OpenPrompt
v1.0.0
Un marco de código abierto para el aprendizaje adicional.
Descripción general • Instalación • Cómo usar • Docios • Papel • Cita • rendimiento •
./tutorial/9_UltraChat.py .pip install openpromptEl aprendizaje adicional es el último paradigma para adaptar los modelos de lenguaje previamente capacitados (PLMS) a las tareas de NLP aguas abajo, que modifica el texto de entrada con una plantilla textual y usa directamente PLMS para realizar tareas previamente capacitadas. Esta biblioteca proporciona un marco estándar, flexible y extensible para implementar la tubería de aprendizaje de aviso. OpenPrompt admite la carga de PLM directamente de Huggingface Transformers. En el futuro, también admitiremos PLM implementados por otras bibliotecas. Para obtener más recursos sobre el aprendizaje adicional, consulte nuestra lista de documentos.
Nota: Utilice Python 3.8+ para OpenPrompt
Nuestro repositorio se prueba en Python 3.8+ y Pytorch 1.8.1+ , instale OpenPrompt usando PIP de la siguiente manera:
pip install openpromptPara jugar con las últimas funciones, también puede instalar OpenPrompt desde la fuente.
Clon el repositorio de GitHub:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installModificar el código
python setup.py develop
Un objeto PromptModel contiene una plantación PLM , una Template (o múltiple) y un Verbalizer (o múltiple), donde la clase Template se define para envolver la entrada original con plantillas, y la clase Verbalizer es construir una proyección entre etiquetas y palabras de destino en el vocabulario actual. Y un objeto PromptModel prácticamente participa en capacitación e inferencia.
Con la modularidad y flexibilidad de OpenPrompt, puede desarrollar fácilmente una tubería de aprendizaje de aviso.
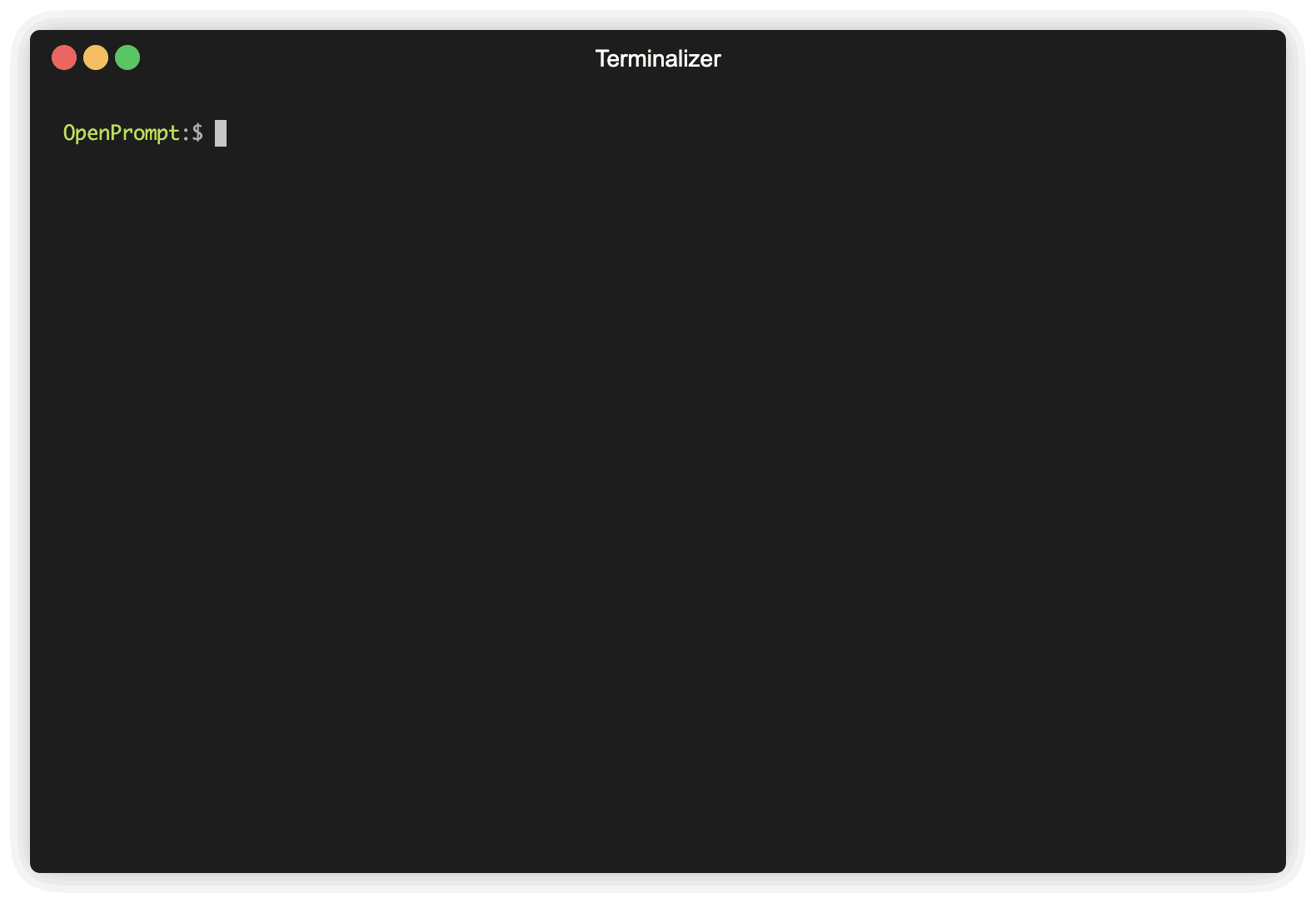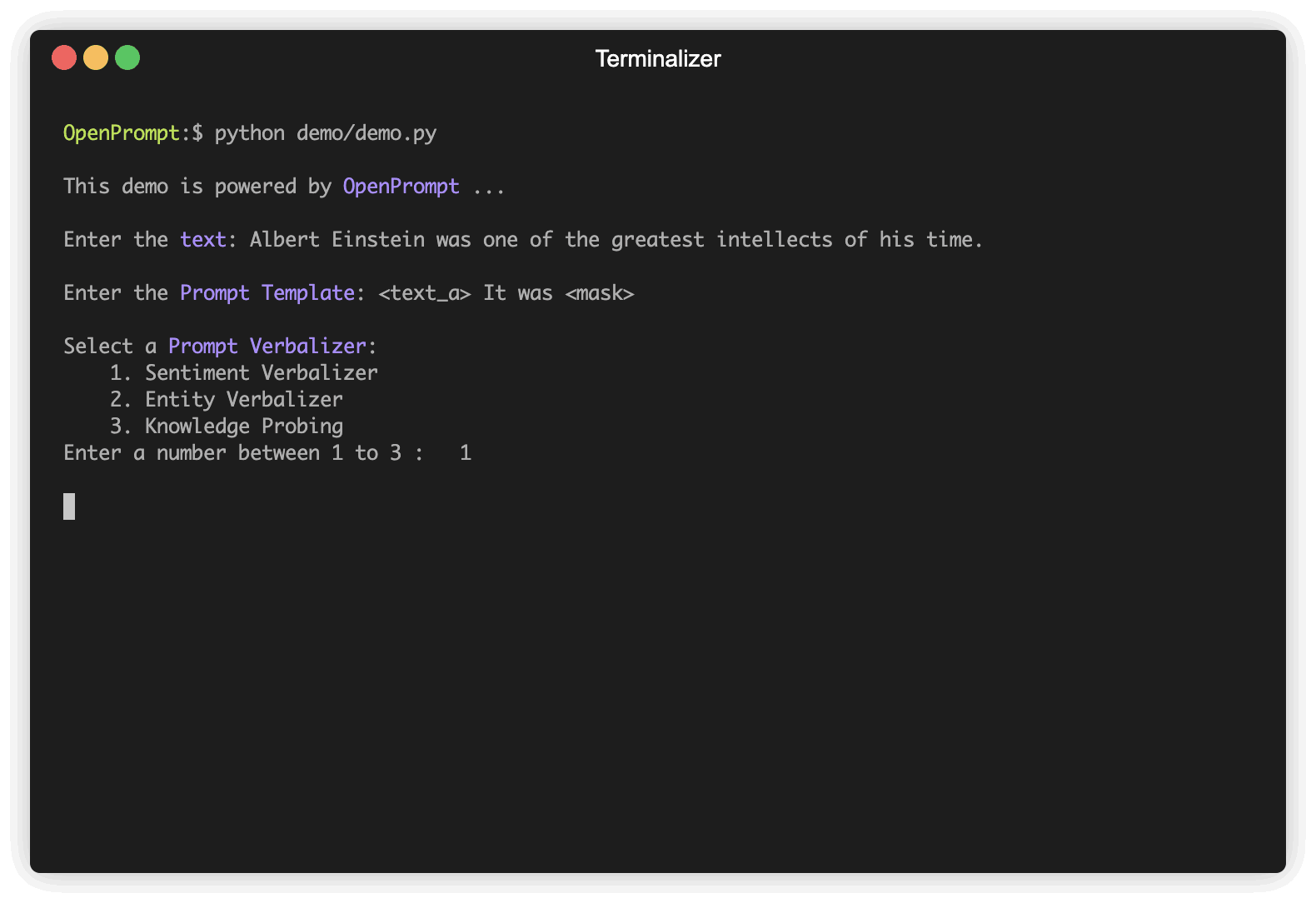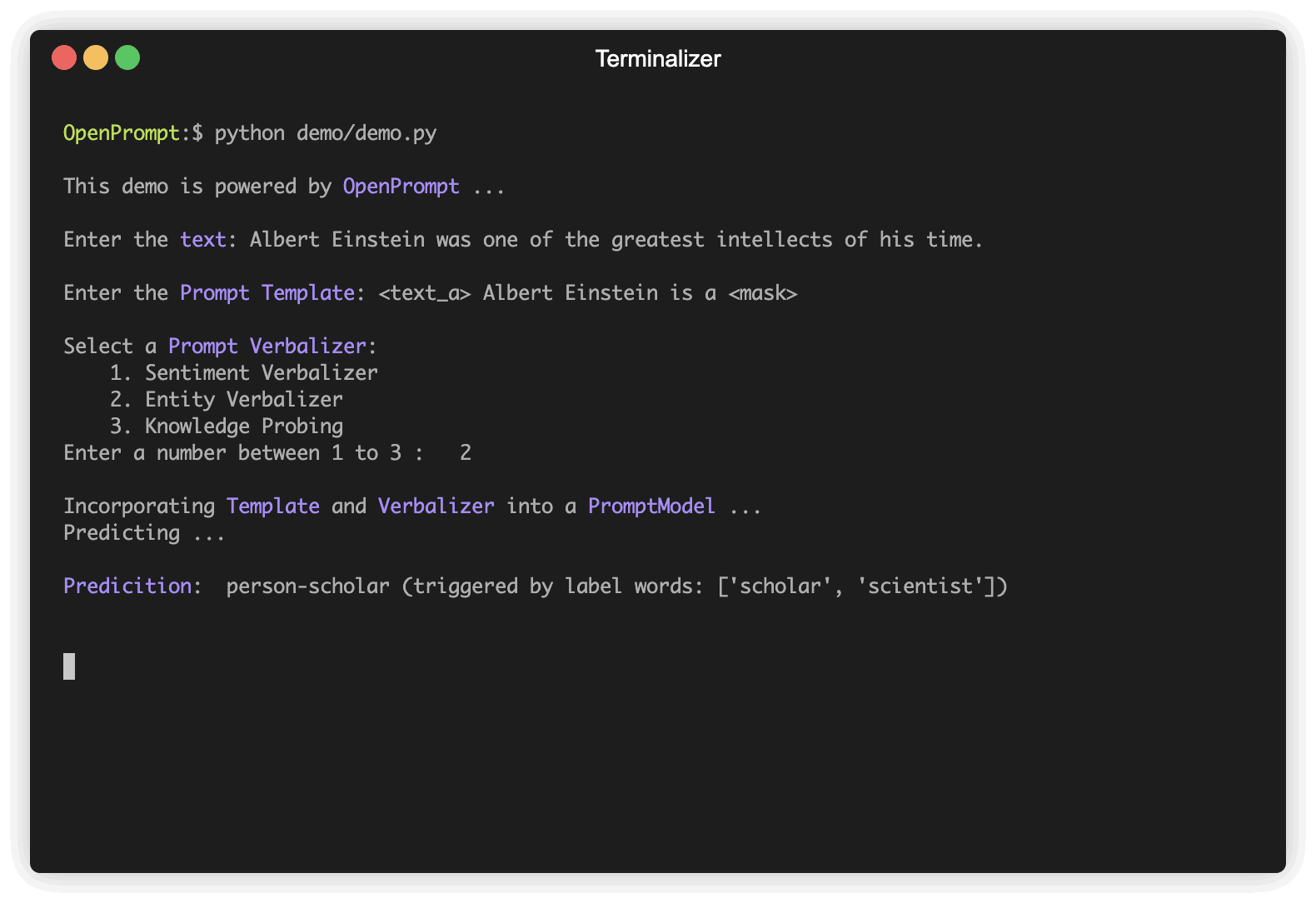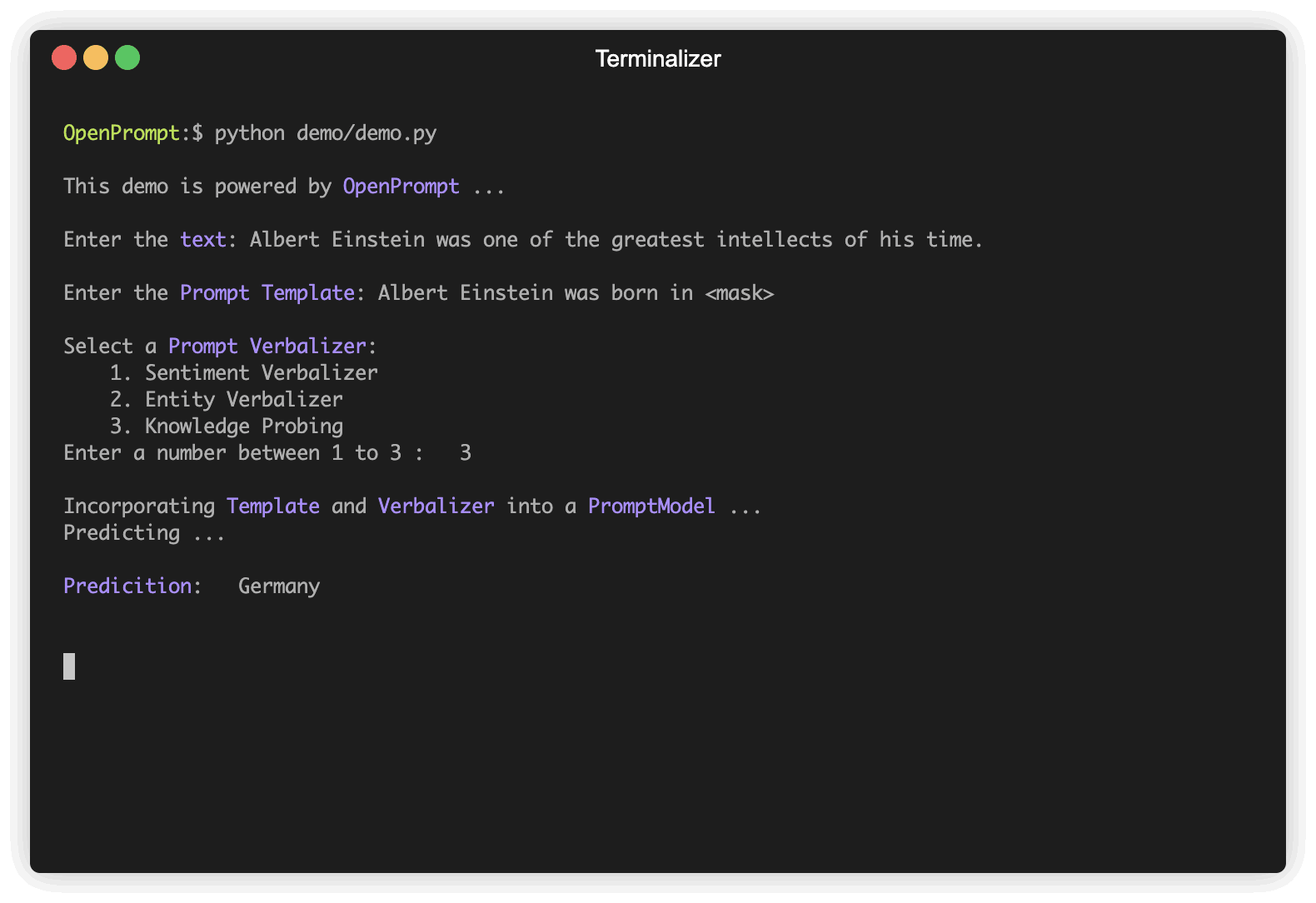
El primer paso es determinar la tarea NLP actual, pensar en cómo se ven sus datos y cómo desea de los datos. Es decir, la esencia de este paso es determinar las classes y la InputExample de la tarea. Para simplificar, utilizamos el análisis de sentimientos como ejemplo. Tutorial_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]Elija un PLM para apoyar su tarea. Diferentes modelos tienen diferentes atributos, le anotamos que use OpenPrompt para explorar el potencial de varios PLM. OpenPrompt es compatible con modelos en Huggingface.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Una Template es un modificador del texto de entrada original, que también es uno de los módulos más importantes en el aprendizaje adicional. Hemos definido text_a en el paso 1.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Un Verbalizer es otro importante (pero no necesario) en el aprendizaje inmediato, que proyecta las etiquetas originales (las hemos definido como classes , ¿recuerdas?) A un conjunto de palabras de etiqueta. Aquí hay un ejemplo de que proyectamos la clase negative a la palabra mala, y proyectamos la clase positive a las palabras buenas, maravillosas, geniales.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) Dada la tarea, ahora tenemos un PLM , una Template y un Verbalizer , los combinamos en un PromptModel . Tenga en cuenta que aunque el ejemplo combina ingenuamente los tres módulos, en realidad puede definir algunas interacciones complicadas entre ellos.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) Un PromptDataLoader es básicamente una versión rápida de Pytorch DataLoader, que también incluye un Tokenizer , una Template y un TokenizerWrapper .
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)¡Hecho! Podemos realizar capacitación e inferencia lo mismo que otros procesos en Pytorch.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'Consulte nuestros scripts de tutoriales y documentación para obtener más detalles.
Proporcionamos una serie de scripts de descarga en el dataset/ carpeta, no dude en usarlos para descargar puntos de referencia.
Hay demasiadas combinaciones posibles impulsadas por OpenPrompt. Estamos haciendo todo lo posible para probar el rendimiento de los diferentes métodos lo antes posible. El rendimiento se actualizará constantemente en las tablas. También alentamos a los usuarios a encontrar los mejores hiperparametros para sus propias tareas e informar los resultados realizando una solicitud de extracción.
Mejora/mejora importantes en el futuro.
Por favor cita nuestro documento si usa OpenPrompt en su trabajo
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}Agradecemos a todos los contribuyentes a este proyecto, ¡más contribuyentes son bienvenidos!


