OpenPrompt
v1.0.0
Un cadre open source pour l'apprentissage rapide.
Présentation • Installation • Comment utiliser • Docs • Papier • Citation • Performance •
./tutorial/9_UltraChat.py .pip install openpromptL'apprentissage rapide est le dernier paradigme à adapter les modèles de langage pré-formé (PLMS) aux tâches NLP en aval, qui modifie le texte d'entrée avec un modèle textuel et utilise directement PLMS pour effectuer des tâches pré-formées. Cette bibliothèque fournit un framework standard, flexible et extensible pour déployer le pipeline d'invite. OpenPrompt prend en charge le chargement des plms directement à partir de transformateurs HuggingFace. À l'avenir, nous prendrons également en charge les PLM implémentés par d'autres bibliothèques. Pour plus de ressources sur l'invite, veuillez consulter notre liste de documents.
Remarque: veuillez utiliser Python 3.8+ pour OpenPrompt
Notre dépôt est testé sur Python 3.8+ et Pytorch 1.8.1+ , installez OpenPrompt en utilisant PIP comme suit:
pip install openpromptPour jouer avec les dernières fonctionnalités, vous pouvez également installer OpenPrompt à partir de la source.
Clone le référentiel de GitHub:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installModifier le code
python setup.py develop
Un objet PromptModel contient un Template PLM , un (ou plusieurs) et un (ou plusieurs) Verbalizer , où la classe Template est définie pour envelopper l'entrée d'origine avec des modèles, et la classe Verbalizer est de construire une projection entre les étiquettes et les mots cibles dans le vocabulaire actuel. Et un objet PromptModel participe pratiquement à la formation et à l'inférence.
Avec la modularité et la flexibilité d'OpenProprit, vous pouvez facilement développer un pipeline d'apprentissage rapide.
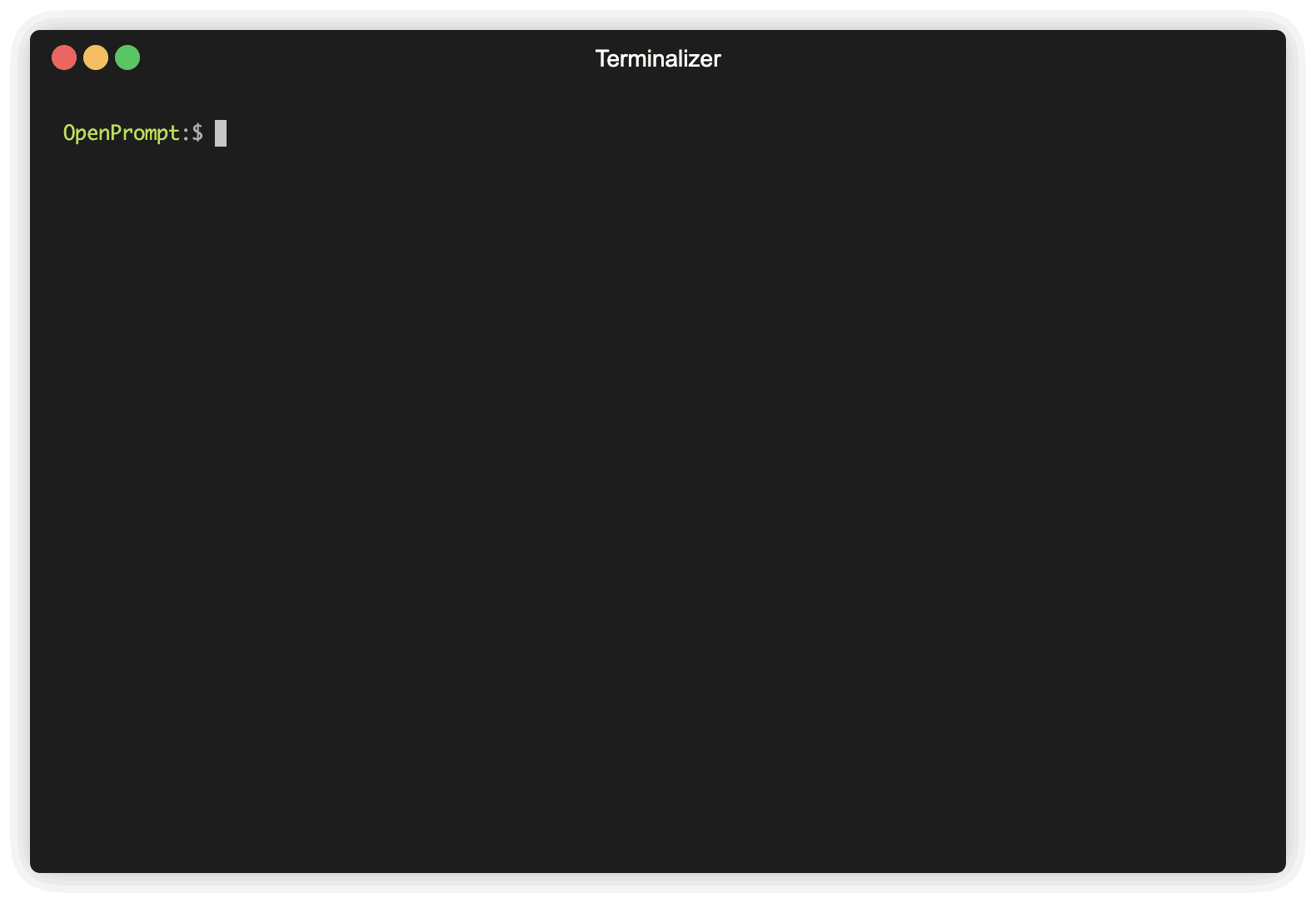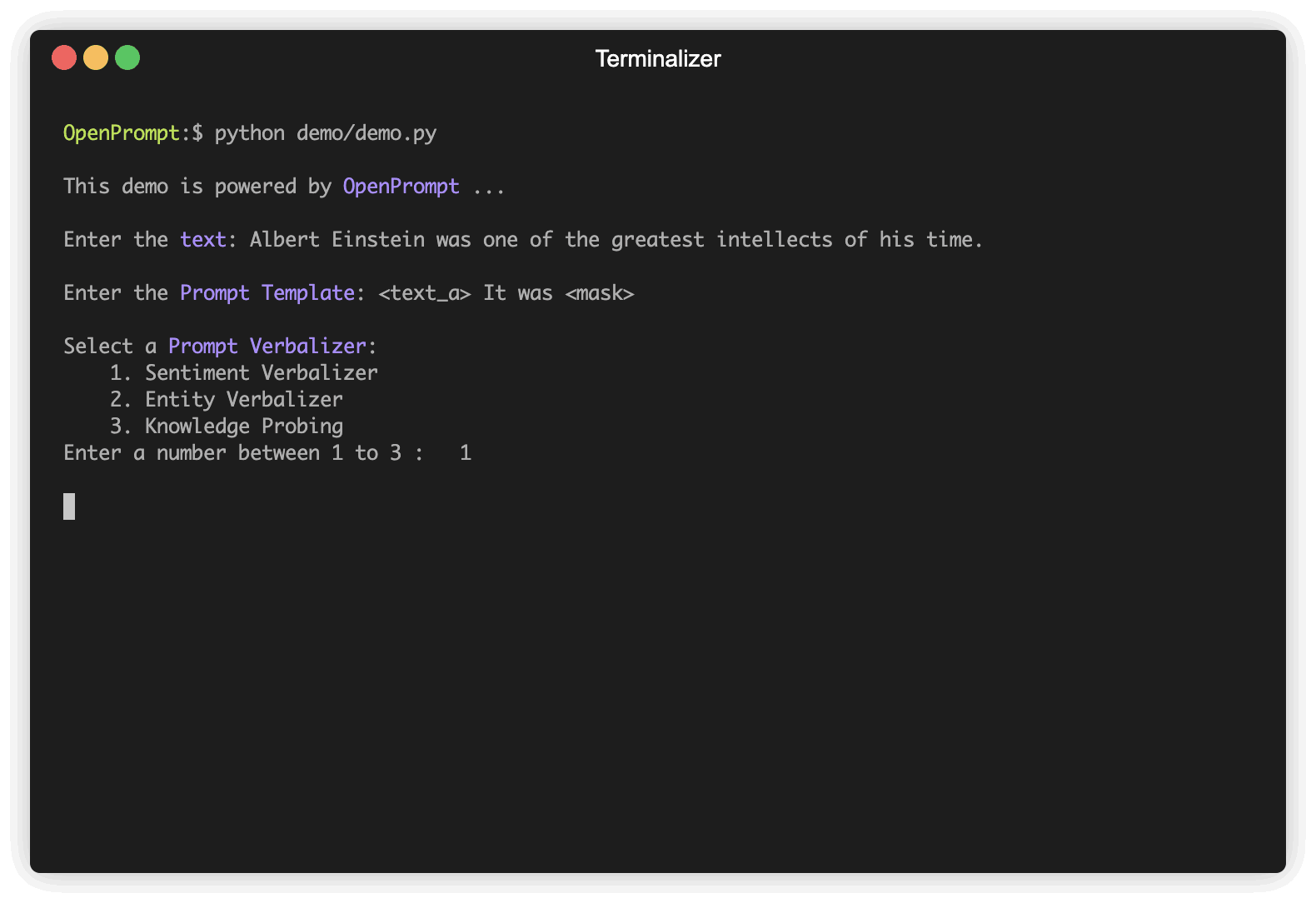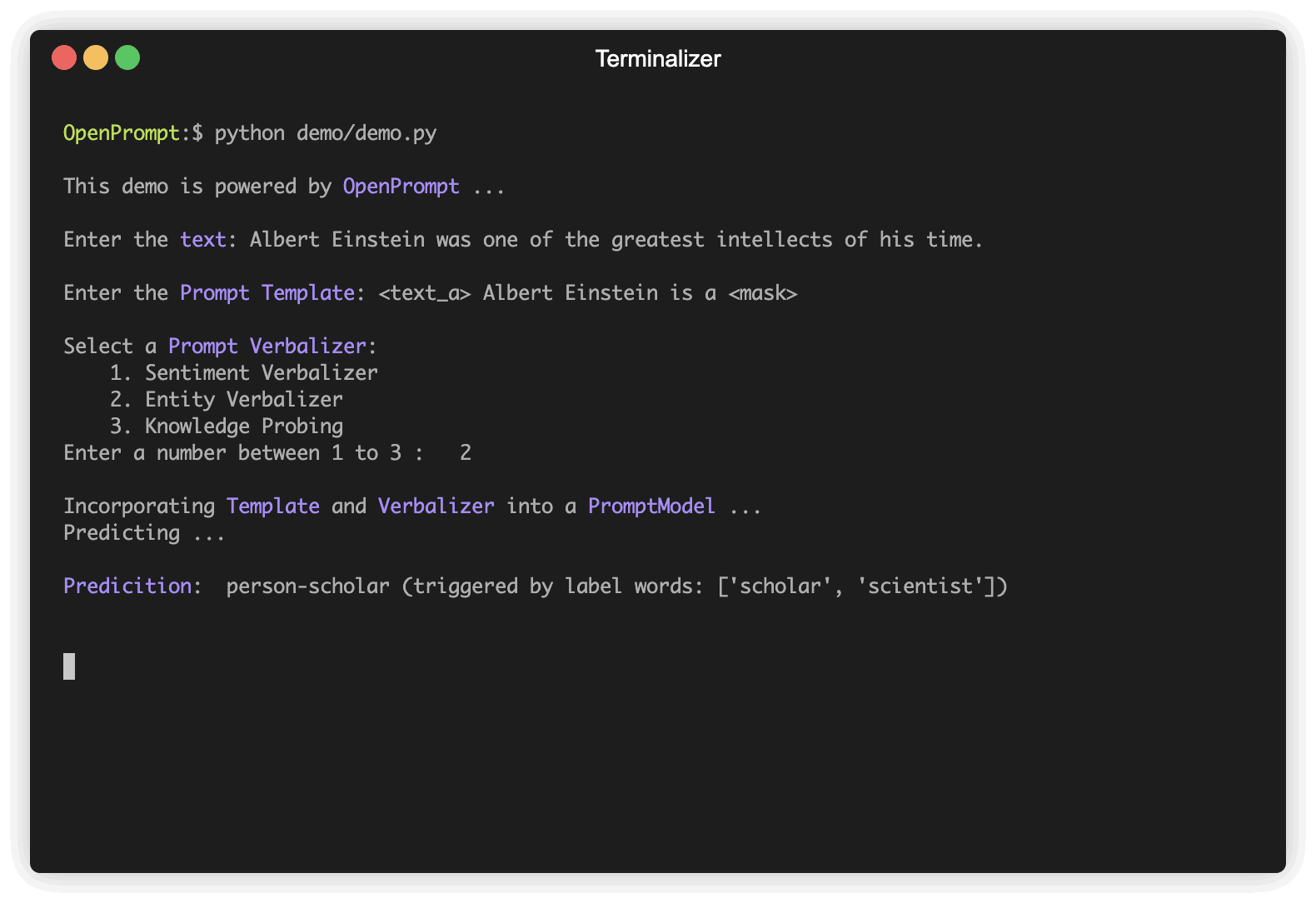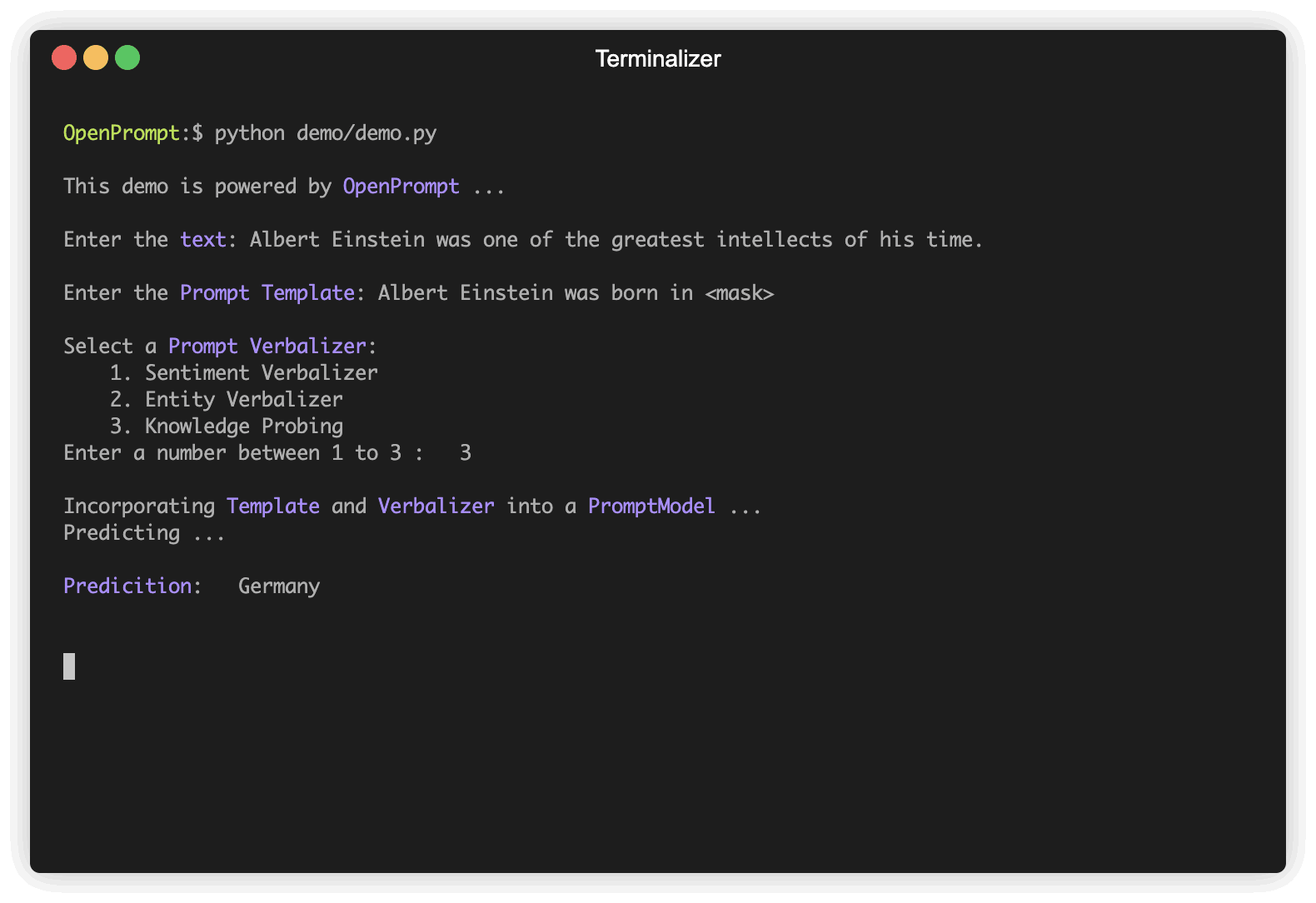
La première étape consiste à déterminer la tâche NLP actuelle, à réfléchir à ce à quoi ressemblent vos données et à ce que vous voulez des données! C'est-à-dire que l'essence de cette étape est de déterminer les classes et l' InputExample de la tâche. Pour plus de simplicité, nous utilisons l'analyse des sentiments comme exemple. tutoriel_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]Choisissez un PLM pour soutenir votre tâche. Différents modèles ont des attributs différents, nous vous encourageons à utiliser OpenPrompt pour explorer le potentiel de divers PLM. OpenPrompt est compatible avec les modèles sur HuggingFace.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Un Template est un modificateur du texte d'entrée d'origine, qui est également l'un des modules les plus importants de l'apprentissage rapide. Nous avons défini text_a à l'étape 1.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Un Verbalizer est un autre important (mais pas nécessaire) en apprentissage rapide, qui projette les étiquettes originales (nous les avons définies comme classes , vous souvenez-vous?) À un ensemble de mots d'étiquette. Voici un exemple que nous projetons la classe negative au mot mauvais, et projetons la classe positive aux mots bons, merveilleux, super.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) Compte tenu de la tâche, nous avons maintenant un PLM , un Template et un Verbalizer , nous les combinons dans un PromptModel . Notez que bien que l'exemple combine naïvement les trois modules, vous pouvez réellement définir des interactions compliquées entre eux.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) Un PromptDataLoader est essentiellement une version rapide de Pytorch DatalOader, qui comprend également un Tokenizer , un Template et un TokenizerWrapper .
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)Fait! Nous pouvons mener la formation et l'inférence de la même manière que les autres processus de Pytorch.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'Veuillez vous référer à nos scripts de tutoriel et à la documentation pour plus de détails.
Nous fournissons une série de scripts de téléchargement dans l' dataset/ dossier, n'hésitez pas à les utiliser pour télécharger des repères.
Il y a trop de combinaisons possibles propulsées par OpenPrompt. Nous faisons de notre mieux pour tester les performances de différentes méthodes dès que possible. Les performances seront constamment mises à jour dans les tables. Nous encourageons également les utilisateurs à trouver les meilleurs hyper-paramètres pour leurs propres tâches et à signaler les résultats en faisant une demande de traction.
Amélioration / amélioration majeure à l'avenir.
Veuillez citer notre papier si vous utilisez OpenProrompt dans votre travail
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}Nous remercions tous les contributeurs de ce projet, plus de contributeurs sont les bienvenus!


