TEXTCLASSIFICATIVA-MARAS
Este repositório de código implementa uma variedade de modelos de aprendizado profundo para classificação de texto usando a estrutura Keras , que inclui: FastText , textcnn , textrnn , textbirnn , textattbirnn , han , rcnn , rcnnvariant , etc. Além da implementação do modelo, uma aplicação simplificada é incluída.
Orientação
- Ambiente
- Uso
- Modelo
- FastText
- Textcnn
- Textrnn
- Textbirnn
- Textattbirnn
- Han
- Rcnn
- Rcnnvariant
- Continua...
- Referência
Ambiente
- Python 3.7
- Numpy 1.17.2
- Tensorflow 2.0.1
Uso
Todos os códigos estão localizados no diretório /model , e cada tipo de modelo possui um diretório correspondente no qual o modelo e o aplicativo são colocados.
Por exemplo, o modelo e a aplicação do FastText estão localizados em /model/FastText , a parte do modelo é fast_text.py e a parte do aplicativo é main.py
Modelo
1 texto rápido
O FastText foi proposto no saco de papel de truques para classificação eficiente de texto.
1.1 Descrição no papel
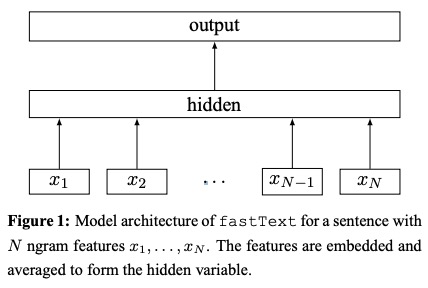
- Usando uma tabela de pesquisa, as sacolas de Ngram encoberta para representações de palavras .
- As representações de palavras são calculadas em uma representação de texto, que é uma variável oculta.
- Por sua vez, a representação de texto é alimentada a um classificador linear .
- Use a função Softmax para calcular a distribuição de probabilidade nas classes predefinidas.
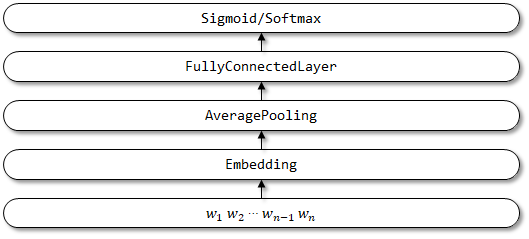
1.2 Implementação aqui
Estrutura de rede do FastText:
2 textcnn
O TextCNN foi proposto nas redes neurais convolucionais do artigo para classificação de sentenças.
2.1 Descrição no papel
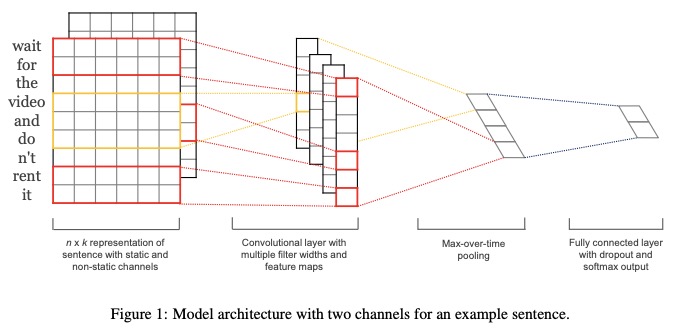
- Represente a frase com canais estáticos e não estáticos .
- Convidar com várias larguras de filtro e mapas de recursos.
- Use o pool de máximo de tempo .
- Use camada totalmente conectada com o abandono e o Softmax OUPUT.
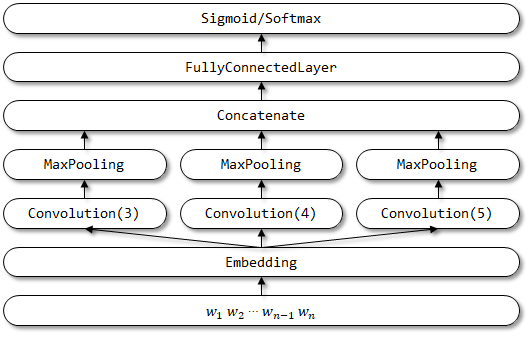
2.2 Implementação aqui
Estrutura de rede de textcnn:
3 Textrnn
O Textrnn foi mencionado na rede neural recorrente em papel para classificação de texto com aprendizado de várias tarefas.
3.1 Descrição no papel
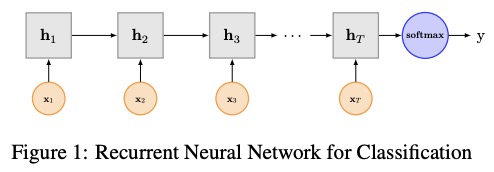
3.2 Implementação aqui
Estrutura de rede de Textrnn:
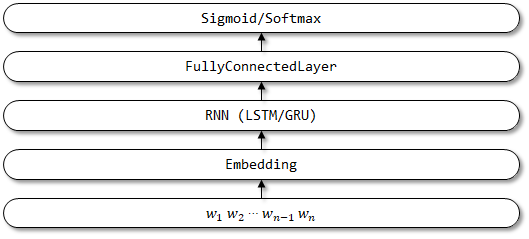
4 textbirnn
O TextBirnn é um modelo aprimorado baseado no textrnn. Melhora a camada RNN na estrutura da rede em uma camada RNN bidirecional. Espera -se que não apenas as informações de codificação direta, mas também as informações de codificação reversa possam ser consideradas. Ainda não foram encontrados documentos relacionados.
Estrutura de rede do textbirnn:
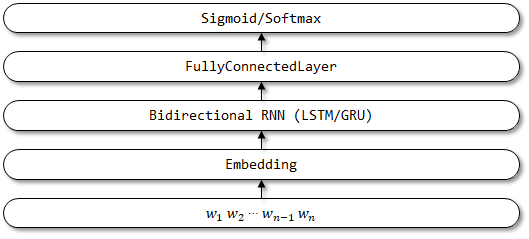
5 textattbirnn
O TextattBirnn é um modelo aprimorado que introduz o mecanismo de atenção baseado no textbirnn. Para os vetores de representação obtidos pelo codificador RNN bidirecional, o modelo pode se concentrar nas informações mais relevantes para a tomada de decisão através do mecanismo de atenção. O mecanismo de atenção foi proposto pela primeira vez na tradução da máquina neural de papel, aprendendo em conjunto a alinhar e traduzir, e a implementação do mecanismo de atenção aqui é referida a esta redes de feed-forward com atenção com atenção pode resolver alguns problemas de memória de longo prazo.
5.1 Descrição em papel
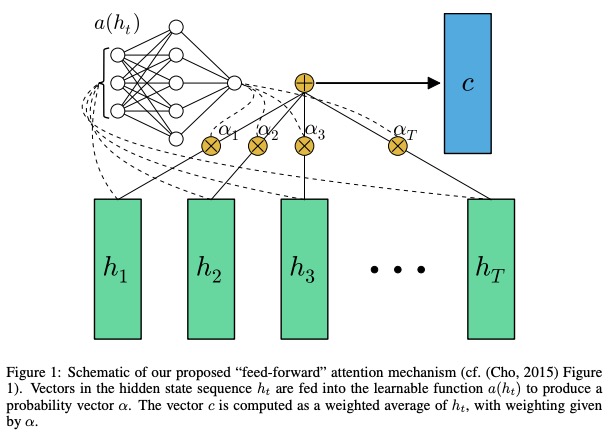
Nas redes de feed-forward de papel com atenção podem resolver alguns problemas de memória de longo prazo, o alheio Atenção Atenção é simplificada da seguinte maneira,
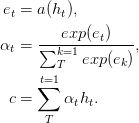
A função a , uma função aprendida, é reconhecida como uma rede de feed para frente . Nesta formulação, a atenção pode ser vista como produzindo um c de incorporação de comprimento fixo da sequência de entrada, calculando uma média ponderada adaptativa da sequência de estado h
5.2 Implementação aqui
A implementação da atenção não é descrita aqui, consulte diretamente o código -fonte.
Estrutura de rede de textattbirnn:

6 Han
Han foi proposto nas redes de atenção hierárquica em papel para classificação de documentos.
6.1 Descrição no papel
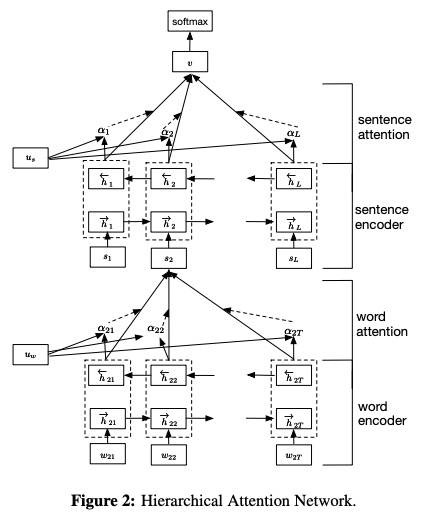
- Codificador de palavras . A codificação por Gru bidirecional , uma anotação para uma determinada palavra é obtida concatenando o estado oculto e o estado oculto para trás, que resume as informações de toda a frase centrada na palavra na etapa atual.
- Atenção da palavra . Por uma função MLP e Softmax de uma camada, ele pode calcular pesos de importância normalizada sobre as anotações anteriores do Word. Em seguida, calcule o vetor da frase como uma soma ponderada da palavra anotações com base nos pesos.
- Codificador de frases . De maneira semelhante ao codificador do Word, use um GRU bidirecional para codificar as frases para obter uma anotação para uma frase.
- Atenção da frase . Semelhante com a atenção das palavras, use uma função MLP e Softmax de uma camada para obter as anotações de pesos sobre as sentenças. Em seguida, calcule uma soma ponderada das anotações da frase com base nos pesos para obter o vetor de documento.
- Classificação de documentos . Use a função Softmax para calcular a probabilidade de todas as classes.
6.2 Implementação aqui
A implementação da atenção aqui é baseada na FeedforwardAttion, que é a mesma que a atenção no textattbirnn.
Estrutura de rede de Han:
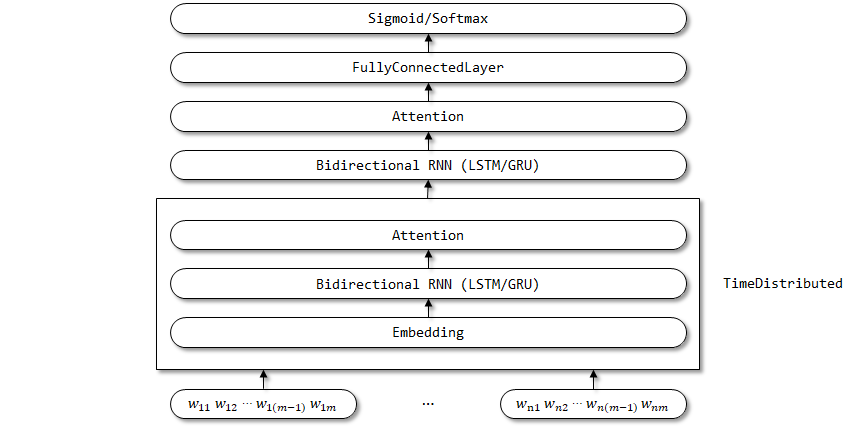
O invólucro timedistribuído é usado aqui, uma vez que os parâmetros da incorporação, RNN bidirecional e camadas de atenção devem ser compartilhados na dimensão da etapa de tempo.
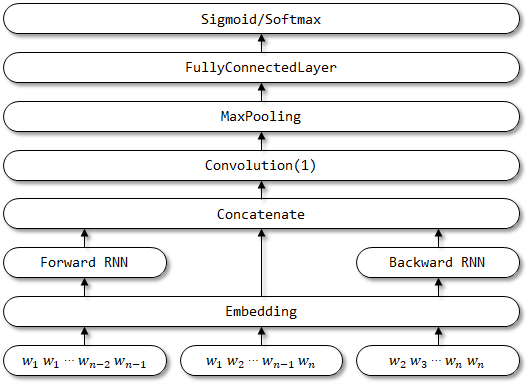
7 rcnn
O RCNN foi proposto nas redes neurais convolucionais recorrentes para classificação de texto.
7.1 Descrição em papel
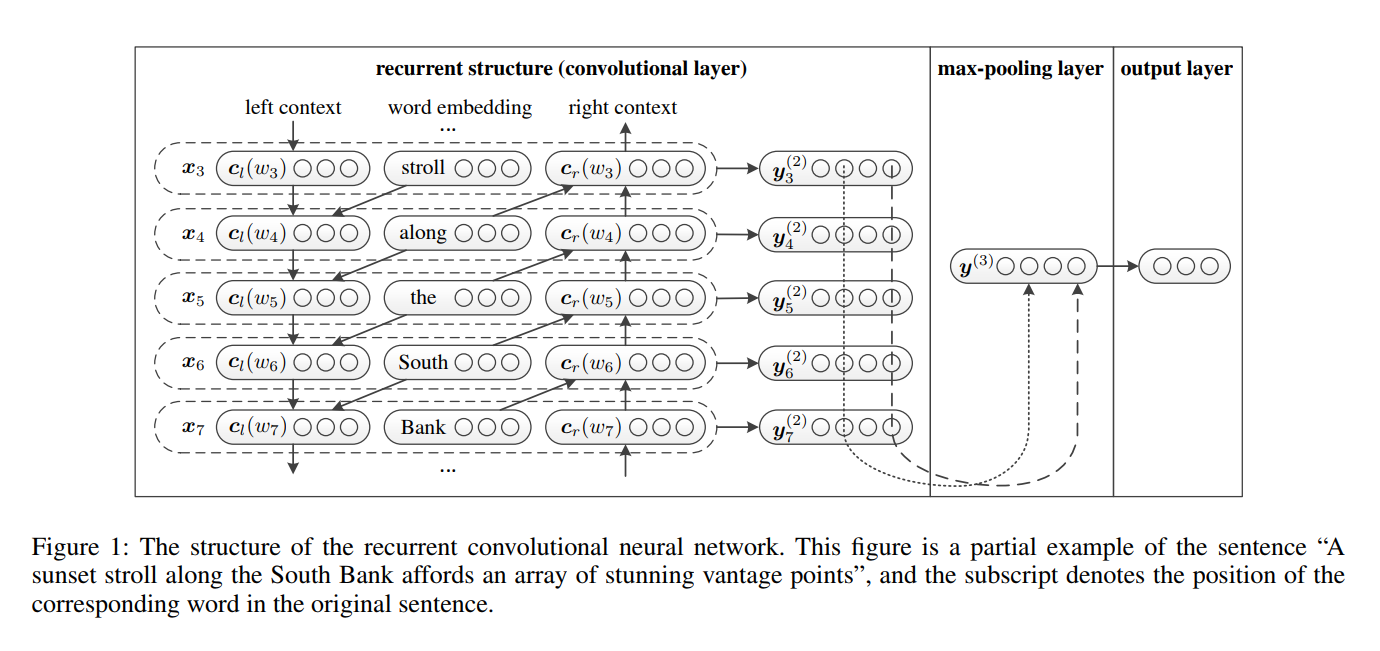
- Aprendizagem de representação de palavras . O RCNN usa uma estrutura recorrente, que é uma rede neural recorrente bidirecional , para capturar os contextos. Em seguida, combine a palavra e seu contexto para apresentar a palavra. E aplique uma transformação linear juntamente com a Fucção de Ativação
tanh na representação. - Aprendizagem de representação de texto . Quando todas as representações das palavras são calculadas, ela aplica uma camada de poolamento máximo no elemento para capturar as informações mais importantes em todo o texto. Por fim, faça a transformação linear e aplique a função Softmax .
7.2 Implementação aqui
Estrutura de rede do RCNN:
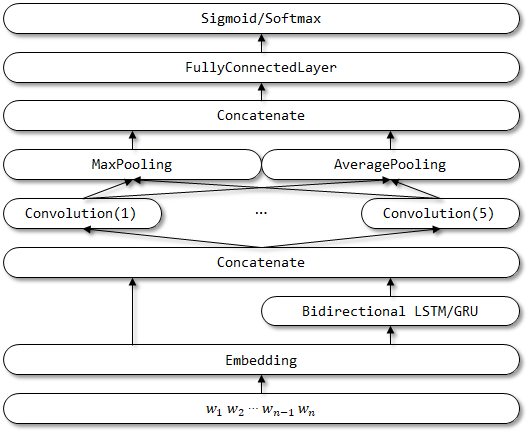
8 rcnnvariant
O RCNNVariant é um modelo aprimorado baseado no RCNN com as seguintes melhorias. Ainda não foram encontrados documentos relacionados.
- As três entradas são alteradas para entrada única . A entrada dos contextos esquerda e direita é removida.
- Use LSTM/GRU bidirecional em vez do RNN tradicional para codificar o contexto.
- Use CNN multicanal para representar os vetores semânticos.
- Substitua a camada de ativação de Tanh pela camada de ativação RelU .
- Use a média do formulário e o maxpooling .
Estrutura de rede de rcnnvariant:
Continua...
Referência
- Saco de truques para classificação de texto eficiente
- Exemplo de Keras IMDB FastText
- Redes neurais convolucionais para classificação de frases
- Exemplo de keras imdb cnn
- Rede neural recorrente para classificação de texto com aprendizado de várias tarefas
- Tradução da máquina neural aprendendo em conjunto a alinhar e traduzir
- Redes de alimentação com atenção podem resolver alguns problemas de memória de longo prazo
- A atenção de Cbaziotis
- Redes de atenção hierárquica para classificação de documentos
- Richard's Han
- Redes neurais convolucionais recorrentes para classificação de texto
- RCNN da AiralCorn2


