OpenPrompt
v1.0.0
เฟรมเวิร์กโอเพนซอร์ซสำหรับการเรียนรู้ล่วงหน้า
ภาพรวม•การติดตั้ง•วิธีการใช้•เอกสาร•กระดาษ•การอ้างอิง•ประสิทธิภาพ•
./tutorial/9_UltraChat.pypip install openpromptPrompt-Learning เป็นกระบวนทัศน์ล่าสุดในการปรับโมเดลภาษาที่ผ่านการฝึกอบรมมาก่อน (PLMS) ให้เข้ากับงาน NLP ดาวน์สตรีมซึ่งปรับเปลี่ยนข้อความอินพุตด้วยเทมเพลตข้อความและใช้ PLMS โดยตรงเพื่อดำเนินงานที่ผ่านการฝึกอบรมมาก่อน ไลบรารีนี้มีกรอบมาตรฐานยืดหยุ่นและขยายได้เพื่อปรับใช้ไปป์ไลน์การเรียนรู้พรอมต์ OpenPrompt รองรับการโหลด PLMS โดยตรงจาก HuggingFace Transformers ในอนาคตเราจะสนับสนุน PLMS ที่ดำเนินการโดยห้องสมุดอื่น ๆ สำหรับทรัพยากรเพิ่มเติมเกี่ยวกับการเรียนรู้พรอมต์โปรดตรวจสอบรายการกระดาษของเรา
หมายเหตุ: โปรดใช้ Python 3.8+ สำหรับ OpenPrompt
repo ของเราได้รับการทดสอบใน Python 3.8+ และ Pytorch 1.8.1+ , ติดตั้ง OpenPrompt โดยใช้ PIP ดังนี้:
pip install openpromptในการเล่นกับคุณสมบัติล่าสุดคุณยังสามารถติดตั้ง OpenPrompt จากแหล่งที่มา
โคลนที่เก็บจาก GitHub:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installแก้ไขรหัส
python setup.py develop
วัตถุ PromptModel ประกอบด้วย Template PLM , (หรือหลาย) และ A (หรือหลาย) Verbalizer โดยที่คลาส Template ถูกกำหนดให้ห่ออินพุตดั้งเดิมด้วยเทมเพลตและคลาส Verbalizer คือการสร้างการฉายภาพระหว่างฉลากและคำเป้าหมายในคำศัพท์ปัจจุบัน และวัตถุ PromptModel มีส่วนร่วมในการฝึกอบรมและการอนุมาน
ด้วยความเป็นโมดูลและความยืดหยุ่นของ OpenPrompt คุณสามารถพัฒนาไปป์ไลน์การเรียนรู้ได้อย่างง่ายดาย
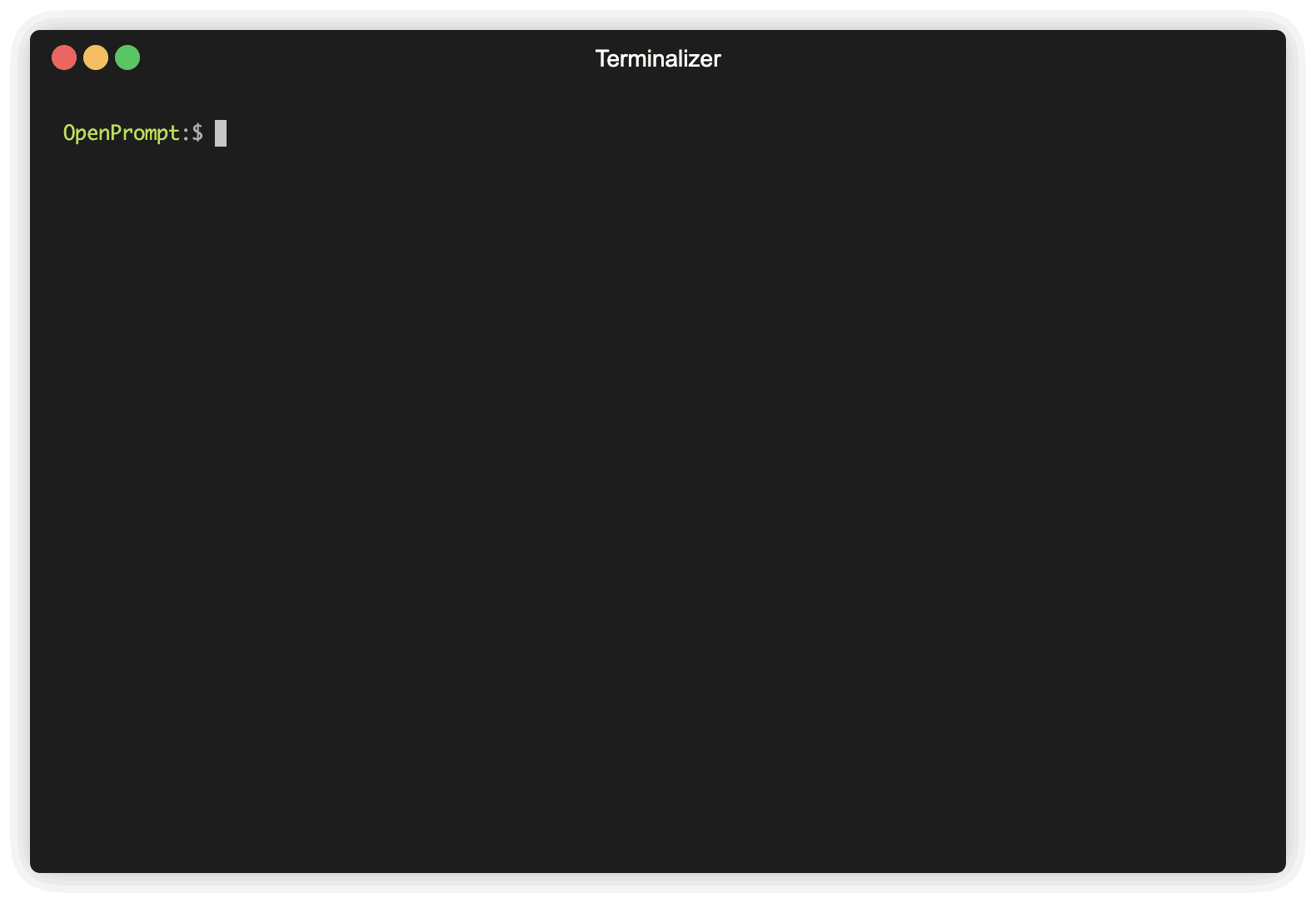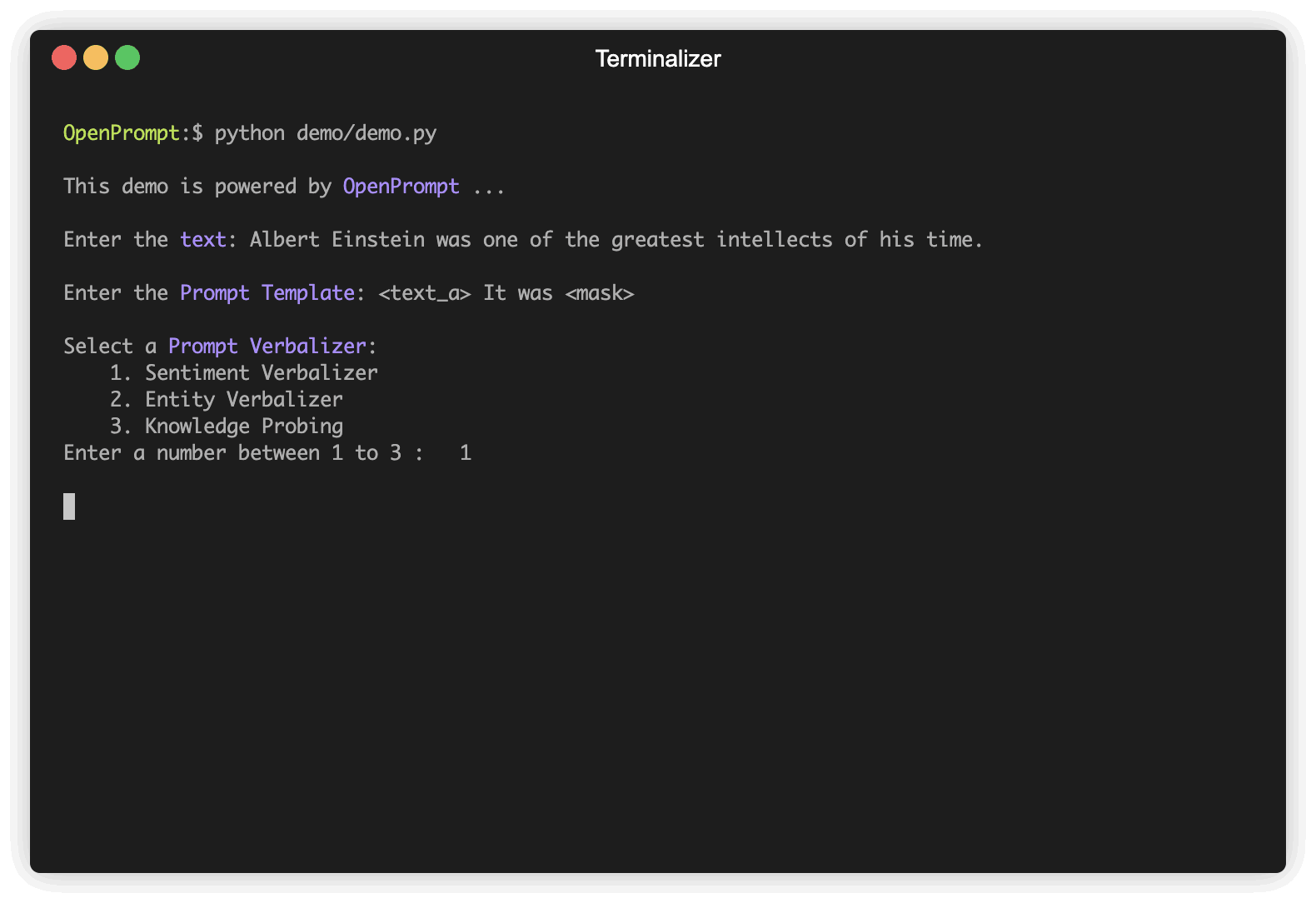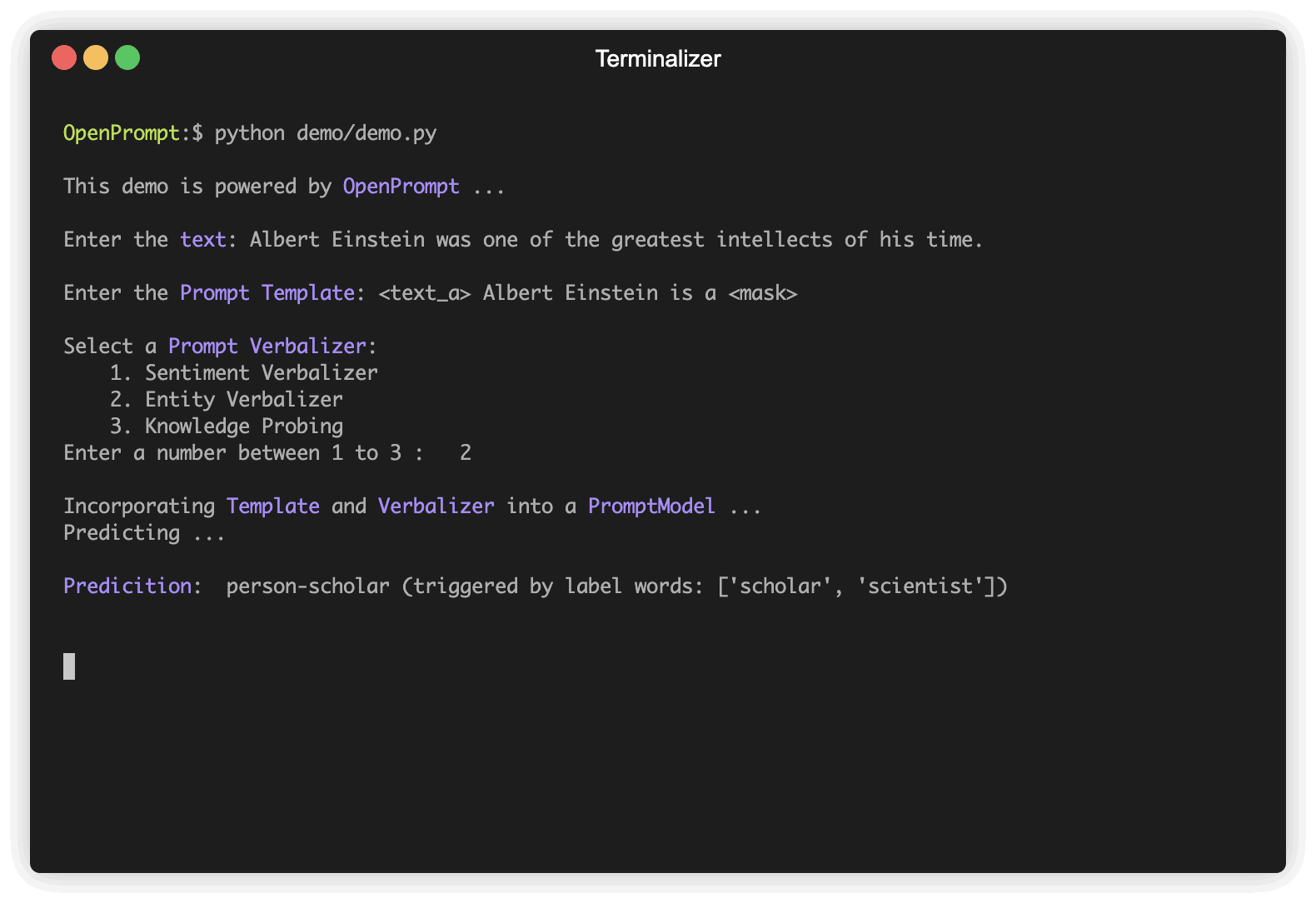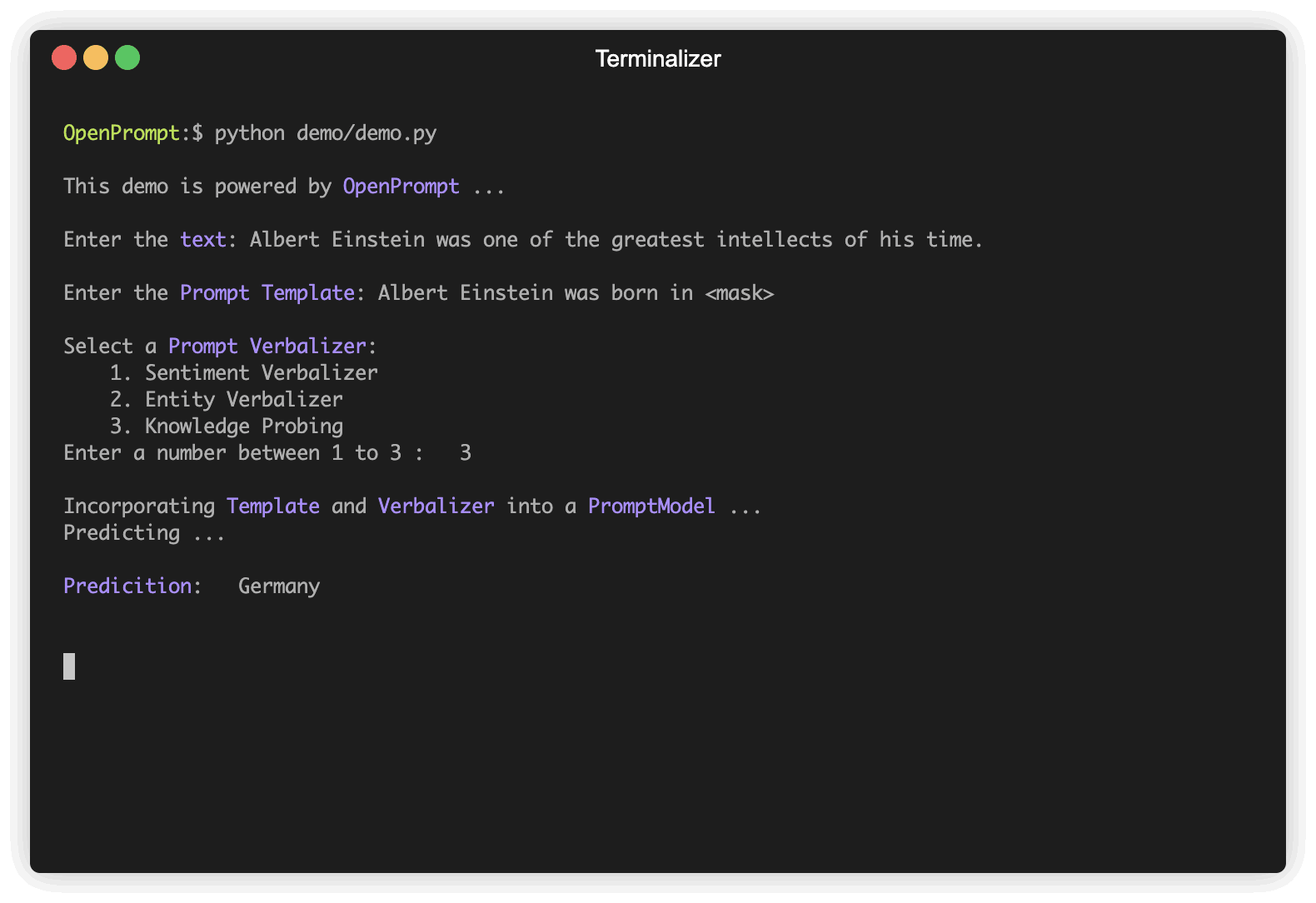
ขั้นตอนแรกคือการกำหนดงาน NLP ปัจจุบันลองคิดดูว่าข้อมูลของคุณเป็นอย่างไรและคุณต้องการอะไรจากข้อมูล! นั่นคือสาระสำคัญของขั้นตอนนี้คือการกำหนด classes และ InputExample ของงาน เพื่อความเรียบง่ายเราใช้การวิเคราะห์ความเชื่อมั่นเป็นตัวอย่าง Tutorial_task
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]เลือก PLM เพื่อสนับสนุนงานของคุณ โมเดลที่แตกต่างกันมีคุณลักษณะที่แตกต่างกันเราขอแนะนำให้คุณใช้ OpenPrompt เพื่อสำรวจศักยภาพของ PLMs ต่างๆ OpenPrompt เข้ากันได้กับโมเดลบน HuggingFace
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Template เป็นตัวดัดแปลงของข้อความอินพุตต้นฉบับซึ่งเป็นหนึ่งในโมดูลที่สำคัญที่สุดในการเรียนรู้ด้วยพรอมต์ เราได้กำหนด text_a ในขั้นตอนที่ 1
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Verbalizer เป็นอีกสิ่งที่สำคัญ (แต่ไม่จำเป็น) ในการเรียนรู้ที่รวดเร็วซึ่งคาดการณ์ฉลากดั้งเดิม (เราได้กำหนดไว้เป็น classes จำได้ไหม) กับชุดคำติดฉลาก นี่คือตัวอย่างที่เราคาดการณ์คลาส negative ไปยังคำที่ไม่ดีและฉายภาพระดับ positive กับคำที่ดียอดเยี่ยมยอดเยี่ยมมาก
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) จากงานตอนนี้เรามี PLM Template และ Verbalizer เรารวมเข้ากับ PromptModel โปรดทราบว่าแม้ว่าตัวอย่างจะรวมโมดูลสามโมดูลอย่างไร้เดียงสา แต่คุณสามารถกำหนดปฏิสัมพันธ์ที่ซับซ้อนบางอย่างได้จริง
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) PromptDataLoader นั้นเป็นเวอร์ชันที่พร้อมท์ของ Pytorch Dataloader ซึ่งรวมถึง Tokenizer , Template และ TokenizerWrapper
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)เสร็จแล้ว! เราสามารถทำการฝึกอบรมและอนุมานได้เช่นเดียวกับกระบวนการอื่น ๆ ใน Pytorch
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'โปรดดูสคริปต์การสอนของเราและเอกสารสำหรับรายละเอียดเพิ่มเติม
เราให้บริการสคริปต์ดาวน์โหลดใน dataset/ โฟลเดอร์อย่าลังเลที่จะใช้เพื่อดาวน์โหลดเกณฑ์มาตรฐาน
มีชุดค่าผสมที่เป็นไปได้มากเกินไปที่ขับเคลื่อนโดย OpenPrompt เราพยายามอย่างเต็มที่เพื่อทดสอบประสิทธิภาพของวิธีการต่าง ๆ โดยเร็วที่สุด ประสิทธิภาพจะได้รับการปรับปรุงอย่างต่อเนื่องเป็นตาราง นอกจากนี้เรายังสนับสนุนให้ผู้ใช้ค้นหาพารามิเตอร์ไฮเปอร์ที่ดีที่สุดสำหรับงานของตนเองและรายงานผลลัพธ์โดยการร้องขอการดึง
การปรับปรุง/เพิ่มประสิทธิภาพที่สำคัญในอนาคต
โปรดอ้างอิงกระดาษของเราหากคุณใช้ OpenPrompt ในงานของคุณ
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}เราขอขอบคุณผู้สนับสนุนทุกคนในโครงการนี้ยินดีต้อนรับผู้มีส่วนร่วมเพิ่มเติม!


