TextClassification-Kinos
Este repositorio de código implementa una variedad de modelos de aprendizaje profundo para la clasificación de texto utilizando el marco Keras , que incluye: FastText , TextCnn , Textrnn , TextBirnn , Textattbirnn , Han , RCNN , RCNNVariant , etc. Además de la implementación del modelo, se incluye una aplicación simplificada.
Guía
- Ambiente
- Uso
- Modelo
- Contenedor
- Textcnn
- Textrnn
- Textbirnn
- Textattbirnn
- Maldito
- Rcnn
- Rcnnvariant
- Continuará...
- Referencia
Ambiente
- Python 3.7
- Numpy 1.17.2
- TensorFlow 2.0.1
Uso
Todos los códigos se encuentran en el directorio /model , y cada tipo de modelo tiene un directorio correspondiente en el que se colocan el modelo y la aplicación.
Por ejemplo, el modelo y la aplicación de FastText se encuentran en /model/FastText , la parte del modelo es fast_text.py y la parte de la aplicación es main.py
Modelo
1 FastText
FastText se propuso en la bolsa de papel de trucos para una clasificación de texto eficiente.
1.1 Descripción en papel
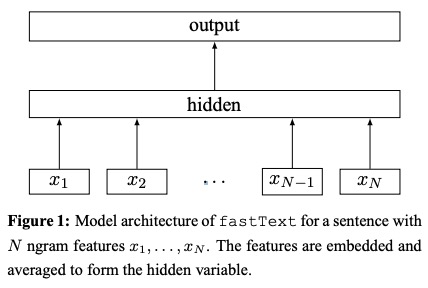
- Usando una tabla de búsqueda, bolsas de ngram encubiertas a representaciones de palabras .
- Las representaciones de palabras se promedian en una representación de texto, que es una variable oculta.
- La representación del texto se alimenta a un clasificador lineal .
- Use la función Softmax para calcular la distribución de probabilidad en las clases predefinidas.
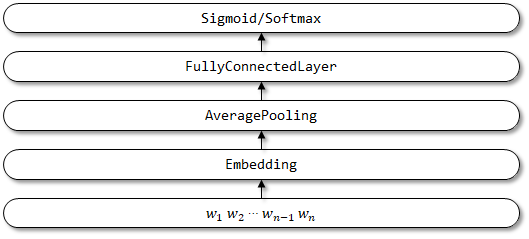
1.2 Implementación aquí
Estructura de red de FastText:
2 textcnn
TextCNN se propuso en las redes neuronales convolucionales de documentos para la clasificación de oraciones.
2.1 Descripción en papel
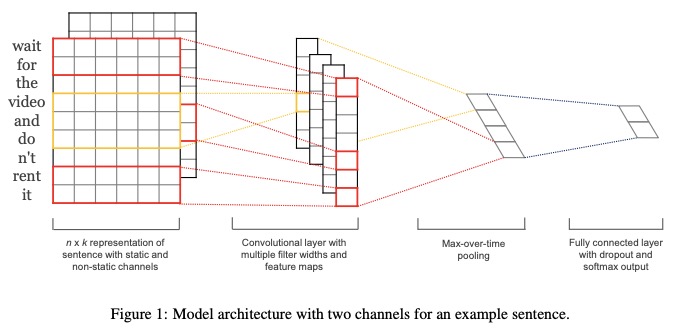
- Representar la oración con canales estáticos y no estáticos .
- Convolucionar con múltiples anchos de filtro y mapas de características.
- Use la agrupación de tiempo máximo de tiempo .
- Use una capa totalmente conectada con abandono y OUPTMAX Softmax .
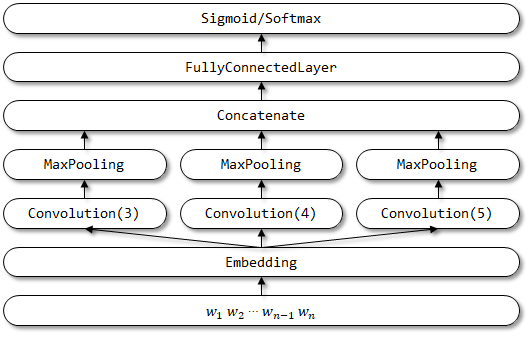
2.2 Implementación aquí
Estructura de red de TextCnn:
3 Textrnn
Textrnn ha sido mencionado en la red neuronal recurrente en papel para la clasificación de texto con aprendizaje de tareas múltiples.
3.1 Descripción en papel
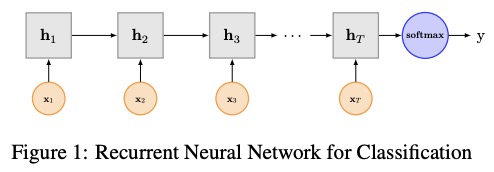
3.2 Implementación aquí
Estructura de red de Textrnn:
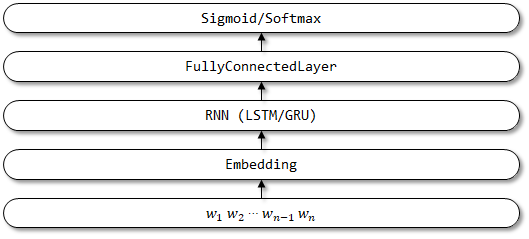
4 textbirnn
TextBirnn es un modelo mejorado basado en Textrnn. Mejora la capa RNN en la estructura de la red en una capa RNN bidireccional. Se espera que no solo se pueda considerar la información de codificación hacia adelante, sino también la información de codificación inversa. Todavía no se han encontrado documentos relacionados.
Estructura de red de TextBirnn:
5 Textattbirnn
Textattbirnn es un modelo mejorado que introduce un mecanismo de atención basado en TextBirnn. Para los vectores de representación obtenidos por el codificador RNN bidireccional, el modelo puede centrarse en la información más relevante para la toma de decisiones a través del mecanismo de atención. El mecanismo de atención se propuso por primera vez en la traducción del papel neuronal del documento al aprender conjuntamente a alinearse y traducir, y la implementación del mecanismo de atención aquí se refiere a este documento que las redes de alimentación con atención pueden resolver algunos problemas de memoria a largo plazo.
5.1 Descripción en papel
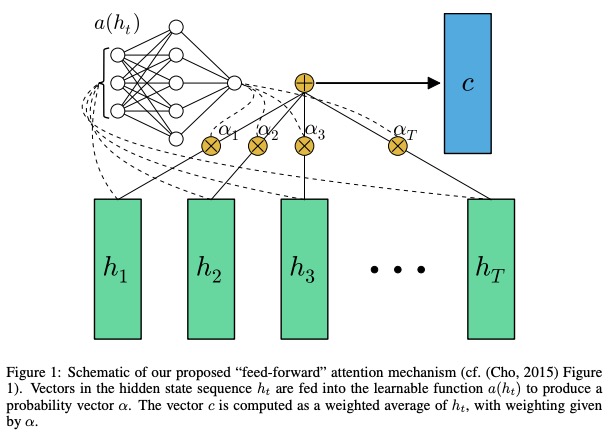
En el documento, las redes de avance con atención pueden resolver algunos problemas de memoria a largo plazo, la atención de alimentación hacia adelante se simplifica de la siguiente manera,
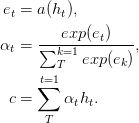
La función a , una función aprendible, se reconoce como una red de alimentación . En esta formulación, se puede ver que la atención produce una incrustación c de longitud fija de la secuencia de entrada calculando un promedio ponderado adaptativo de la secuencia de estado h .
5.2 Implementación aquí
La implementación de la atención no se describe aquí, consulte el código fuente directamente.
Estructura de red de textattbirnn:

6 Han
Han fue propuesto en las redes de atención jerárquica de documentos para la clasificación de documentos.
6.1 Descripción en papel
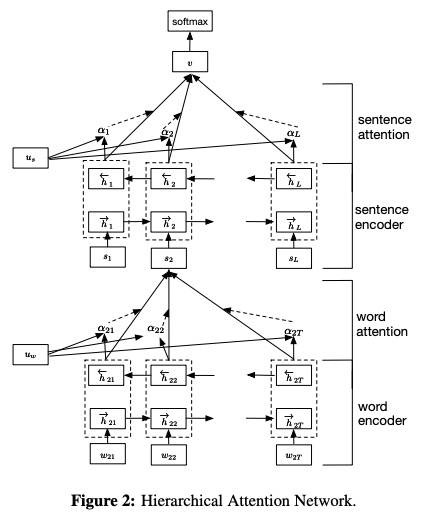
- Word Coder . Codificación de Gru bidireccional , se obtiene una anotación para una palabra dada concatenando el estado oculto hacia adelante y el estado oculto hacia atrás, que resume la información de toda la oración centrada en la palabra en el paso de tiempo actual.
- Palabra atención . Por una función MLP y Softmax de una capa, puede calcular los pesos de importancia normalizados sobre las anotaciones de palabras anteriores. Luego, calcule el vector de oraciones como una suma ponderada de las anotaciones de la palabra basadas en los pesos.
- Codador de oraciones . De manera similar con Word Coder, use un Gru bidireccional para codificar las oraciones para obtener una anotación para una oración.
- Atención de la oración . Similar con la atención de las palabras, use una función MLP y Softmax de una capa para obtener los pesos sobre las anotaciones de las oraciones. Luego, calcule una suma ponderada de las anotaciones de oraciones basadas en los pesos para obtener el vector del documento.
- Clasificación de documentos . Use la función Softmax para calcular la probabilidad de todas las clases.
6.2 Implementación aquí
La implementación de la atención aquí se basa en la atención forzada, que es la misma que la atención en Textattbirnn.
Estructura de red de Han:
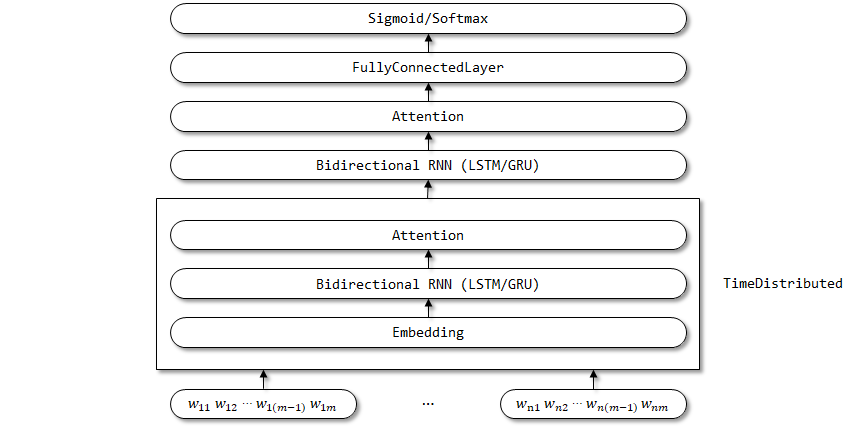
El envoltorio distribuido Timedributs se usa aquí, ya que se espera que los parámetros de la incrustación, la RNN bidireccional y las capas de atención se compartan en la dimensión del paso de tiempo.
7 rcnn
RCNN se propuso en las redes neuronales convolucionales recurrentes en papel para la clasificación de texto.
7.1 Descripción en papel
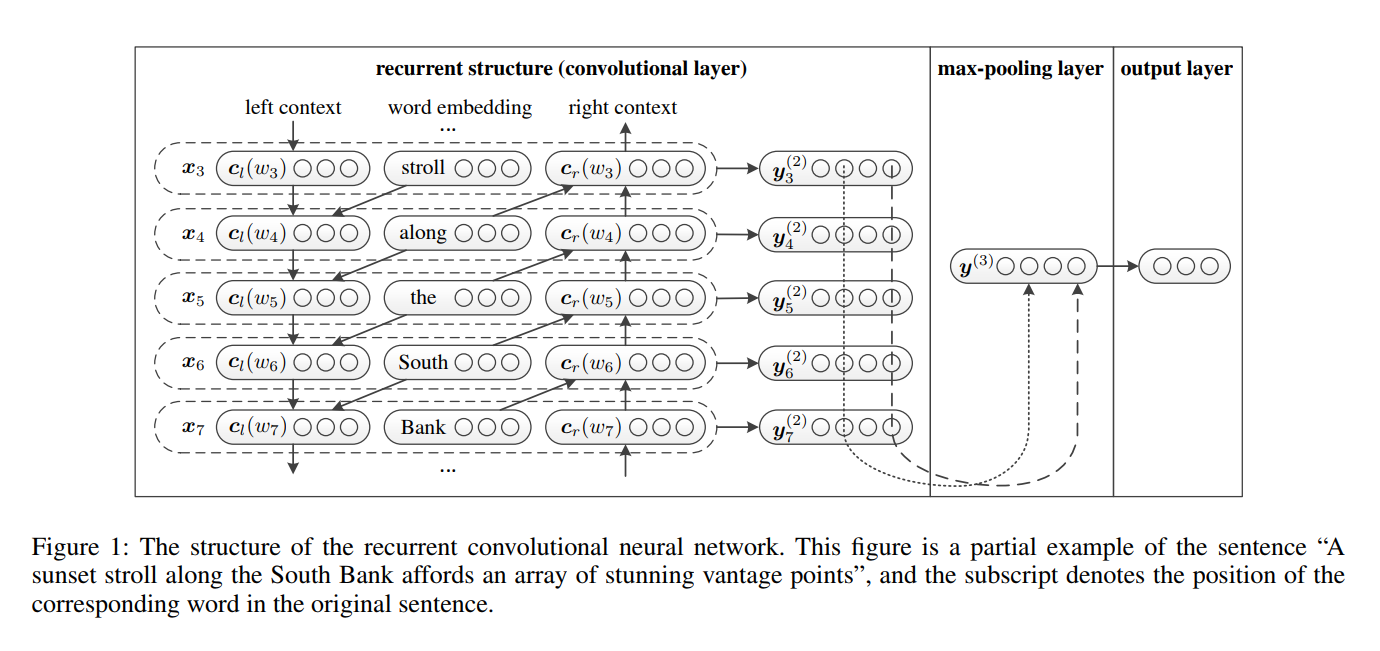
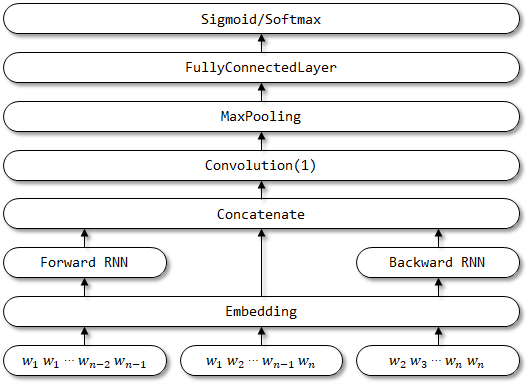
- Aprendizaje de representación de palabras . RCNN utiliza una estructura recurrente, que es una red neuronal recurrente bidireccional , para capturar los contextos. Luego, combine la palabra y su contexto para presentar la palabra. Y aplique una transformación lineal junto con la fucntación de activación
tanh a la representación. - Aprendizaje de representación de texto . Cuando se calculan todas las representaciones de las palabras, aplica una capa de poliamiento máximo en términos de elementos para capturar la información más importante en todo el texto. Finalmente, haga la transformación lineal y aplique la función Softmax .
7.2 Implementación aquí
Estructura de red de RCNN:
8 rcnnvariant
RCNNVariant es un modelo mejorado basado en RCNN con las siguientes mejoras. Todavía no se han encontrado documentos relacionados.
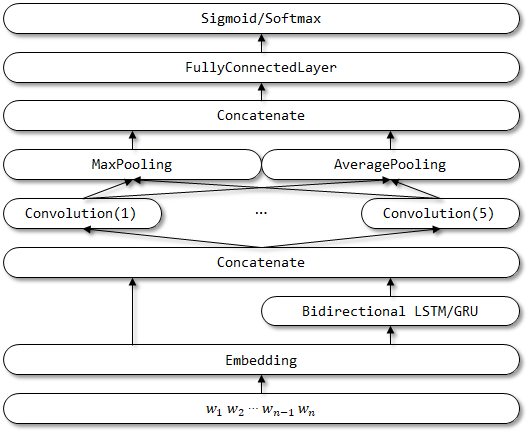
- Las tres entradas se cambian a entrada única . Se elimina la entrada de los contextos izquierdo y derecho.
- Use LSTM/Gru bidireccional en lugar de RNN tradicional para el contexto de codificación.
- Use CNN multicanal para representar los vectores semánticos.
- Reemplace la capa de activación de Tanh con la capa de activación Relu .
- Utilice tanto promedio y maxpooling .
Estructura de red de RCNNVariant:
Continuará...
Referencia
- Bolsa de trucos para una clasificación de texto eficiente
- Keras Ejemplo IMDB FastText
- Redes neuronales convolucionales para la clasificación de oraciones
- Ejemplo de Keras IMDB CNN
- Red neuronal recurrente para la clasificación de texto con aprendizaje de varias tareas
- Traducción del automóvil neural aprendiendo conjuntamente a alinearse y traducir
- Las redes de alimentación con atención pueden resolver algunos problemas de memoria a largo plazo
- Atención de Cbaziotis
- Redes de atención jerárquica para la clasificación de documentos
- Han de Richard
- Redes neuronales convolucionales recurrentes para la clasificación de texto
- RCNN de AiralCorn2


