TextClassification Keras
1.0.0
이 코드 저장소는 FastText , TextCnn , Textrnn , TextBirnn , TextAttBirnn , Han , RCNN , RCNNVariant 등을 포함하여 Keras 프레임 워크를 사용하여 텍스트 분류를 위한 다양한 딥 러닝 모델을 구현합니다. 모델 구현 외에도 단순화 된 응용 프로그램이 포함됩니다.
모든 코드는 디렉토리 /model 에 있으며 각 종류의 모델에는 모델 및 응용 프로그램이 배치되는 해당 디렉토리가 있습니다.
예를 들어, FastText의 모델과 응용 프로그램은 /model/FastText 아래에 있으며 모델 부분은 fast_text.py 이며 응용 프로그램 부분은 main.py 입니다.
FastText는 효율적인 텍스트 분류를위한 트릭 백에서 제안되었습니다.
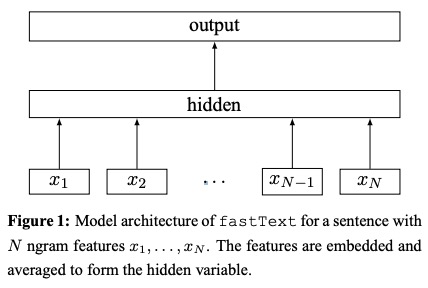
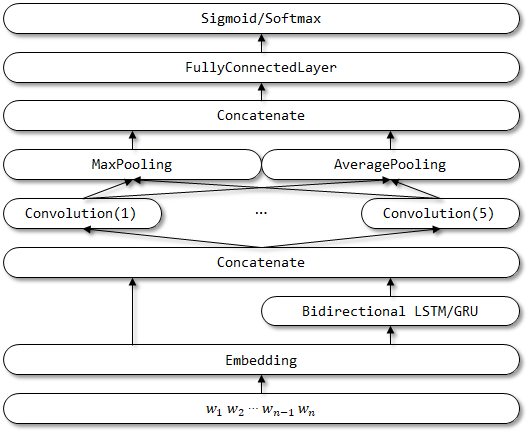
FastText의 네트워크 구조 :
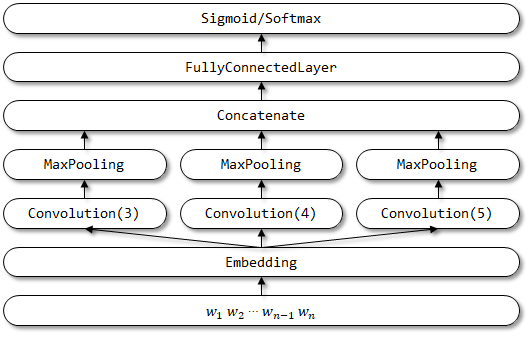
TextCnn은 문장 분류를 위해 논문 Convolutional Neural Networks에서 제안되었습니다.
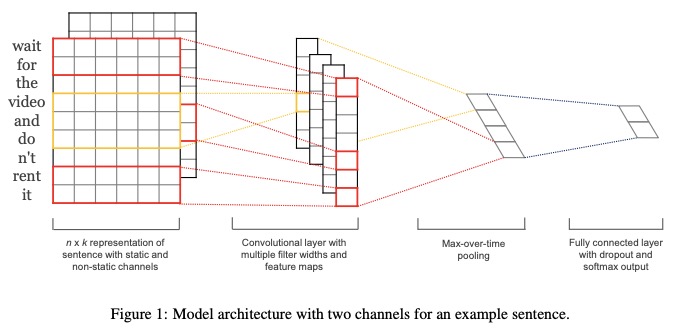
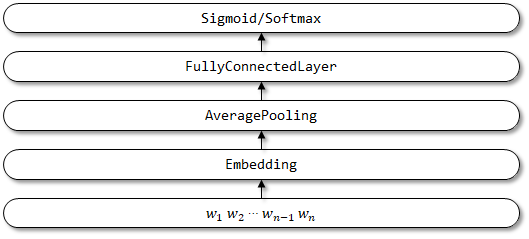
TextCnn의 네트워크 구조 :
Textrnn은 멀티 태스킹 학습으로 텍스트 분류를 위해 종이 재발 성 신경망에서 언급되었습니다.
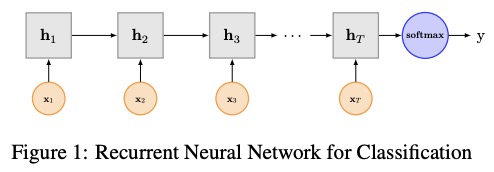
Textrnn의 네트워크 구조 :
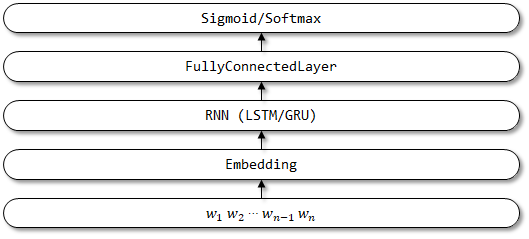
TextBirnn은 Textrnn을 기반으로 개선 된 모델입니다. 네트워크 구조의 RNN 층을 양방향 RNN 층으로 향상시킵니다. 전방 인코딩 정보뿐만 아니라 역 인코딩 정보를 고려할 수 있기를 바랍니다. 아직 관련 서류가 발견되지 않았습니다.
TextBirnn의 네트워크 구조 :
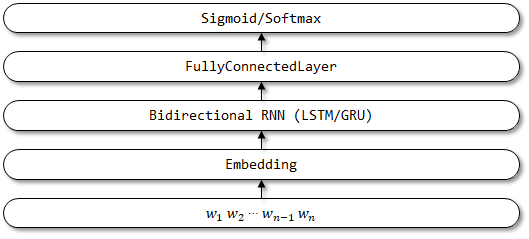
TextAttBirnn은 TextBirnn을 기반으로주의 메커니즘을 도입하는 개선 된 모델입니다. 양방향 RNN 인코더에 의해 얻은 표현 벡터의 경우,이 모델은주의 메커니즘을 통해 의사 결정과 가장 관련이있는 정보에 초점을 맞출 수 있습니다. 주의 메커니즘은 공동으로 정렬하고 번역하는 법을 학습함으로써 논문 신경 기계 번역에서 처음 제안되었으며, 여기서주의 메커니즘의 구현은이 논문 피드 포워드 네트워크를 주목할 수 있습니다.
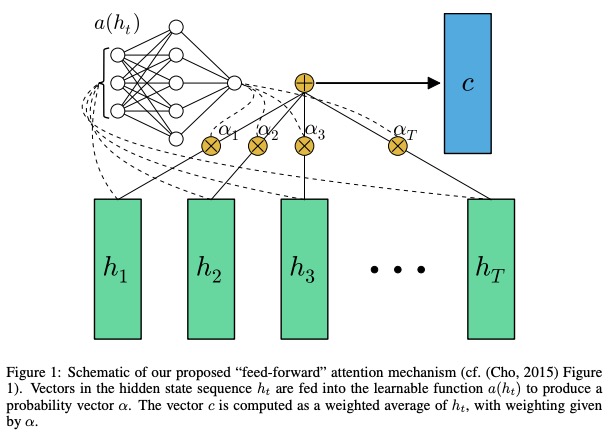
주의를 기울인 논문 피드 포워드 네트워크에서는 일부 장기 메모리 문제를 해결할 수 있으며, 피드 포워드주의는 다음과 같이 단순화됩니다.
학습 가능한 함수 인 함수 a 는 피드 포워드 네트워크 로 인식됩니다. 이 제형에서, 상태 서열 h 의 적응 가중 평균을 계산함으로써 입력 시퀀스의 고정 길이 포함 c 생성하는 것으로주의를 기울일 수있다.
주의 구현은 여기에 설명되지 않습니다. 소스 코드를 직접 참조하십시오.
TextAttBirnn의 네트워크 구조 :

Han은 문서 분류를위한 논문 계층 적주의 네트워크에서 제안되었습니다.
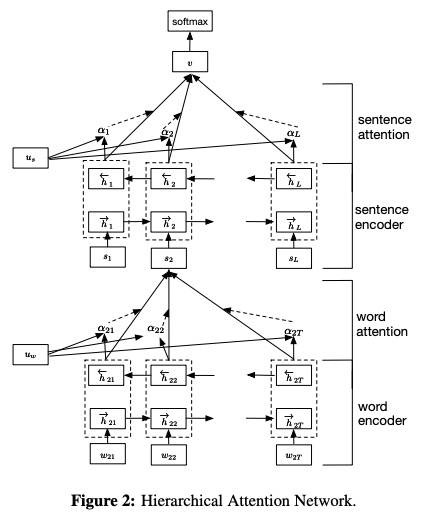
여기에서주의를 기울이는 것은 FeedforwardAttention을 기반으로하며, 이는 TextAttBirnn의 관심과 동일합니다.
한의 네트워크 구조 :
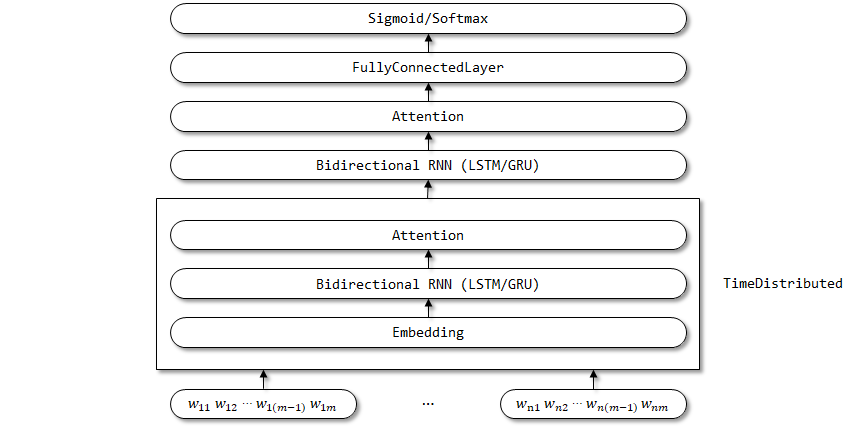
임베딩, 양방향 RNN 및주의 레이어의 매개 변수는 시간 단계 차원에서 공유 될 것으로 예상되기 때문에 시간 분포 래퍼는 여기서 사용됩니다.
RCNN은 텍스트 분류를 위해 종이 재발 성 컨볼 루션 신경 네트워크에서 제안되었습니다.
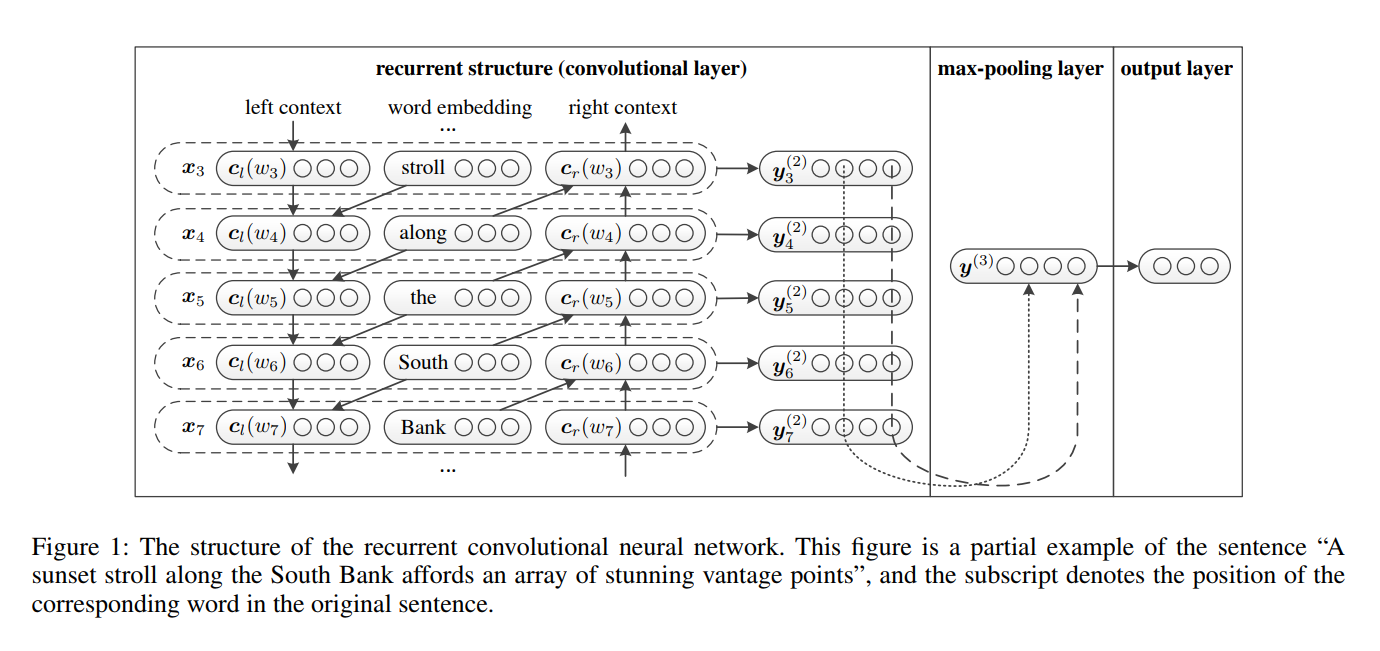
tanh 활성화 핵과 함께 선형 변환을 적용하십시오.RCNN의 네트워크 구조 :
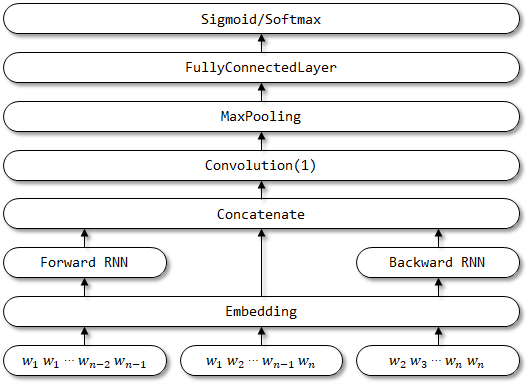
rcnnvariant는 다음과 같은 개선 된 RCNN을 기반으로 한 개선 된 모델입니다. 아직 관련 서류가 발견되지 않았습니다.
rcnnvariant의 네트워크 구조 :