OpenPrompt
v1.0.0
Kerangka kerja open-source untuk pembelajaran cepat.
Tinjauan Umum • Instalasi • Cara menggunakan • Dokumen • Kertas • Kutipan • Kinerja •
./tutorial/9_UltraChat.py .pip install openpromptPrompt-Learning adalah paradigma terbaru untuk mengadaptasi model bahasa pra-terlatih (PLM) untuk menghidupkan tugas NLP, yang memodifikasi teks input dengan template tekstual dan secara langsung menggunakan PLM untuk melakukan tugas yang sudah terlatih. Perpustakaan ini menyediakan kerangka kerja standar, fleksibel, dan dapat diperluas untuk menggunakan pipa pembelajaran prompt. OpenPrompt mendukung pemuatan PLM langsung dari transformator huggingface. Di masa depan, kami juga akan mendukung PLM yang diterapkan oleh perpustakaan lain. Untuk sumber daya lebih lanjut tentang pembelajaran cepat, silakan periksa daftar kertas kami.
Catatan: Harap gunakan Python 3.8+ untuk OpenPrompt
Repo kami diuji pada Python 3.8+ dan Pytorch 1.8.1+ , instal OpenPrompt menggunakan PIP sebagai berikut:
pip install openpromptUntuk bermain dengan fitur terbaru, Anda juga dapat menginstal OpenPrompt dari sumbernya.
Klon Repositori dari GitHub:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installUbah kode
python setup.py develop
Objek PromptModel berisi Template PLM , A (atau beberapa) dan Verbalizer (atau beberapa), di mana kelas Template didefinisikan untuk membungkus input asli dengan templat, dan kelas Verbalizer adalah untuk membangun proyeksi antara label dan kata target dalam kosa kata saat ini. Dan objek PromptModel praktis berpartisipasi dalam pelatihan dan inferensi.
Dengan modularitas dan fleksibilitas OpenPrompt, Anda dapat dengan mudah mengembangkan pipa pembelajaran yang cepat.
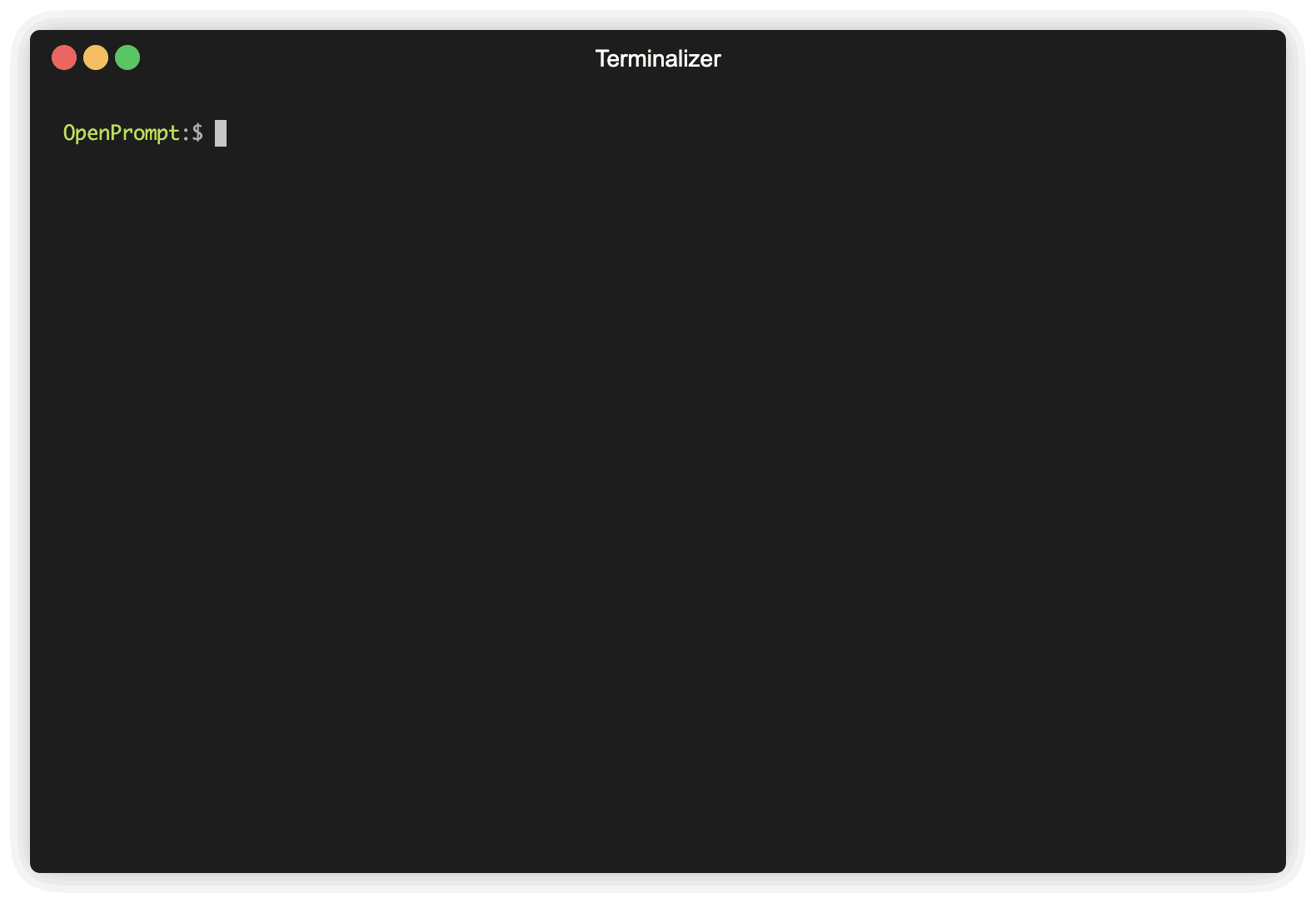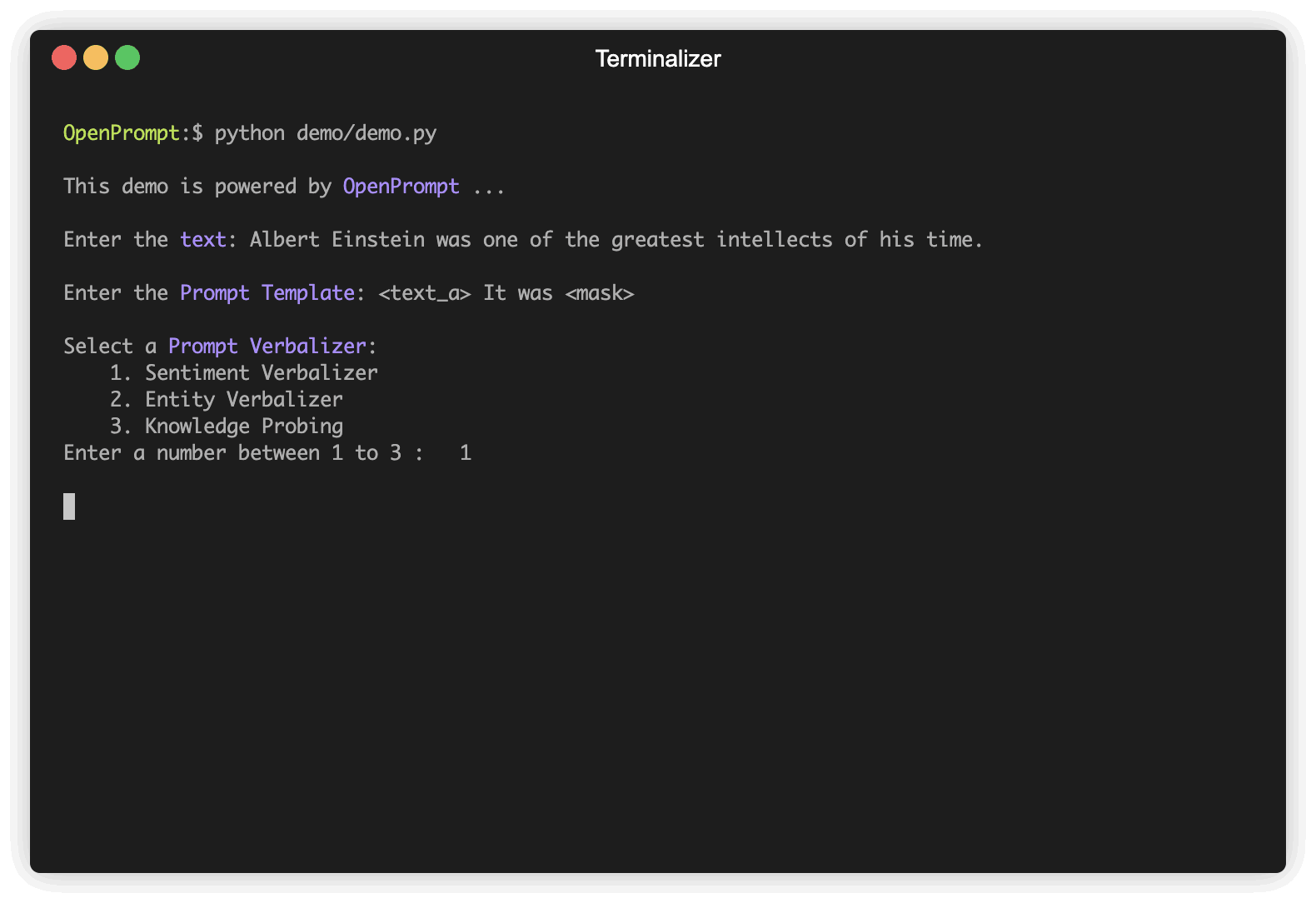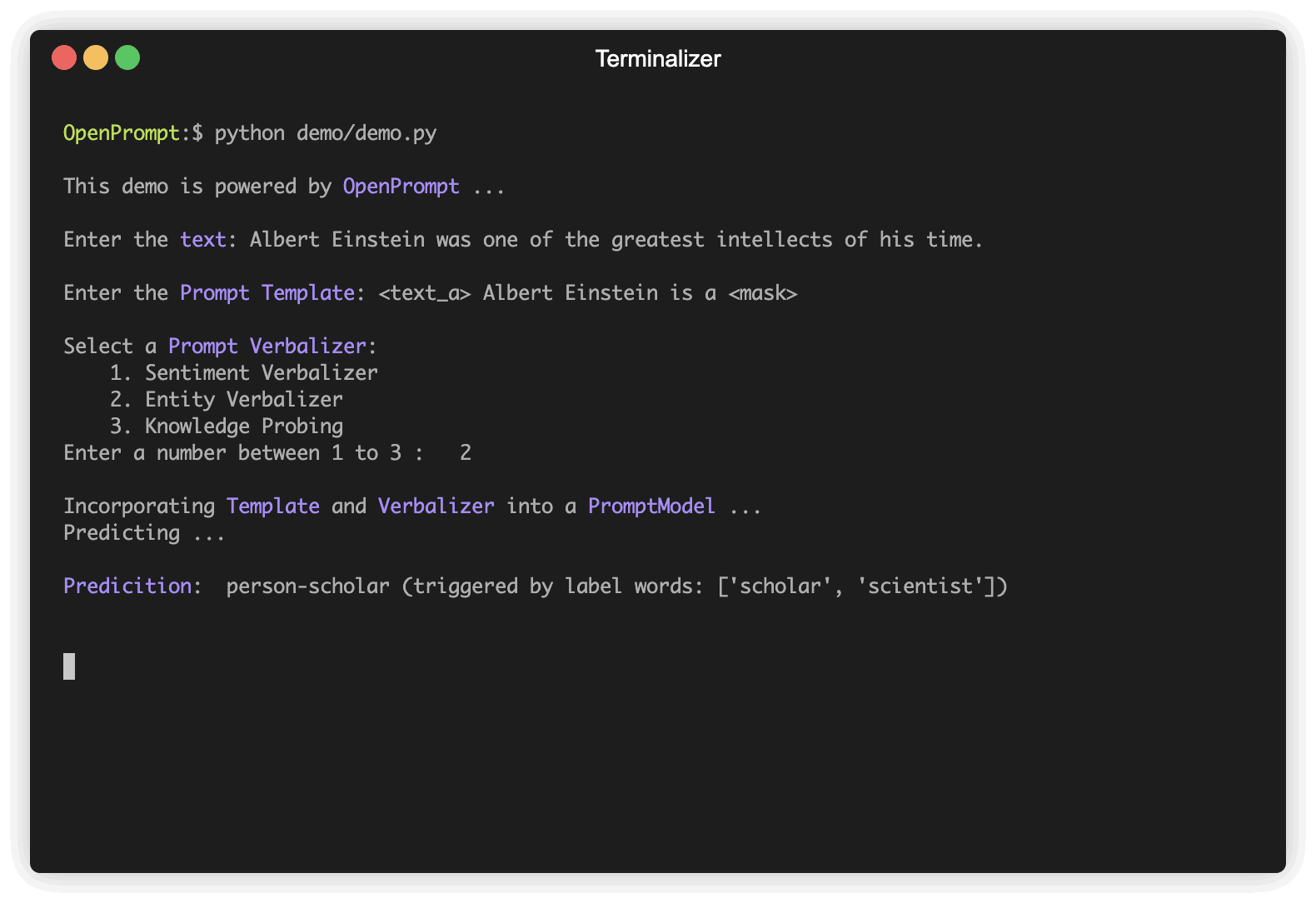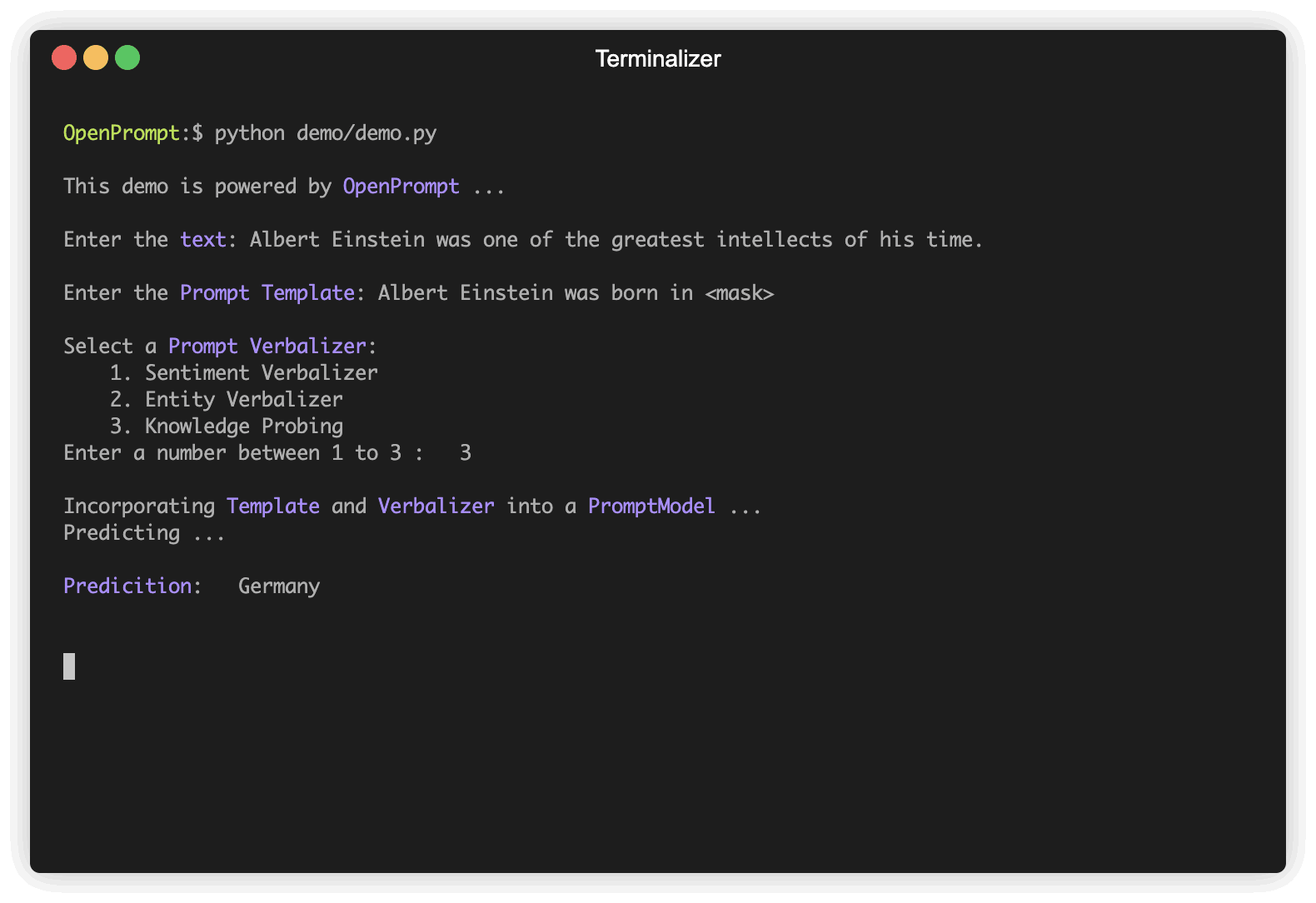
Langkah pertama adalah menentukan tugas NLP saat ini, pikirkan seperti apa data Anda dan seperti apa Anda ingin dari data! Artinya, esensi dari langkah ini adalah untuk menentukan classes dan InputExample tugas. Untuk kesederhanaan, kami menggunakan analisis sentimen sebagai contoh. tutorial_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]Pilih PLM untuk mendukung tugas Anda. Model yang berbeda memiliki atribut yang berbeda, kami mendorong Anda untuk menggunakan OpenPromppt untuk mengeksplorasi potensi berbagai PLM. OpenPrompt kompatibel dengan model di Huggingface.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Template adalah pengubah teks input asli, yang juga merupakan salah satu modul terpenting dalam pembelajaran prompt. Kami telah mendefinisikan text_a pada langkah 1.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Verbalizer adalah penting lainnya (tetapi tidak perlu) dalam pembelajaran cepat, yang memproyeksikan label asli (kami telah mendefinisikannya sebagai classes , ingat?) Untuk serangkaian kata label. Berikut adalah contoh bahwa kami memproyeksikan kelas negative untuk kata buruk, dan memproyeksikan kelas positive untuk kata -kata yang baik, luar biasa, hebat.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) Mengingat tugasnya, sekarang kami memiliki PLM , Template dan Verbalizer , kami menggabungkannya menjadi PromptModel . Perhatikan bahwa meskipun contohnya secara naif menggabungkan tiga modul, Anda benar -benar dapat mendefinisikan beberapa interaksi yang rumit di antara mereka.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) PromptDataLoader pada dasarnya adalah versi cepat dari Pytorch Dataloader, yang juga termasuk Tokenizer , Template dan TokenizerWrapper .
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)Selesai! Kami dapat melakukan pelatihan dan inferensi sama dengan proses lain di Pytorch.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'Silakan merujuk ke skrip tutorial kami, dan dokumentasi untuk detail lebih lanjut.
Kami menyediakan serangkaian skrip unduhan dalam dataset/ folder, jangan ragu untuk menggunakannya untuk mengunduh tolok ukur.
Ada terlalu banyak kemungkinan kombinasi yang ditenagai oleh OpenPrompt. Kami berusaha sebaik mungkin untuk menguji kinerja berbagai metode sesegera mungkin. Kinerja akan terus diperbarui ke dalam tabel. Kami juga mendorong pengguna untuk menemukan hyper-parameter terbaik untuk tugas mereka sendiri dan melaporkan hasilnya dengan membuat permintaan tarik.
Peningkatan/peningkatan besar di masa depan.
Harap kutip kertas kami jika Anda menggunakan OpenPrompt dalam pekerjaan Anda
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}Kami berterima kasih kepada semua kontributor untuk proyek ini, lebih banyak kontributor dipersilakan!


