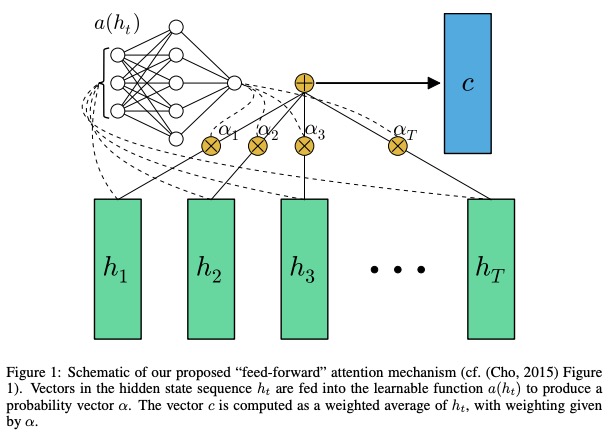
Dans les réseaux de Feed-Forward avec l'attention peuvent résoudre certains problèmes de mémoire à long terme, l' attention de la transmission est simplifiée comme suit,
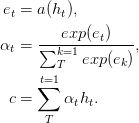
La fonction a , une fonction apprenable, est reconnue comme un réseau de transfert de flux . Dans cette formulation, l'attention peut être considérée comme produisant une intégration de longueur fixe c de la séquence d'entrée en calculant une moyenne pondérée adaptative de la séquence d'état h
5.2 Implémentation ici
L'implémentation de l'attention n'est pas décrite ici, veuillez vous référer directement au code source.
Structure du réseau de TextAttBirnn:

6 Han
Han a été proposé dans les réseaux d'attention hiérarchiques de l'article pour la classification des documents.
6.1 Description dans le papier
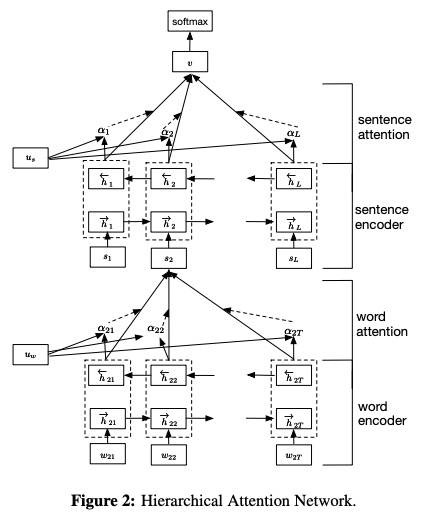
- Encodeur de mots . Encodage par GRU bidirectionnel , une annotation pour un mot donné est obtenue en concaténant l'état caché vers l'avant et l'état caché vers l'arrière, qui résume les informations de la phrase entière centrée sur le mot actuel.
- MOT ATTENTION . Par une fonction MLP et Softmax à une couche, il est permis de calculer les poids d'importance normalisés au cours des annotations de mots précédentes. Ensuite, calculez le vecteur de phrase comme une somme pondérée des annotations du mot en fonction des poids.
- Encodeur de phrase . De la même manière avec Word Encoder, utilisez un GRU bidirectionnel pour coder les phrases pour obtenir une annotation pour une phrase.
- Attention aux phrases . Similaire avec l'attention des mots, utilisez une fonction MLP et Softmax à une couche pour obtenir les poids sur les annotations de la phrase. Ensuite, calculez une somme pondérée des annotations de phrases en fonction des poids pour obtenir le vecteur de document.
- Classification des documents . Utilisez la fonction Softmax pour calculer la probabilité de toutes les classes.
6.2 Implémentation ici
La mise en œuvre de l'attention ici est basée sur FeedForwardAntité, qui est la même que l'attention dans TextAttBirnn.
Structure du réseau de Han:
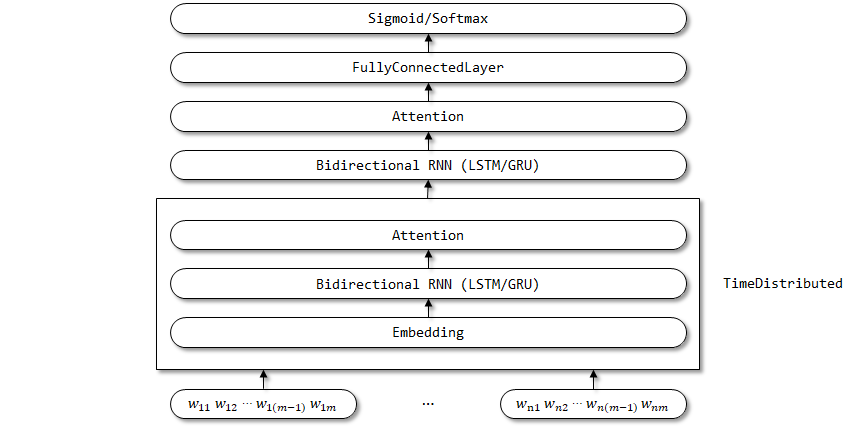
L'écran TimedSistribed est utilisé ici, car les paramètres de l'incorporation, du RNN bidirectionnel et des couches d'attention devraient être partagés sur la dimension de pas de temps.
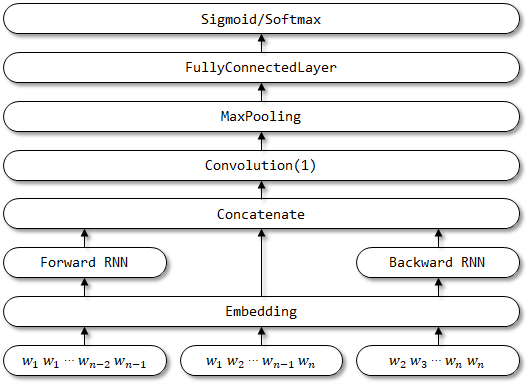
7 RCNN
RCNN a été proposé dans les réseaux de neurones convolutionnels récurrents du papier pour la classification du texte.
7.1 Description dans le papier
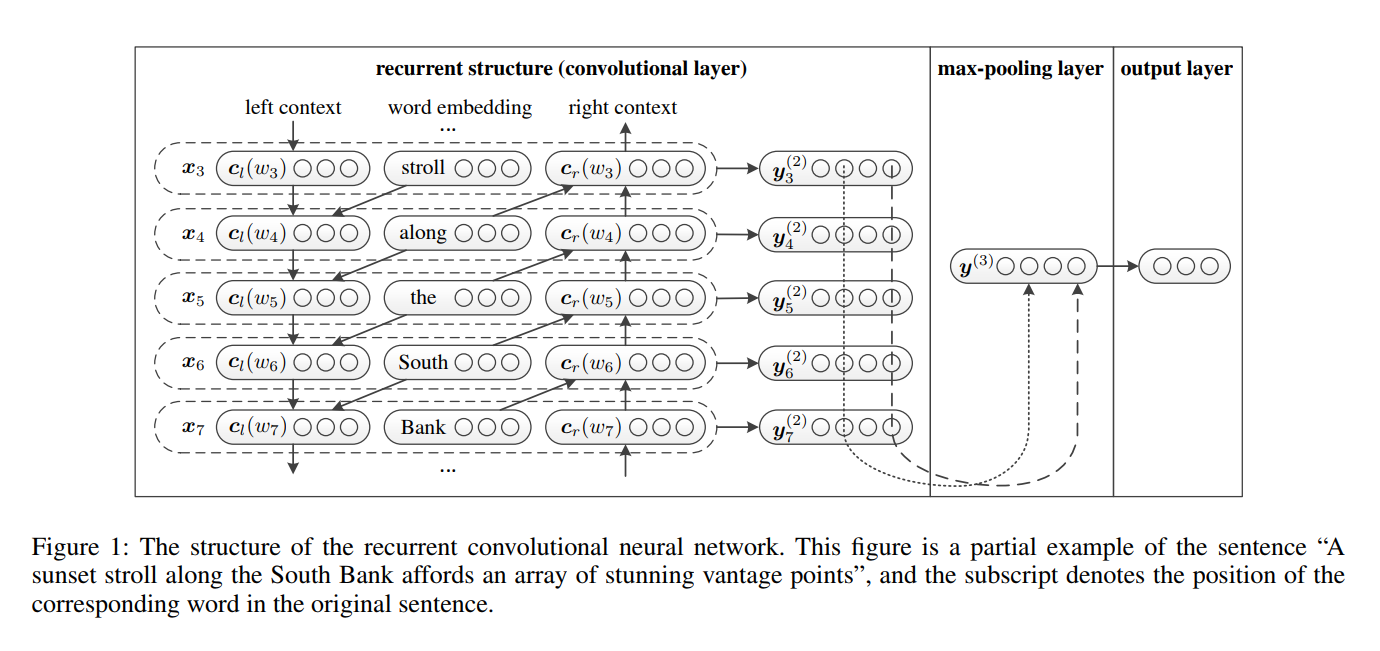
- Représentation des mots Apprentissage . RCNN utilise une structure récurrente, qui est un réseau neuronal récurrent bidirectionnel , pour capturer les contextes. Ensuite, combinez le mot et son contexte pour présenter le mot. Et appliquer une transformation linéaire avec la future d'activation
tanh à la représentation. - Apprentissage de la représentation du texte . Lorsque toutes les représentations des mots sont calculées, elle applique une couche de pools maximum en termes d'élément afin de capturer les informations les plus importantes tout au long du texte. Enfin, effectuez la transformation linéaire et appliquez la fonction Softmax .
7.2 Implémentation ici
Structure du réseau de RCNN:
8 rcnnvariant
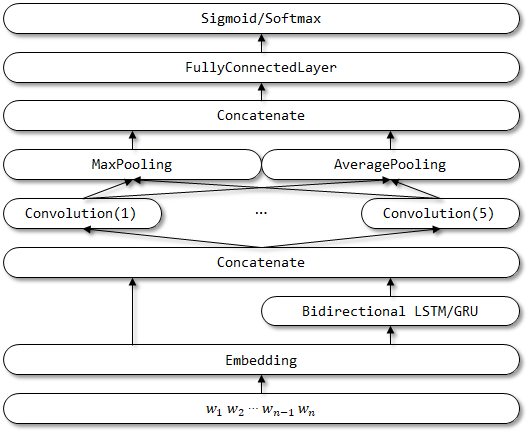
RCNNVariant est un modèle amélioré basé sur le RCNN avec les améliorations suivantes. Aucun article connexe n'a encore été trouvé.
- Les trois entrées sont modifiées en entrée unique . L'entrée des contextes gauche et droite est supprimée.
- Utilisez le LSTM / GRU bidirectionnel au lieu du RNN traditionnel pour le contexte de codage.
- Utilisez le CNN multicanal pour représenter les vecteurs sémantiques.
- Remplacez la couche d'activation TANH par la couche d'activation RELU .
- Utilisez à la fois la moyenne et le maxpool .
Structure du réseau de rcnnvariant:
À suivre...
Référence
- Sac d'astuces pour une classification de texte efficace
- Keras Exemple IMDB FastText
- Réseaux de neurones convolutionnels pour la classification des phrases
- Keras Exemple IMDB CNN
- Réseau neuronal récurrent pour la classification du texte avec apprentissage multi-tâches
- Traduction de machine neurale en apprenant conjointement à aligner et à traduire
- Les réseaux à partage avec l'attention peuvent résoudre certains problèmes de mémoire à long terme
- L'attention de Cbaziotis
- Réseaux d'attention hiérarchiques pour la classification des documents
- Richard's Han
- Réseaux de neurones convolutionnels récurrents pour la classification du texte
- RCNN d'Airalcorn2


