TextClassification Keras
1.0.0
このコードリポジトリは、 Kerasフレームワークを使用したテキスト分類のためのさまざまなディープラーニングモデルを実装します。これには、 FastText 、 TextCNN 、 Textrnn 、 TextBirnn 、 TextAttBirnn 、 Han 、 RCNN 、 RCNNVariantなどが含まれます。モデルの実装に加えて、単純化されたアプリケーションが含まれます。
すべてのコードはディレクトリ/modelにあり、各種類のモデルには、モデルとアプリケーションが配置される対応するディレクトリがあります。
たとえば、FastTextのモデルとアプリケーションは/model/FastTextの下にあり、モデルパーツはfast_text.py 、アプリケーションパーツはmain.pyです。
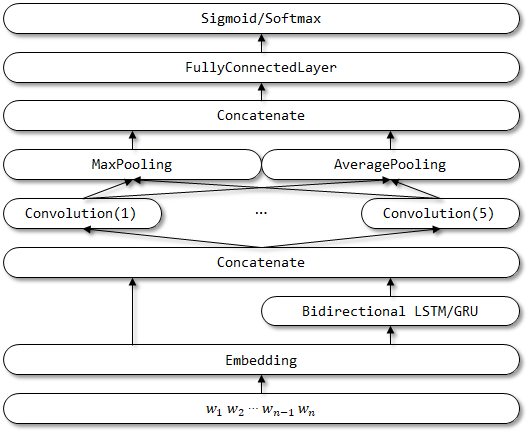
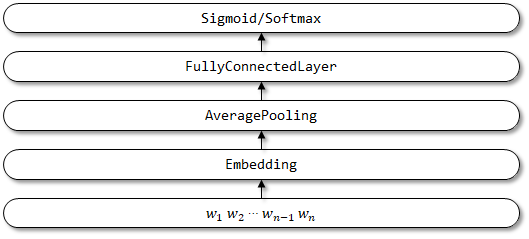
FastTextは、効率的なテキスト分類のためにトリックの紙袋に提案されました。
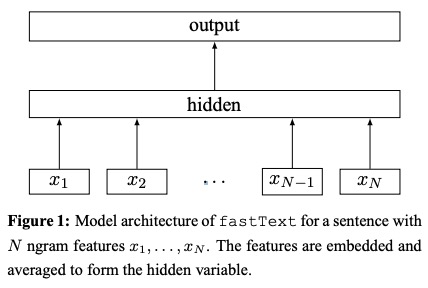
FastTextのネットワーク構造:
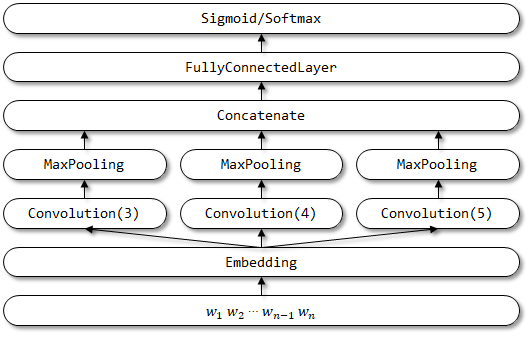
TextCNNは、文の分類のために紙の畳み込みニューラルネットワークで提案されました。
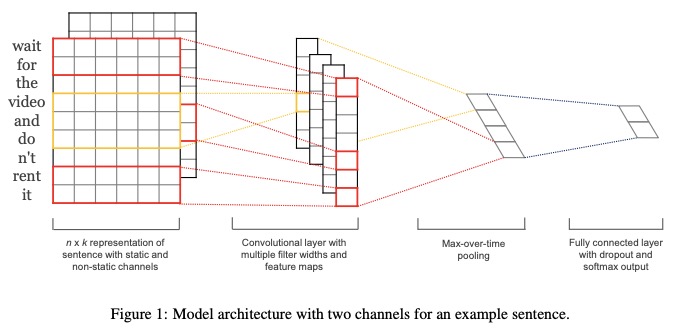
textcnnのネットワーク構造:
Textrnnは、マルチタスク学習を使用したテキスト分類のために、論文再発性ニューラルネットワークで言及されています。
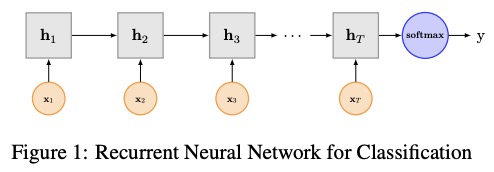
Textrnnのネットワーク構造:
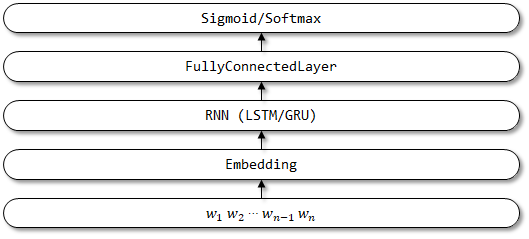
TextBirnnは、Textrnnに基づく改良モデルです。ネットワーク構造内のRNN層を双方向のRNN層に改善します。フォワードエンコード情報だけでなく、逆エンコード情報も考慮できることが期待されています。関連する論文はまだ見つかりませんでした。
TextBirnnのネットワーク構造:
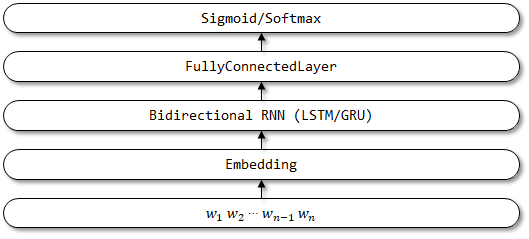
TextAttBirnnは、TextBirnnに基づいた注意メカニズムを導入する改善されたモデルです。双方向RNNエンコーダーによって得られた表現ベクトルの場合、モデルは注意メカニズムを通じて意思決定に最も関連する情報に焦点を当てることができます。注意メカニズムは、紙の神経機械の翻訳で最初に提案され、共同で調整と翻訳を学ぶことができました。ここでの注意メカニズムの実装は、注意を払ったこの論文のフィードフォワードネットワークに言及します。
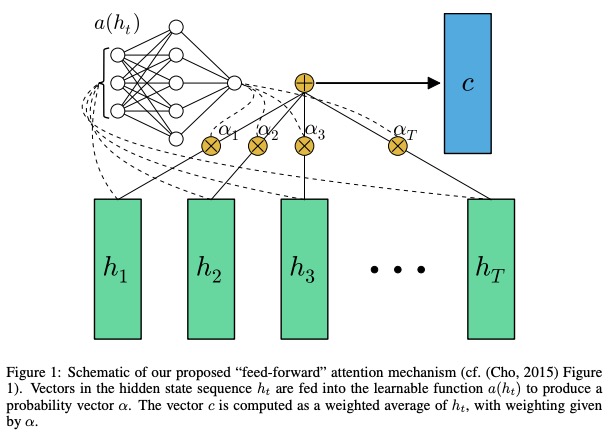
ペーパーフィードフォワードネットワークでは、長期的なメモリの問題を解決することができます。
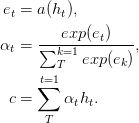
学習可能な関数である関数aは、フィードフォワードネットワークとして認識されます。この定式化では、状態シーケンスhの適応加重平均を計算することにより、入力シーケンスの固定長埋め込みc生成すると注意が向けられます。
注意の実装はここでは説明されていません。ソースコードを直接参照してください。
TextAttBirnnのネットワーク構造:

HANは、ドキュメント分類のために紙の階層的注意ネットワークで提案されました。
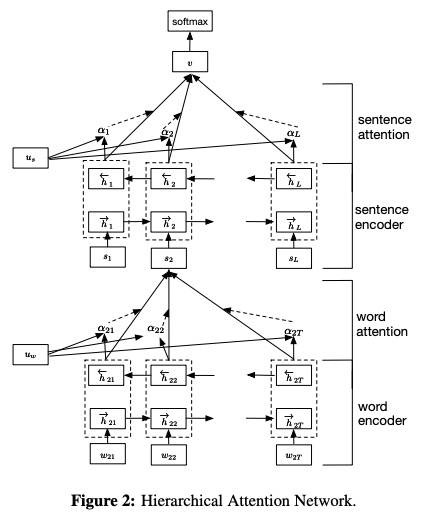
ここでの注意の実装は、feedforwardattentionに基づいています。これは、textattbirnnの注意と同じです。
HANのネットワーク構造:
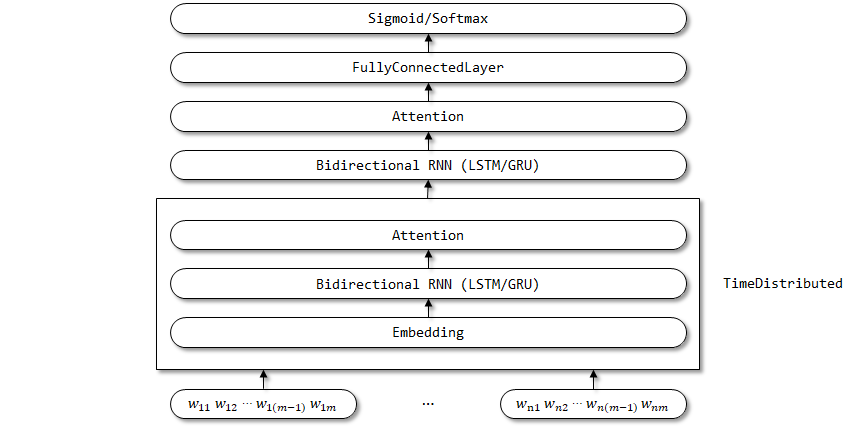
埋め込み、双方向RNN、および注意層のパラメーターがタイムステップディメンションで共有されると予想されるため、TimeDistributedラッパーはここで使用されます。
RCNNは、テキスト分類のために、紙の再発性畳み込みニューラルネットワークで提案されました。
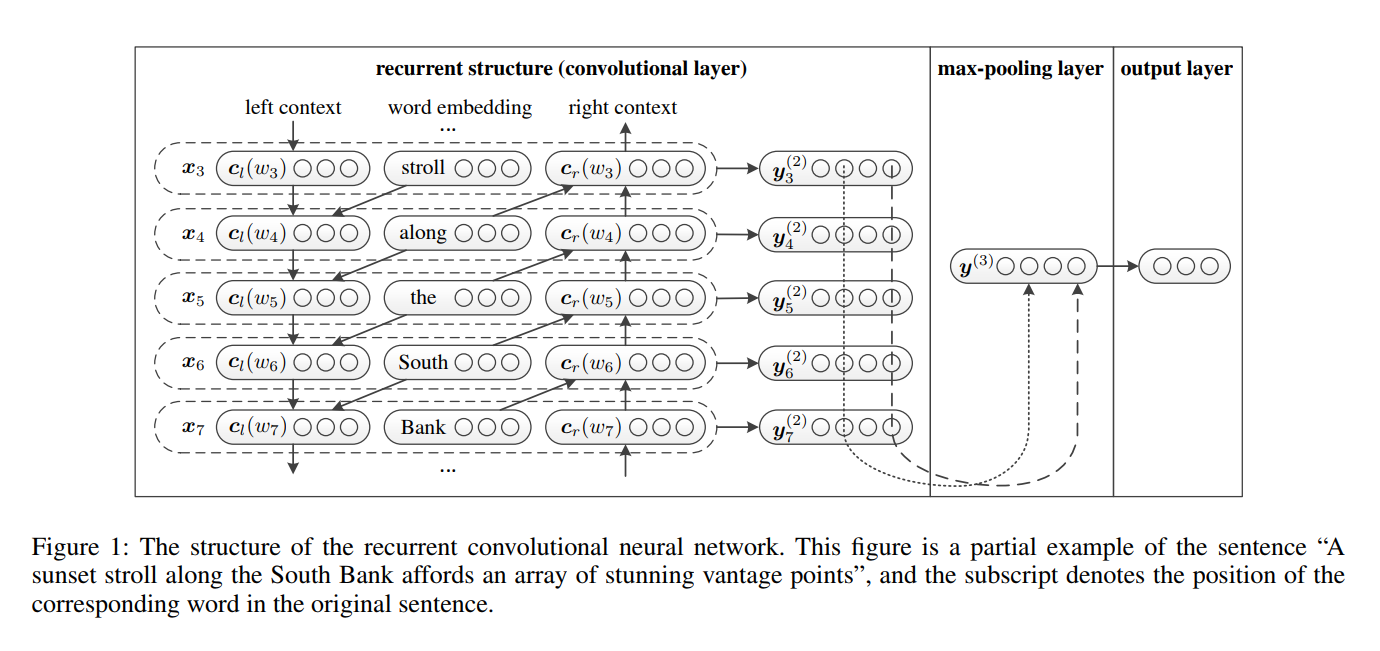
tanh活性化のfucntionとともに線形変換を表現に適用します。RCNNのネットワーク構造:
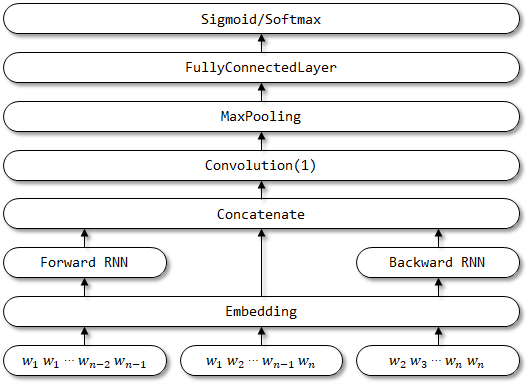
RCNNVARIANTは、RCNNに基づいた改善されたモデルであり、次の改善があります。関連する論文はまだ見つかりませんでした。
rcnnvariantのネットワーク構造: