TextClassification-keras
ينفذ مستودع التعليمات البرمجية مجموعة متنوعة من نماذج التعلم العميق لتصنيف النص باستخدام إطار Keras ، والذي يتضمن: fasttext ، textcnn ، textrnn ، textbirnn ، textattbirnn ، han ، rcnn ، rcnnvariant ، إلخ. بالإضافة إلى تنفيذ النموذج ، يتم تضمين تطبيق مبسط.
إرشاد
- بيئة
- الاستخدام
- نموذج
- fasttext
- TextCnn
- Textrnn
- TextBirnn
- textattbirnn
- هان
- rcnn
- rcnnvariant
- يتبع...
- مرجع
بيئة
- بيثون 3.7
- Numpy 1.17.2
- Tensorflow 2.0.1
الاستخدام
توجد جميع الرموز في الدليل /model ، وكل نوع من النماذج لديه دليل مقابل يتم فيه وضع النموذج والتطبيق.
على سبيل المثال ، يوجد نموذج وتطبيق FastText تحت /model/FastText ، جزء النموذج هو fast_text.py ، وجزء التطبيق هو main.py
نموذج
1 fasttext
تم اقتراح FastText في كيس الورق من الحيل لتصنيف النص الفعال.
1.1 الوصف في الورق
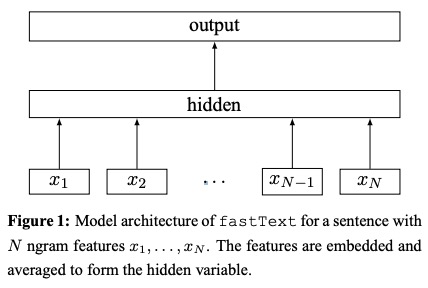
- باستخدام جدول البحث ، أكياس من NGRAM سرية لتمثيلات الكلمات .
- يتم حساب متوسط تمثيلات الكلمات في تمثيل نص ، وهو متغير مخفي.
- تم إطعام تمثيل النص بدوره إلى مصنف خطي .
- استخدم وظيفة SoftMax لحساب توزيع الاحتمالات على الفئات المحددة مسبقًا.
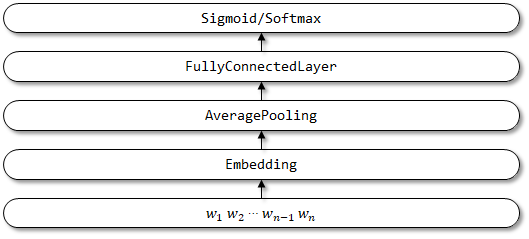
1.2 التنفيذ هنا
هيكل شبكة fasttext:
2 TextCnn
تم اقتراح TextCnn في الشبكات العصبية التلافيفية الورقية لتصنيف الجملة.
2.1 الوصف في الورق
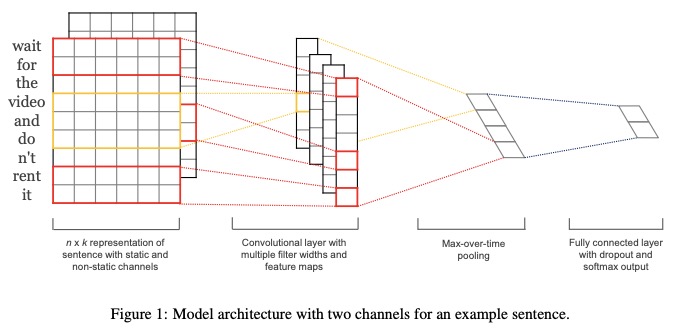
- تمثل الجملة مع القنوات الثابتة وغير المنتظمة .
- قم بالتوقيخ بعرض المرشح المتعدد وخرائط الميزات.
- استخدم Max-Over-Time Pooling .
- استخدم طبقة متصلة بالكامل مع التسرب و softmax ouput.
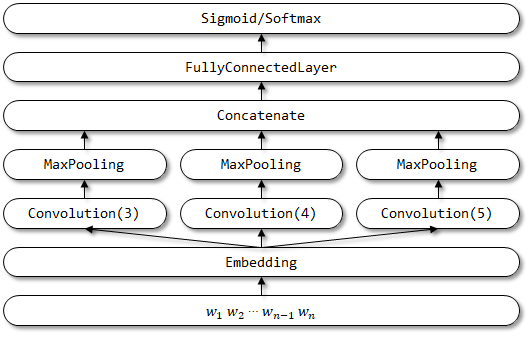
2.2 التنفيذ هنا
هيكل شبكة TextCnn:
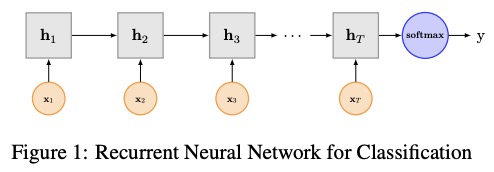
3 Textrnn
تم ذكر Textrnn في الشبكة العصبية المتكررة الورقية لتصنيف النص مع التعلم متعدد المهام.
3.1 الوصف في الورق
3.2 التنفيذ هنا
هيكل شبكة Textrnn:
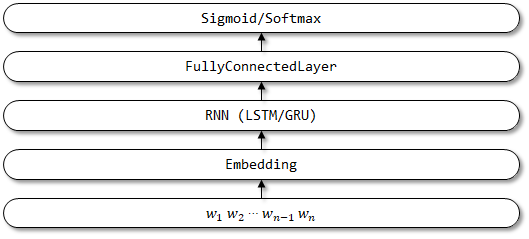
4 TextBirnn
TextBirnn هو نموذج محسن يعتمد على Textrnn. يحسن طبقة RNN في بنية الشبكة إلى طبقة RNN ثنائية الاتجاه. من المأمول أنه لا يمكن النظر في معلومات الترميز إلى الأمام فحسب ، بل يمكن أيضًا النظر في معلومات الترميز العكسي. لم يتم العثور على أوراق ذات صلة حتى الآن.
بنية شبكة TextBirnn:
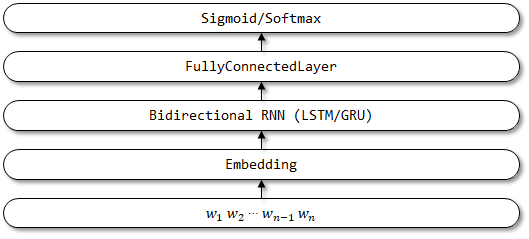
5 Textattatbirnn
TextAttBirnn هو نموذج محسّن يقدم آلية الانتباه على أساس TextBirnn. بالنسبة لمتجهات التمثيل التي تم الحصول عليها بواسطة تشفير RNN ثنائية الاتجاه ، يمكن للنموذج التركيز على المعلومات الأكثر صلة بعملية اتخاذ القرارات من خلال آلية الانتباه. تم اقتراح آلية الانتباه لأول مرة في ترجمة الآلة العصبية الورقية من خلال تعلم مشترك للمحاذاة والترجمة ، ويتم إحالة تنفيذ آلية الانتباه هنا إلى شبكات التغذية الورقية مع الانتباه يمكن أن يحل بعض مشاكل الذاكرة طويلة الأجل.
5.1 الوصف في الورق
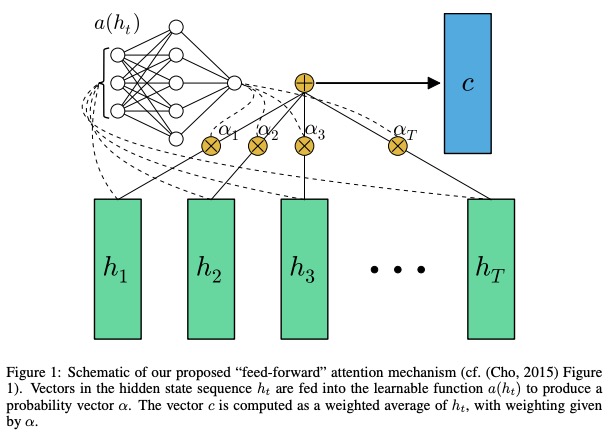
في شبكات التغذية المقدمة من الخلاصات مع الانتباه يمكن أن تحل بعض مشاكل الذاكرة طويلة المدى ، يتم تبسيط الانتباه إلى الأمام على النحو التالي ،
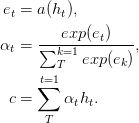
يتم التعرف على الوظيفة a ، وهي وظيفة قابلة للتعلم ، كشبكة التغذية الأمامية . في هذه الصيغة ، يمكن اعتبار الانتباه على أنه ينتج c ثابتًا في تسلسل الإدخال عن طريق حساب متوسط مرجح للتكيف لتسلسل الحالة h .
5.2 التنفيذ هنا
لم يتم وصف تنفيذ الاهتمام هنا ، يرجى الرجوع إلى رمز المصدر مباشرة.
هيكل شبكة Textattatbirnn:

6 هان
تم اقتراح HAN في شبكات الاهتمام الهرمية الورقية لتصنيف المستندات.
6.1 الوصف في الورق
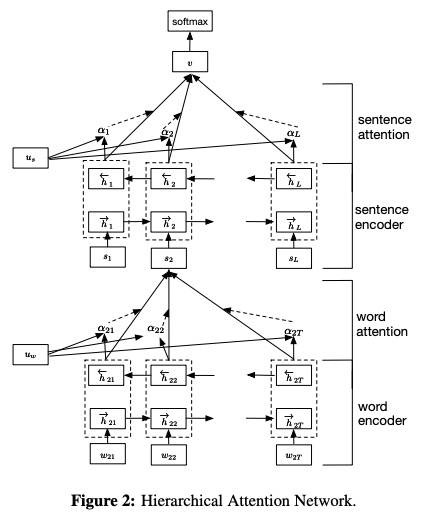
- تشفير الكلمات . الترميز بواسطة ثنائي الاتجاه GRU ، يتم الحصول على شرح كلمة معينة عن طريق تسلسل الحالة المخفية إلى الأمام والدولة المخفية للخلف ، والتي تلخص معلومات الجملة بأكملها التي تركز على الكلمة في الخطوة الزمنية الحالية.
- اهتمام كلمة . بواسطة دالة MLP ذات الطبقة الواحدة و SoftMax ، يتم تمكينها من حساب أوزان الأهمية الطبيعية على تعليقات الكلمات السابقة. بعد ذلك ، قم بحساب متجه الجملة كمجموع مرجح من كلمة التعليقات التوضيحية على أساس الأوزان.
- تشفير الجملة . بطريقة مماثلة مع Word Encoder ، استخدم GRU ثنائية الاتجاه لترميز الجمل للحصول على تعليق توضيحي للحصول على جملة.
- انتباه الجملة . على غرار اهتمام الكلمات ، استخدم وظيفة MLP ذات الطبقة الواحدة و SoftMax للحصول على أوزان على تعليقات الجملة. بعد ذلك ، قم بحساب مجموع مرجح من توضيحات الجملة بناءً على الأوزان للحصول على متجه المستند.
- تصنيف المستند . استخدم وظيفة softmax لحساب احتمال جميع الفئات.
6.2 التنفيذ هنا
يعتمد تنفيذ الاهتمام هنا على Feedforwardatteate ، وهو نفس الاهتمام في Textattatbirnn.
هيكل شبكة هان:
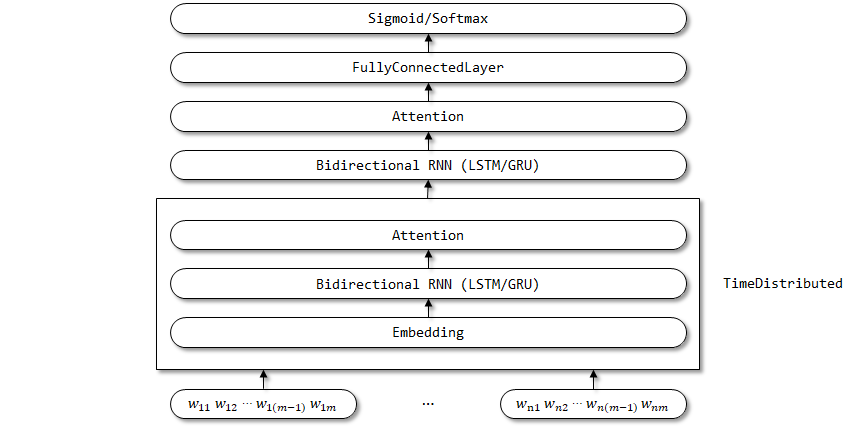
يتم استخدام غلاف التوقيت هنا ، حيث من المتوقع أن تتم مشاركة معلمات التضمين ، RNN ثنائية الاتجاه ، ومن المتوقع مشاركة طبقات الانتباه في البعد الزمني.
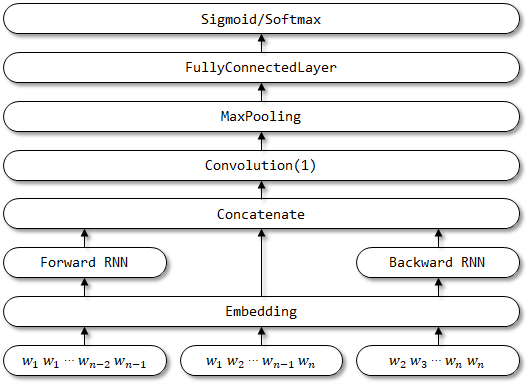
7 rcnn
تم اقتراح RCNN في الشبكات العصبية التلافيفية المتكررة الورقية لتصنيف النص.
7.1 الوصف في الورق
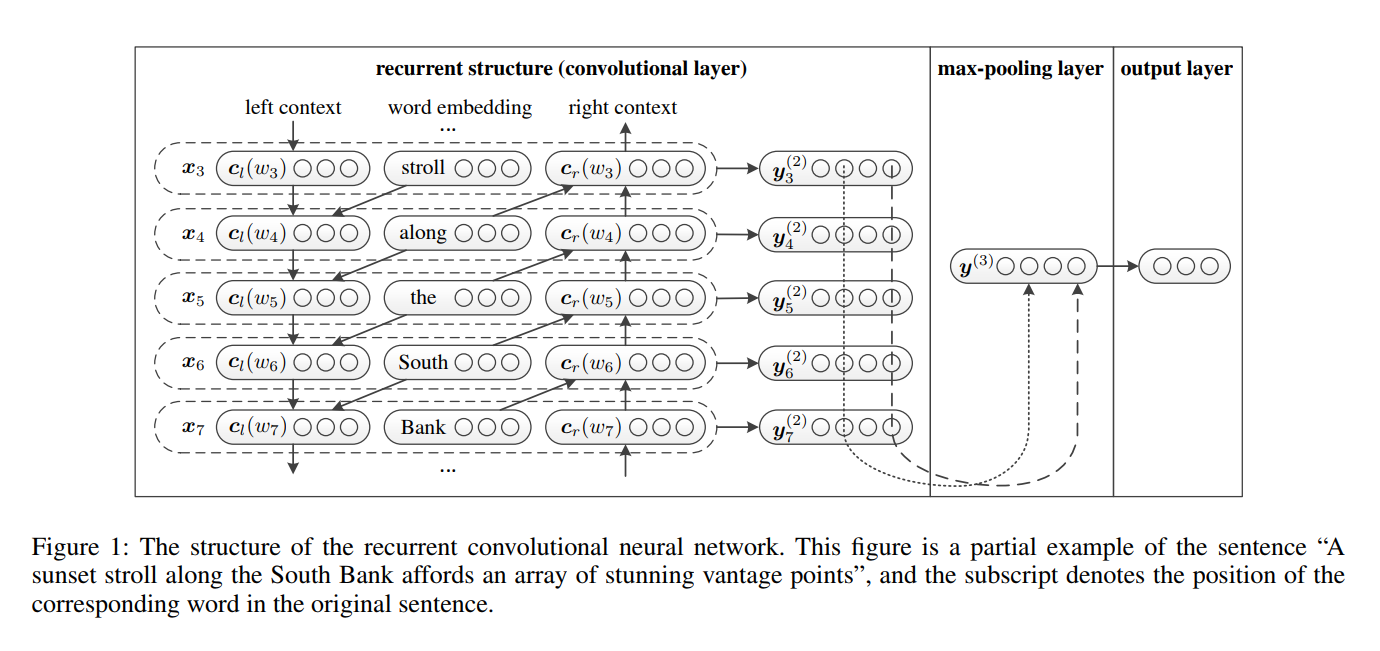
- تمثيل الكلمات التعلم . يستخدم RCNN بنية متكررة ، وهي شبكة عصبية متكررة ثنائية الاتجاه ، لالتقاط السياقات. ثم ، اجمع الكلمة وسياقها لتقديم الكلمة. وتطبيق تحول خطي مع تفعيل تنشيط
tanh على التمثيل. - التعلم تمثيل النص . عندما يتم حساب جميع تمثيلات الكلمات ، فإنه يطبق طبقة تجويف بحكم العناصر من أجل التقاط أهم المعلومات خلال النص بأكمله. أخيرًا ، قم بالتحول الخطي وتطبيق وظيفة softmax .
7.2 التنفيذ هنا
هيكل شبكة RCNN:
8 rcnnvariant
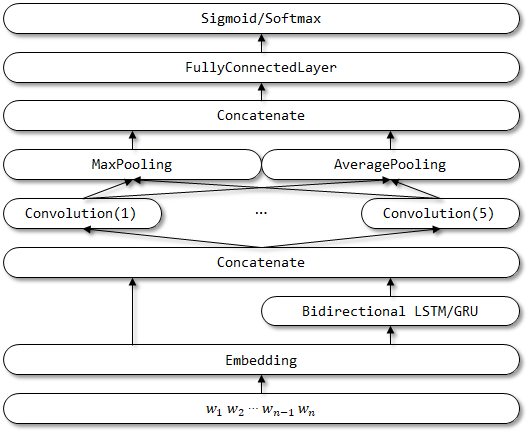
Rcnnvariant هو نموذج محسّن يعتمد على RCNN مع التحسينات التالية. لم يتم العثور على أوراق ذات صلة حتى الآن.
- يتم تغيير المدخلات الثلاثة إلى إدخال واحد . تتم إزالة إدخال السياقات اليسرى واليمنى.
- استخدم LSTM/GRU ثنائية الاتجاه بدلاً من RNN التقليدية لترميز السياق.
- استخدم CNN متعدد القنوات لتمثيل المتجهات الدلالية.
- استبدل طبقة تنشيط TANH بطبقة تنشيط RELU .
- استخدم كل من متوسط pooling و maxpooling .
هيكل شبكة RCNNVariant:
يتبع...
مرجع
- حقيبة الحيل لتصنيف النص الفعال
- keras مثال على imdb fasttext
- الشبكات العصبية التلافيفية لتصنيف الجملة
- Keras مثال IMDB CNN
- الشبكة العصبية المتكررة لتصنيف النص مع التعلم متعدد المهام
- الترجمة الآلية العصبية من خلال تعلم مشترك للمحاذاة والترجمة
- يمكن أن تحل شبكات التغذية إلى الأمام مع الانتباه بعض مشاكل الذاكرة طويلة المدى
- انتباه Cbaziotis
- شبكات الاهتمام الهرمي لتصنيف المستندات
- ريتشارد هان
- الشبكات العصبية التلافيفية المتكررة لتصنيف النص
- AiralCorn2's RCNN


