Текстовая степень-керас
Этот репозиторий кода реализует множество моделей глубокого обучения для классификации текста , используя структуру керас , которая включает в себя: FastText , TextCnn , Textrnn , TextBirnn , TextAttbirnn , Han , Rcnn , Rcnnvariant и т. Д. В дополнение к реализации модели включено упрощенное приложение.
Руководство
- Среда
- Использование
- Модель
- Фасттекст
- TextCnn
- Textrnn
- TextBirnn
- Textattbirnn
- Хан
- Rcnn
- Rcnnvariant
- Продолжение следует...
- Ссылка
Среда
- Python 3.7
- Numpy 1.17.2
- Tensorflow 2.0.1
Использование
Все коды расположены в каталоге /model , и каждый вид модели имеет соответствующий каталог, в котором размещаются модель и приложение.
Например, модель и приложение FastText расположены в /model/FastText , часть модели - fast_text.py , а часть приложения - main.py
Модель
1 быстрый текст
Фасттекст был предложен в бумажном пакете трюков для эффективной классификации текста.
1.1 Описание в бумаге
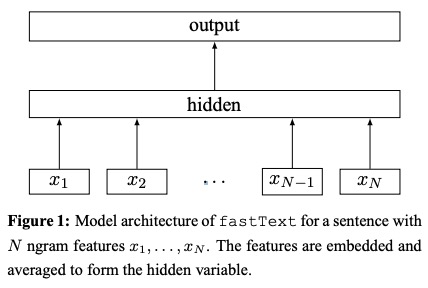
- Используя справочный стол, мешки NGRAM, скрытые для представлений Word .
- Представления слов усредняются в текстовое представление, которое является скрытой переменной.
- Текстовое представление, в свою очередь, питается линейным классификатором .
- Используйте функцию SoftMax , чтобы вычислить распределение вероятностей по предопределенным классам.
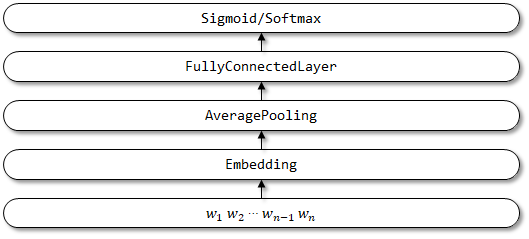
1.2 Реализация здесь
Структура сети быстрого текста:
2 TextCnn
TextCnn был предложен в бумажных сверточных нейронных сетях для классификации предложений.
2.1 Описание в бумаге
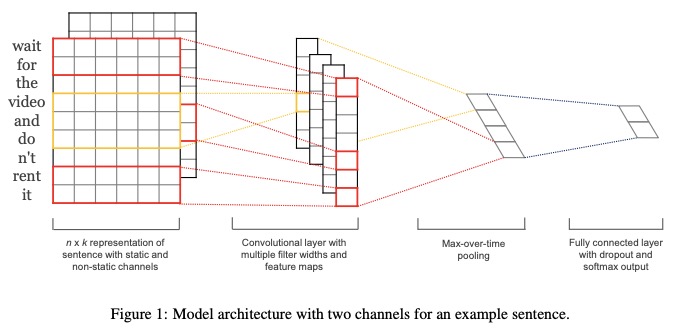
- Представляют предложение со статическими и нестатическими каналами .
- Сверните с несколькими шириной фильтра и картами функций.
- Используйте максимальное время объединения .
- Используйте полностью подключенный слой с выпущенным и Softmax Outlo.
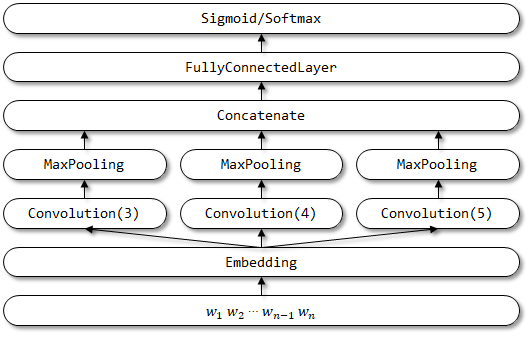
2.2 Реализация здесь
СЕТИВНАЯ СТРУКТУРА TEXTCNN:
3 Textrnn
Textrnn был упомянут в бумажной рецидивирующей нейронной сети для классификации текста с помощью многозадачного обучения.
3.1 Описание в бумаге
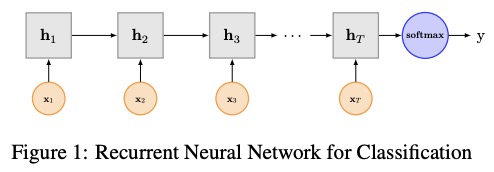
3.2 Реализация здесь
Страница сети Textrnn:
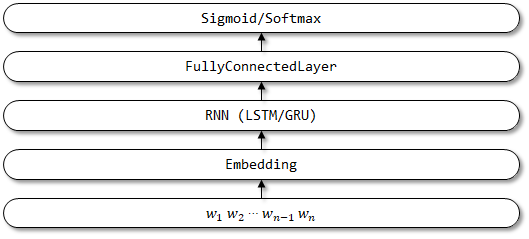
4 TextBirnn
TextBirnn - это улучшенная модель, основанная на Textrnn. Это улучшает уровень RNN в структуре сети в двунаправленный уровень RNN. Есть надежда, что может быть рассмотрена не только информация о кодировании прямого кодирования, но и информация об обратном кодировании. Связанных документов еще не найдено.
Страница сети TextBirnn:
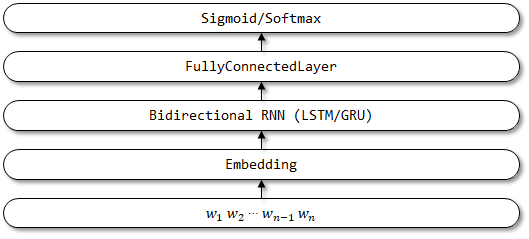
5 Textattbirnn
Textattbirnn - это улучшенная модель, которая вводит механизм внимания, основанный на TextBirnn. Для векторов представления, полученных с помощью двунаправленного энкодера RNN, модель может сосредоточиться на информации, наиболее важной для принятия решений с помощью механизма внимания. Механизм внимания был впервые предложен в переводе с нейронной машиной бумаги путем совместного обучения для выравнивания и перевода, и реализация механизма внимания здесь передается в эту статью о сетях подачи с вниманием с вниманием может решить некоторые долговременные проблемы с памятью.
5.1 Описание в бумаге
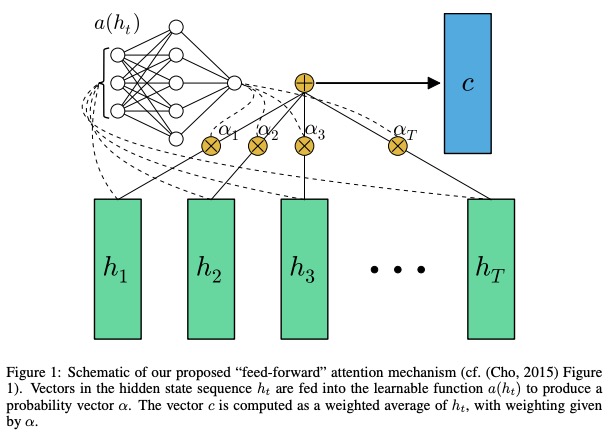
В бумажных сетях подачи с вниманием могут решить некоторые долговременные проблемы с памятью, обратное внимание упрощается следующим образом,
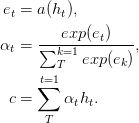
Функция a , обучаемая функция, распознается как сеть подачи вперед . В этой формулировке внимание можно рассматривать как создание встраивания c в входной последовательности с фиксированной длиной путем вычисления адаптивного среднего значения последовательности состояния h .
5.2 Реализация здесь
Реализация внимания здесь не описана, пожалуйста, обратитесь к исходному коду напрямую.
Страница сети Textattbirnn:

6 Хан
Хан был предложен в бумажных иерархических сетях внимания для классификации документов.
6.1 Описание в бумаге
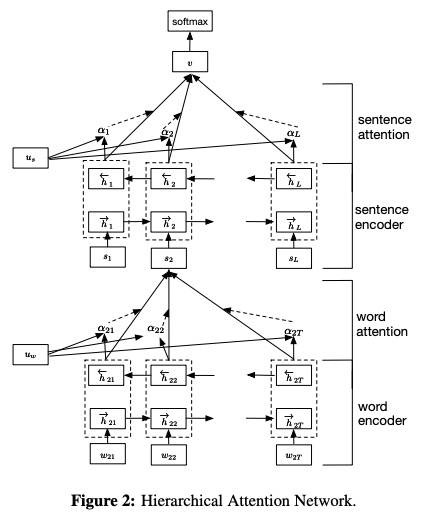
- Слово энкодер . Кодирование двунаправленным GRU , аннотация для данного слова, полученная путем объединения прямого состояния и отсталого скрытого состояния, которое суммирует информацию всего предложения, сосредоточенного вокруг слова на текущем шаге времени.
- Слово Внимание . С помощью однослойной функции MLP и Softmax он позволяет рассчитать нормализованную важность по предыдущим словам слова. Затем вычислите вектор предложения как взвешенную сумму словесных аннотаций на основе весов.
- Предложение кодер . Аналогичным образом с Word Encoder, используйте двунаправленный GRU , чтобы кодировать предложения, чтобы получить аннотацию для предложения.
- Предложение внимание . Подобно словному вниманию, используйте однослойную MLP и функцию Softmax, чтобы получить веса по аннотациям предложений. Затем вычислите взвешенную сумму аннотаций предложения на основе весов, чтобы получить вектор документа.
- Классификация документов . Используйте функцию Softmax , чтобы вычислить вероятность всех классов.
6.2 Реализация здесь
Реализация внимания здесь основана на питании, что такое же, как внимание в Textattbirnn.
Структура сети Хана:
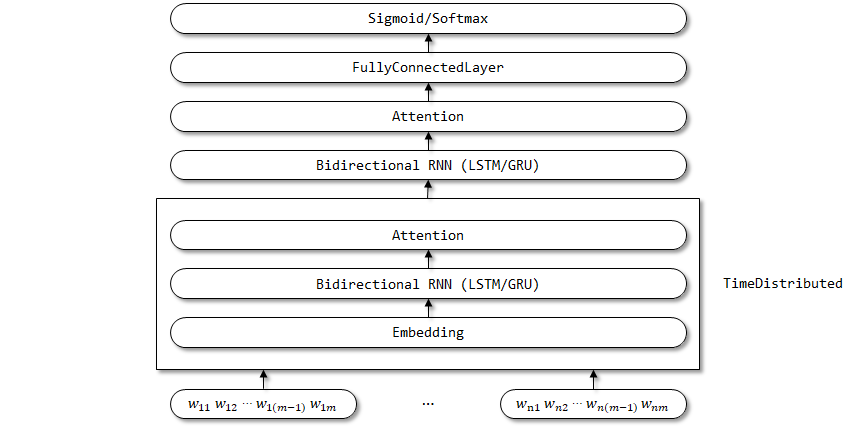
Обадрика с временной цифрой используется здесь, поскольку ожидается, что параметры встраивания, двунаправленное RNN и уровни внимания будут разделены в измерении временного шага.
7 rcnn
RCNN был предложен в бумажном рецидивирующем сверточном нейронном сети для классификации текста.
7.1 Описание в бумаге
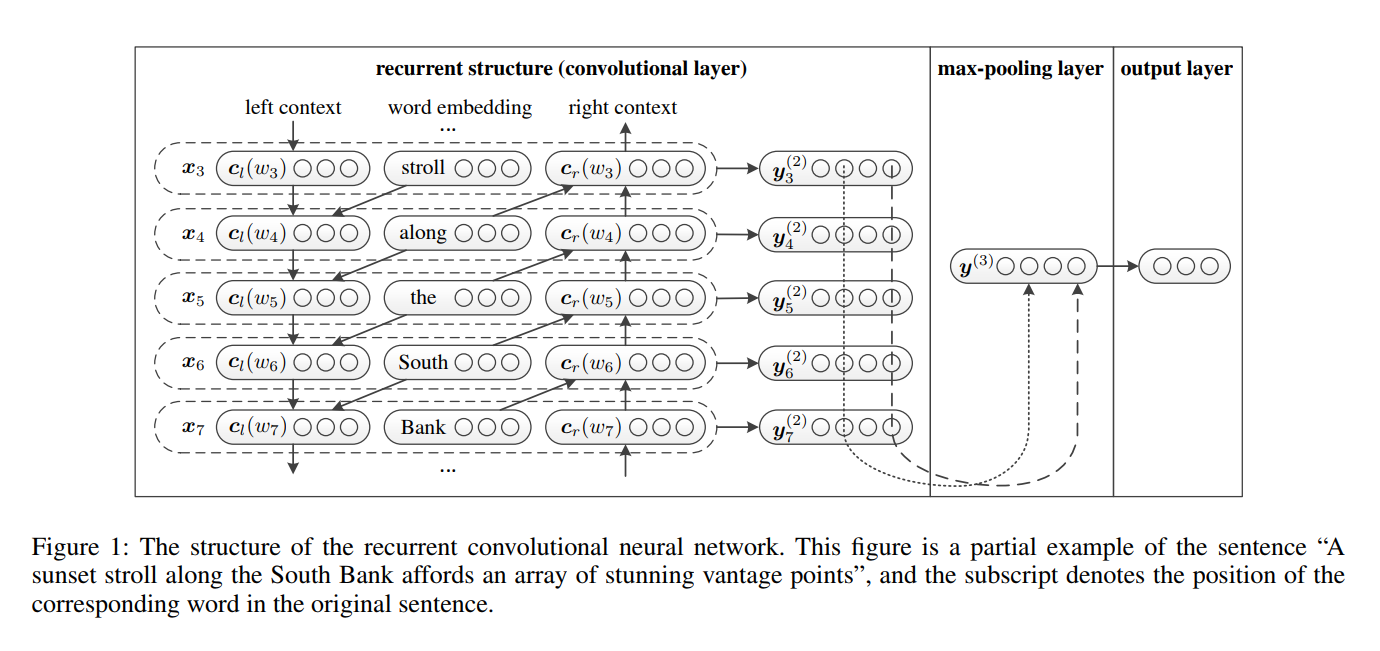
- Слово -представление обучение . RCNN использует повторяющуюся структуру, которая представляет собой двунаправленную рецидивирующую нейронную сеть , чтобы захватить контексты. Затем объедините слово и его контекст, чтобы представить слово. И примените линейное преобразование вместе с активацией
tanh к представлению. - Текстовое представление обучение . Когда все представления слов рассчитываются, он применяет элемент максимального уровня максимума, чтобы захватить наиболее важную информацию на протяжении всего текста. Наконец, сделайте линейное преобразование и примените функцию Softmax .
7.2 Реализация здесь
Структура сети RCNN:
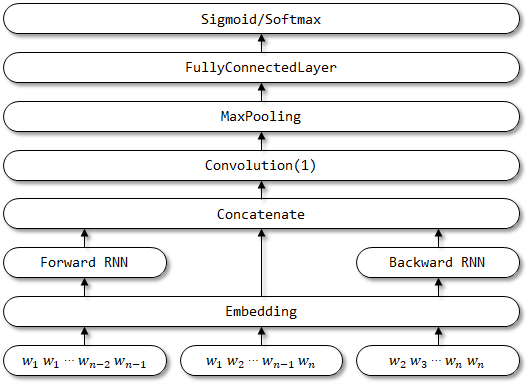
8 rcnnvariant
Rcnnvariant - это улучшенная модель, основанная на RCNN со следующими улучшениями. Связанных документов еще не найдено.
- Три входа изменяются на отдельный вход . Ввод левого и правого контекста удаляется.
- Используйте двунаправленную LSTM/GRU вместо традиционного RNN для контекста кодирования.
- Используйте многоканальный CNN , чтобы представить семантические векторы.
- Замените слой активации TANH на слой активации RELU .
- Используйте как среднее место, так и максимум .
Структура сети Rcnnvariant:
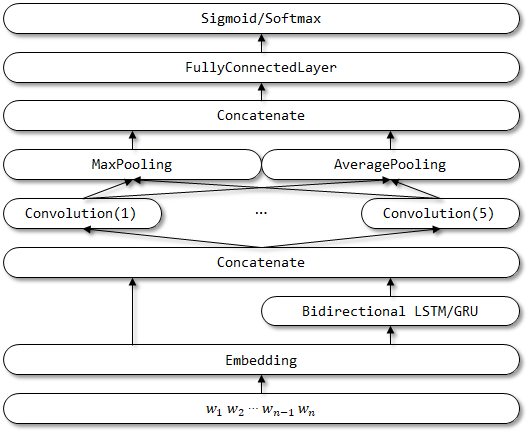
Продолжение следует...
Ссылка
- Мешок трюков для эффективной классификации текста
- Пример кераса IMDB FASTTEXT
- Сверточные нейронные сети для классификации приговора
- Керас пример IMDB CNN
- Повторяющаяся нейронная сеть для классификации текста с помощью многозадачного обучения
- Перевод нейронной машины путем совместного обучения выравнивать и переводить
- Сетки подачи с вниманием могут решить некоторые долговременные проблемы с памятью
- внимание Cbaziotis
- Иерархические сети внимания для классификации документов
- Ричард Хан
- Повторяющиеся сверточные нейронные сети для классификации текста
- Airalcorn2 Rcnn


