Textklassifizierung-Keras
Dieses Code -Repository implementiert eine Vielzahl von Deep -Learning -Modellen für die Textklassifizierung unter Verwendung des Keras -Frameworks, das: FastText , TextCnn , Textrnn , TextBirnn , Textattbirnn , Han , RCNN , RCNNvariant usw. enthält. Zusätzlich zur Modellumsetzung wird eine vereinfachte Anwendung einbezogen.
Anleitung
- Umfeld
- Verwendung
- Modell
- FastText
- Textcnn
- Textrnn
- Textbirnn
- Textattbirnn
- Han
- Rcnn
- Rcnnvariant
- Fortgesetzt werden...
- Referenz
Umfeld
- Python 3.7
- Numpy 1.17.2
- Tensorflow 2.0.1
Verwendung
Alle Codes befinden sich im Verzeichnis /model , und jede Art von Modell verfügt über ein entsprechendes Verzeichnis, in dem das Modell und die Anwendung platziert werden.
Beispielsweise befinden sich das Modell und die Anwendung von FastText unter /model/FastText , der Modellteil ist fast_text.py und der Anwendungsteil ist main.py
Modell
1 FastText
FastText wurde in der taptuellen Trick -Tüte für eine effiziente Textklassifizierung vorgeschlagen.
1.1 Beschreibung in Papier
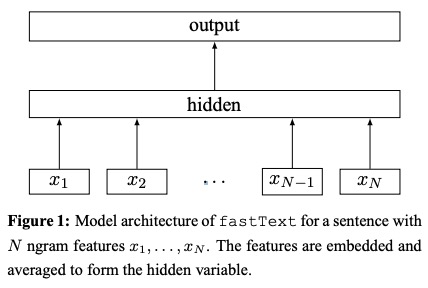
- Mit einer Nachschlagtabelle verdeckt NGRAM-Taschen mit Word-Darstellungen .
- Die Wortdarstellungen werden zu einer Textdarstellung gemittelt , bei der es sich um eine versteckte Variable handelt.
- Die Textdarstellung wird wiederum einem linearen Klassifikator umgefügt.
- Verwenden Sie die Softmax -Funktion, um die Wahrscheinlichkeitsverteilung über die vordefinierten Klassen zu berechnen.
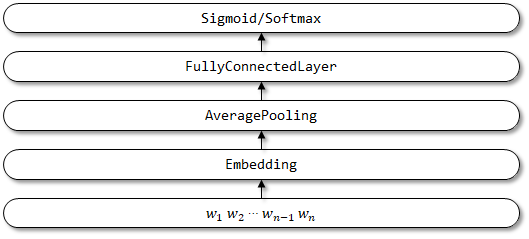
1.2 Implementierung hier
Netzwerkstruktur von FastText:
2 textcnn
Textcnn wurde in den duftenden neuronalen Netzwerken für die Satzklassifizierung vorgeschlagen.
2.1 Beschreibung in Papier
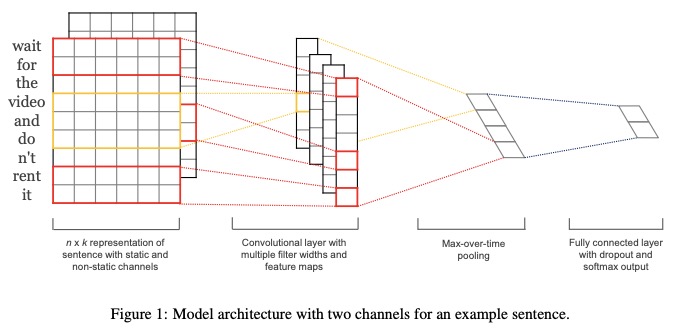
- Satz mit statischen und nicht statischen Kanälen darstellen.
- Konsumieren Sie mit mehreren Filterbreiten und Feature -Karten.
- Verwenden Sie Max-Over-Time-Pooling .
- Verwenden Sie eine vollständig verbundene Ebene mit Ausfall und Softmax Ousput.
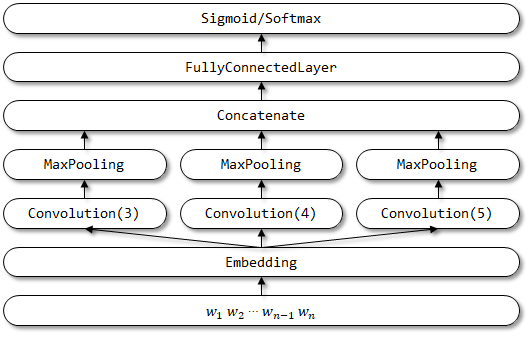
2.2 Implementierung hier
Netzwerkstruktur von TextCNN:
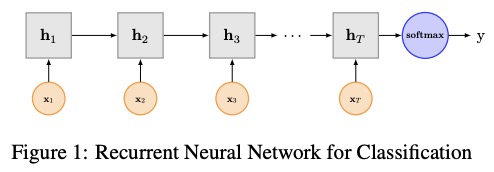
3 Textrnn
Textrnn wurde im Papier für das neuronale Netzwerk für die Textklassifizierung mit Multi-Task-Lernen erwähnt.
3.1 Beschreibung in Papier
3.2 Implementierung hier
Netzwerkstruktur von Textrnn:
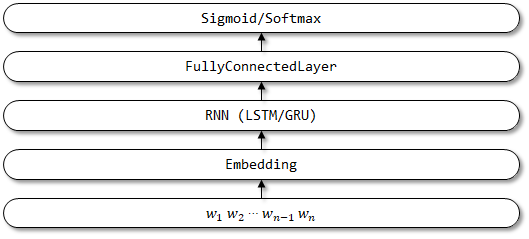
4 textbirnn
Textbirnn ist ein verbessertes Modell, das auf Textrnn basiert. Es verbessert die RNN -Schicht in der Netzwerkstruktur zu einer bidirektionalen RNN -Schicht. Es ist zu hoffen, dass nicht nur die Forward -Codierungsinformationen, sondern auch die umgekehrten Codierungsinformationen berücksichtigt werden können. Es wurden noch keine verwandten Papiere gefunden.
Netzwerkstruktur von Textbirnn:
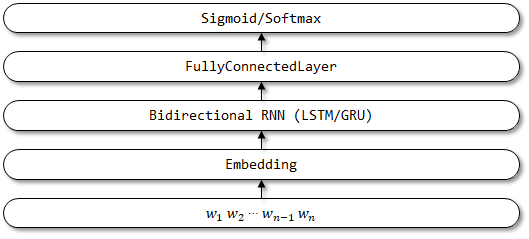
5 textattbirnn
Textattbirnn ist ein verbessertes Modell, das den Aufmerksamkeitsmechanismus basierend auf Textbirnn einführt. Für die von bidirektionalen RNN -Encoder erhaltenen Darstellungsvektoren kann sich das Modell auf die Informationen konzentrieren, die durch den Aufmerksamkeitsmechanismus für die Entscheidungsfindung am relevantesten sind. Der Aufmerksamkeitsmechanismus wurde zunächst in der Papierübersetzung vorgeschlagen, indem sie gemeinsam lernen und übersetzen, und die Implementierung des Aufmerksamkeitsmechanismus wird hier auf dieses Papier-Feed-Forward-Netzwerke mit Aufmerksamkeit verwiesen, kann einige Probleme mit dem Langzeitgedächtnis lösen.
5.1 Beschreibung in Papier
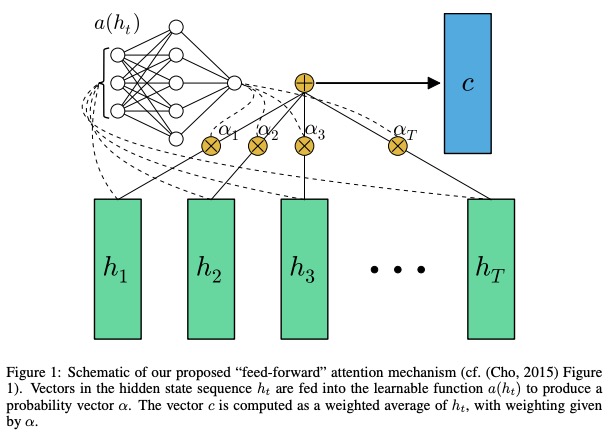
In den Papier-Feed-Forward-Netzwerken mit Aufmerksamkeit kann einige Langzeitgedächtnisprobleme lösen. Die Aufmerksamkeit der Vorwärtsspeise wird wie folgt vereinfacht.
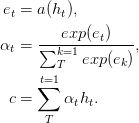
Die Funktion a , eine lernbare Funktion, wird als Feed -Forward -Netzwerk erkannt. In dieser Formulierung kann die Aufmerksamkeit als Erzeugung einer Einbettung von c der Eingangssequenz festgestellt werden, indem ein adaptiver gewichteter Durchschnitt der Zustandssequenz h berechnet wird.
5.2 Implementierung hier
Die Implementierung von Aufmerksamkeit wird hier nicht beschrieben. Beziehen Sie sich bitte direkt auf den Quellcode.
Netzwerkstruktur von Textattbirnn:

6 Han
Han wurde in den hierarchischen Aufmerksamkeitsnetzwerken für die Dokumentklassifizierung vorgeschlagen.
6.1 Beschreibung in Papier
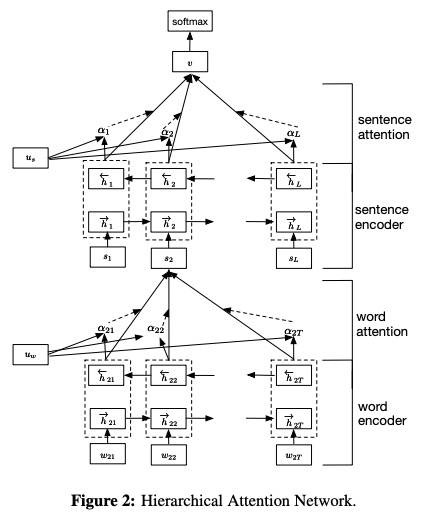
- Wort Encoder . Codierung durch bidirektionale Gru , eine Annotation für ein bestimmtes Wort wird erhalten, indem der vorwärts versteckte Zustand und den rückwärts versteckten Zustand verkettet werden, der die Informationen des gesamten Satzes zusammenfasst, der sich im aktuellen Zeitschritt um Wort zentriert hat.
- Wortaufmerksamkeit . Durch eine einschichtige MLP- und Softmax-Funktion können die normalisierten Wichtigkeitsgewichte über die vorherigen Wortanmerkungen berechnet werden. Berechnen Sie dann den Satzvektor als eine gewichtete Summe der Wortanmerkungen basierend auf den Gewichten.
- Satz Encoder . Verwenden Sie in ähnlicher Weise mit dem Wort Encoder eine bidirektionale Gru , um die Sätze zu codieren, um eine Annotation für einen Satz zu erhalten.
- Satzaufmerksamkeit . Verwenden Sie mit Wortaufmerksamkeit eine Einschicht -MLP- und Softmax-Funktion, um die Gewichte über Satzanmerkungen zu erhalten. Berechnen Sie dann eine gewichtete Summe der Satzanmerkungen basierend auf den Gewichten, um den Dokumentvektor zu erhalten.
- Dokumentklassifizierung . Verwenden Sie die Softmax -Funktion, um die Wahrscheinlichkeit aller Klassen zu berechnen.
6.2 Implementierung hier
Die Umsetzung der Aufmerksamkeit basiert hier auf Feedforwardattention, was der Aufmerksamkeit in Textattbirnn entspricht.
Netzwerkstruktur von Han:
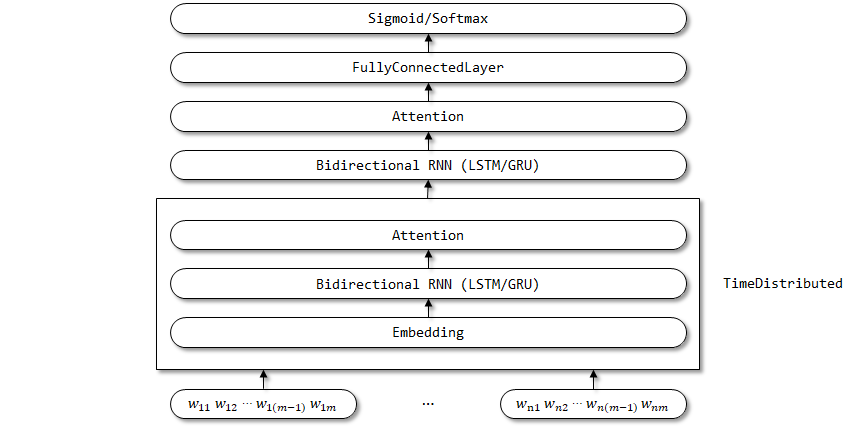
Die Zeitverteilung wird hier verwendet, da die Parameter der Einbettung, der bidirektionalen RNN und der Aufmerksamkeitsschichten für die Zeitschrittdimension erwartet werden.
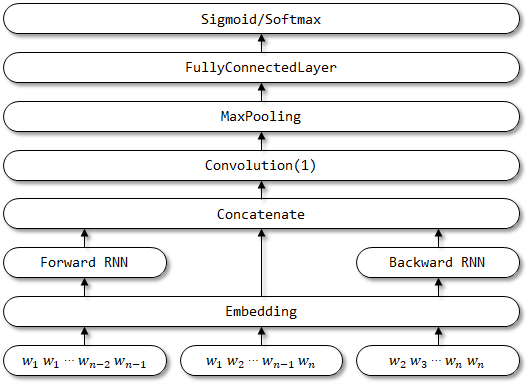
7 rcnn
RCNN wurde in dem Papier vorgeschlagen, das rezidivierende nervige Netzwerke zur Textklassifizierung rezidivierend ist.
7.1 Beschreibung in Papier
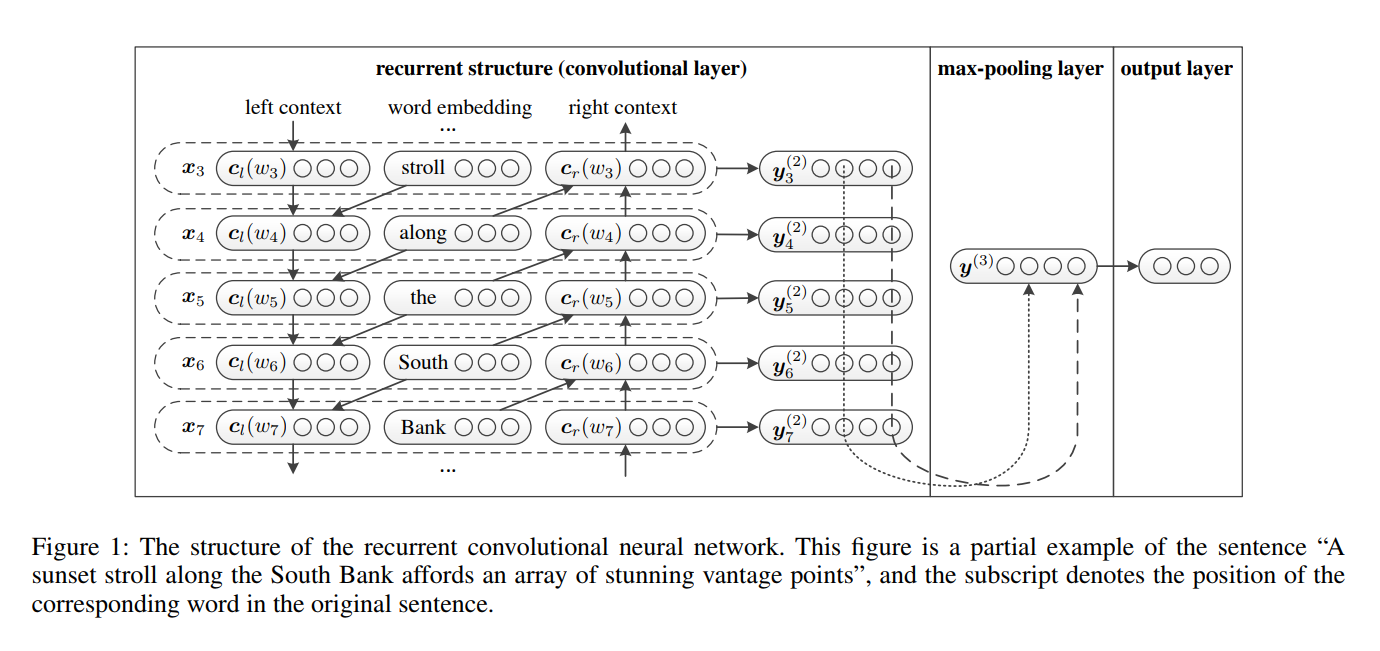
- Wortrepräsentation Lernen . RCNN verwendet eine wiederkehrende Struktur, die ein bidirektionales wiederkehrendes neuronales Netzwerk ist, um die Kontexte zu erfassen. Kombinieren Sie dann das Wort und seinen Kontext, um das Wort zu präsentieren. Und wenden Sie eine lineare Transformation zusammen mit der
tanh -Aktivierung auf die Darstellung an. - Textdarstellung Lernen . Wenn alle Darstellungen von Wörtern berechnet werden, wendet es eine maximale maximale Schicht an, um die wichtigsten Informationen im gesamten Text zu erfassen. Führen Sie schließlich die lineare Transformation durch und wenden Sie die Softmax -Funktion an.
7.2 Implementierung hier
Netzwerkstruktur von RCNN:
8 rcnnvariant
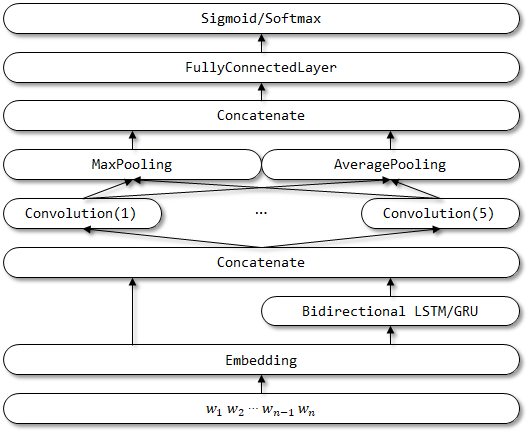
Rcnnvariant ist ein verbessertes Modell, das auf RCNN mit den folgenden Verbesserungen basiert. Es wurden noch keine verwandten Papiere gefunden.
- Die drei Eingänge werden in einzelnen Eingaben geändert. Die Eingabe der linken und rechten Kontexte wird entfernt.
- Verwenden Sie bidirektionale LSTM/Gru anstelle von herkömmlichem RNN für den Codierungskontext.
- Verwenden Sie Multi-Channel-CNN, um die semantischen Vektoren darzustellen.
- Ersetzen Sie die TANH -Aktivierungsschicht durch die Relu -Aktivierungsschicht .
- Verwenden Sie sowohl Averagepooling als auch Maxpooling .
Netzwerkstruktur von rcnnvariant:
Fortgesetzt werden...
Referenz
- Tricksack für eine effiziente Textklassifizierung
- Keras Beispiel imdb fastText
- Faltungsnetzwerke für die Satzklassifizierung
- Keras Beispiel imdb cnn
- Wiederkehrendes neuronales Netzwerk für die Textklassifizierung mit Multi-Task-Lernen
- Übersetzung der neuronalen maschinellen Übersetzung durch gemeinsames Lernen, sich auszurichten und zu übersetzen
- Feed-Forward-Netzwerke mit Aufmerksamkeit können einige Langzeitgedächtnisprobleme lösen
- Cbaziotis 'Aufmerksamkeit
- Hierarchische Aufmerksamkeitsnetzwerke für die Klassifizierung der Dokumente
- Richards Han
- Wiederkehrende Faltungsnetzwerke für die Textklassifizierung
- Airalcorn2's rcnn


