OpenPrompt
v1.0.0
إطار مفتوح المصدر للتعلم المطري.
نظرة عامة • التثبيت • كيفية الاستخدام • المستندات • الورق • الاقتباس • الأداء • الأداء •
./tutorial/9_UltraChat.py .pip install openpromptالتعلم المطالب هو أحدث نموذج لتكييف نماذج اللغة التي تم تدريبها مسبقًا (PLMS) لمهام NLP المصب ، والتي تعدل نص الإدخال باستخدام قالب نصي ويستخدم PLMS مباشرة لإجراء المهام التي تم تدريبها مسبقًا. توفر هذه المكتبة إطارًا قياسيًا ومرنًا ويمكن توسيعه لنشر خط أنابيب التعليم المطالبات. يدعم OpenPrompt تحميل PLMs مباشرة من محولات Huggingface. في المستقبل ، سندعم أيضًا PLMs التي تنفذها المكتبات الأخرى. لمزيد من الموارد حول التعلم المطالبات ، يرجى التحقق من قائمة الورق الخاصة بنا.
ملاحظة: يرجى استخدام Python 3.8+ لـ OpenPrompt
يتم اختبار ريبو لدينا على Python 3.8+ و Pytorch 1.8.1+ ، قم بتثبيت OpenPrompt باستخدام PIP على النحو التالي:
pip install openpromptللعب مع أحدث الميزات ، يمكنك أيضًا تثبيت OpenPrompt من المصدر.
استنساخ المستودع من جيثب:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installتعديل الكود
python setup.py develop
يحتوي كائن PromptModel على PLM ، Template (أو متعددة) و (أو متعددة) Verbalizer (أو متعدد) ، حيث يتم تعريف فئة Template لالتفاف المدخلات الأصلية بالقوالب ، والفئة Verbalizer هي بناء إسقاط بين الملصقات والكلمات المستهدفة في المفردات الحالية. ويشارك كائن PromptModel عمليًا في التدريب والاستدلال.
مع النموذجية ومرونة OpenPrompt ، يمكنك بسهولة تطوير خط أنابيب للتعلم المطالبات.
الخطوة الأولى هي تحديد مهمة NLP الحالية ، فكر في شكل بياناتك وما تريده من البيانات! وهذا يعني أن جوهر هذه الخطوة هو تحديد classes InputExample للمهمة. من أجل البساطة ، نستخدم تحليل المشاعر كمثال. Tutorial_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]اختر PLM لدعم مهمتك. النماذج المختلفة لها سمات مختلفة ، ونشجعك على استخدام OpenPrompt لاستكشاف إمكانات PLMs المختلفة. OpenPrompt متوافق مع النماذج على Luggingface.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Template هو معدّل لنص الإدخال الأصلي ، والذي يعد أيضًا أحد أهم الوحدات في التعلم المطالبات. لقد حددنا text_a في الخطوة 1.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
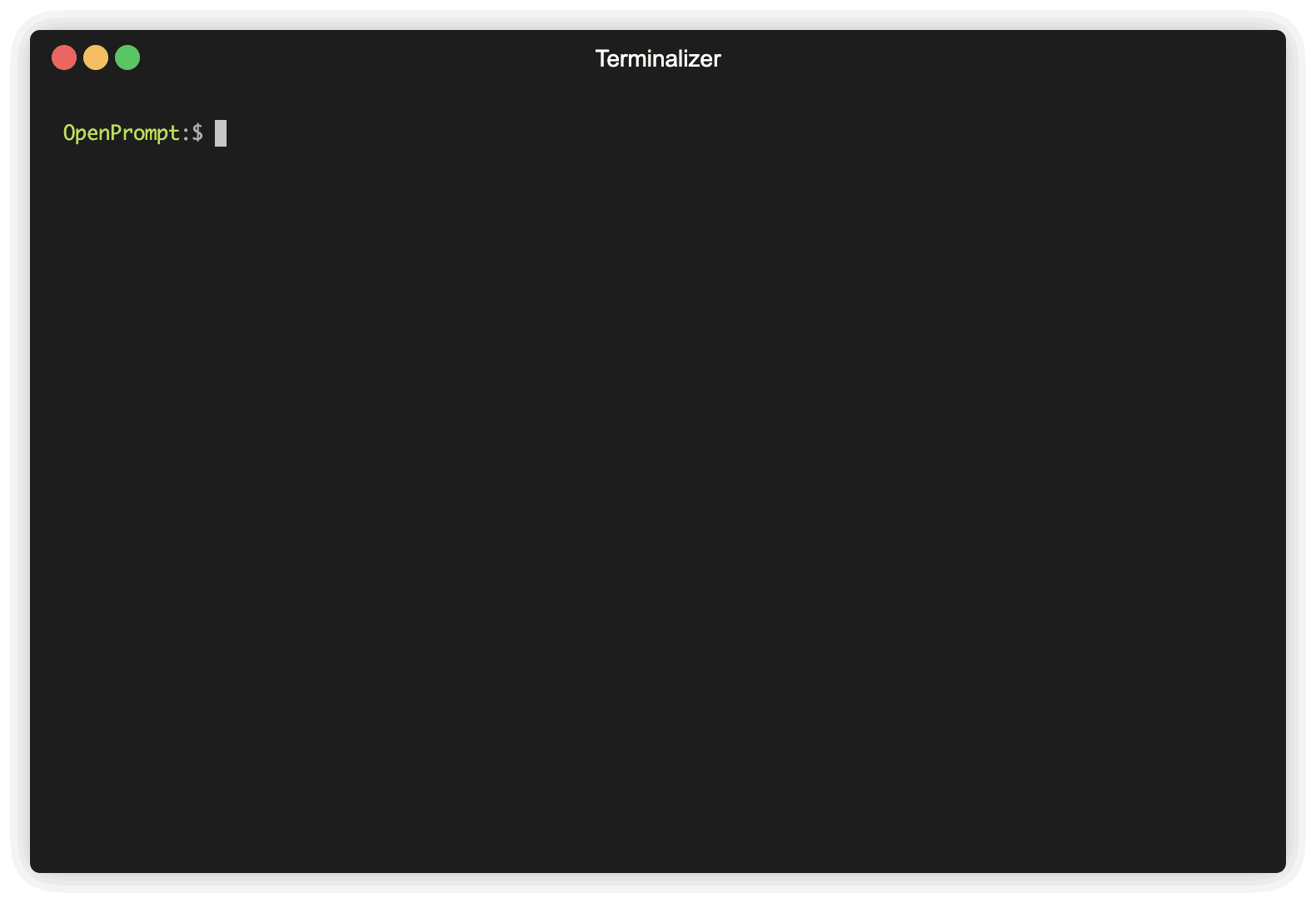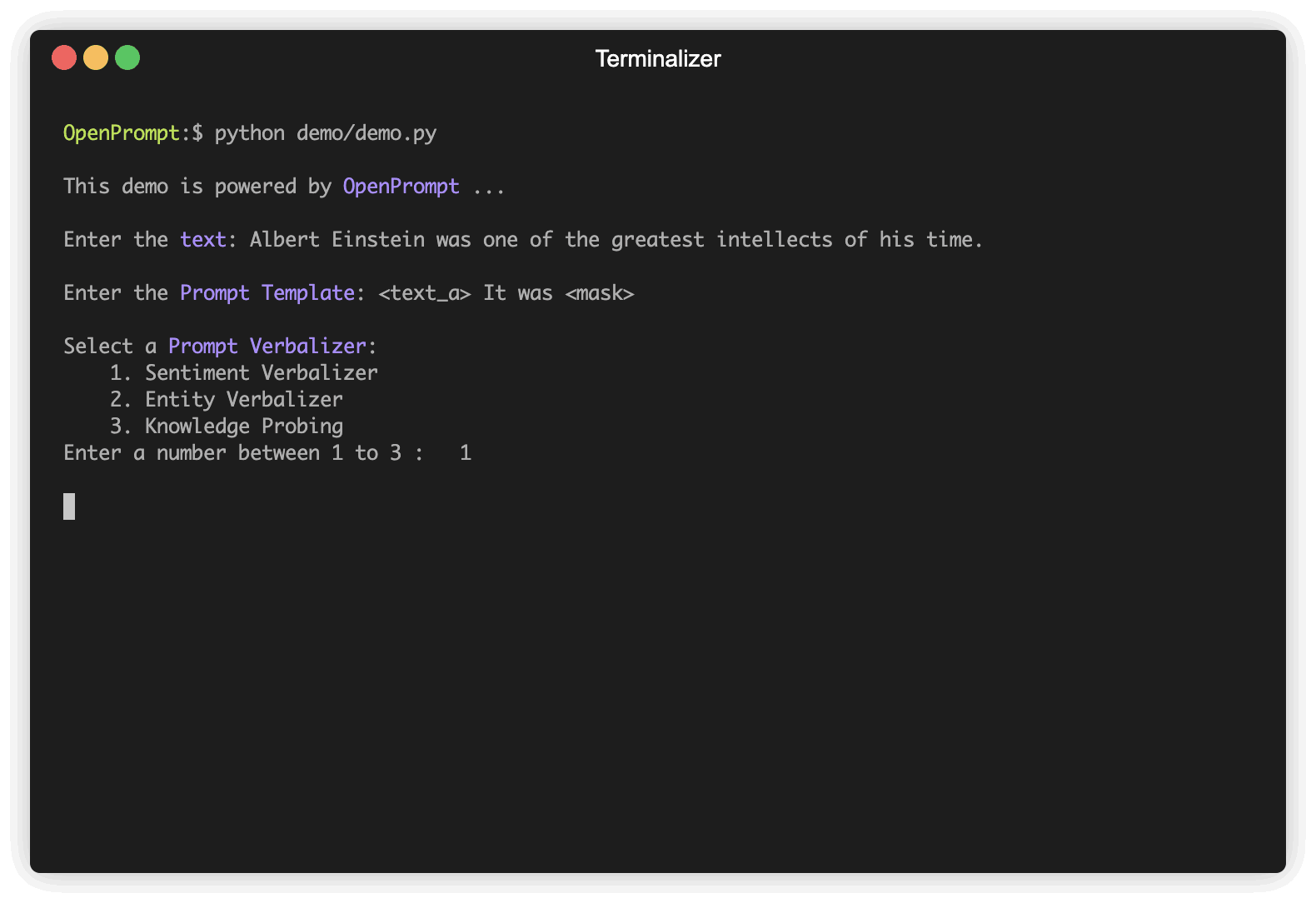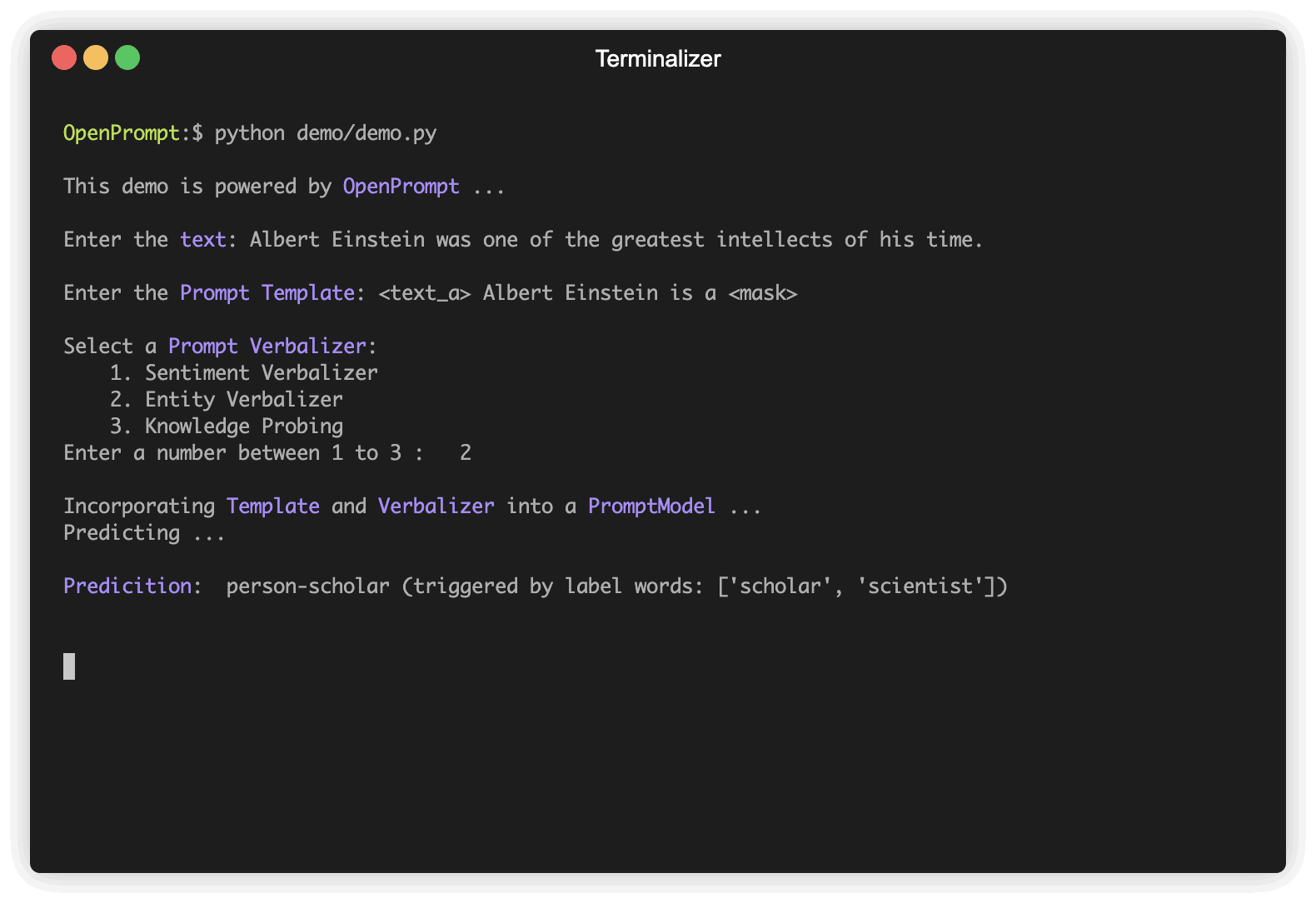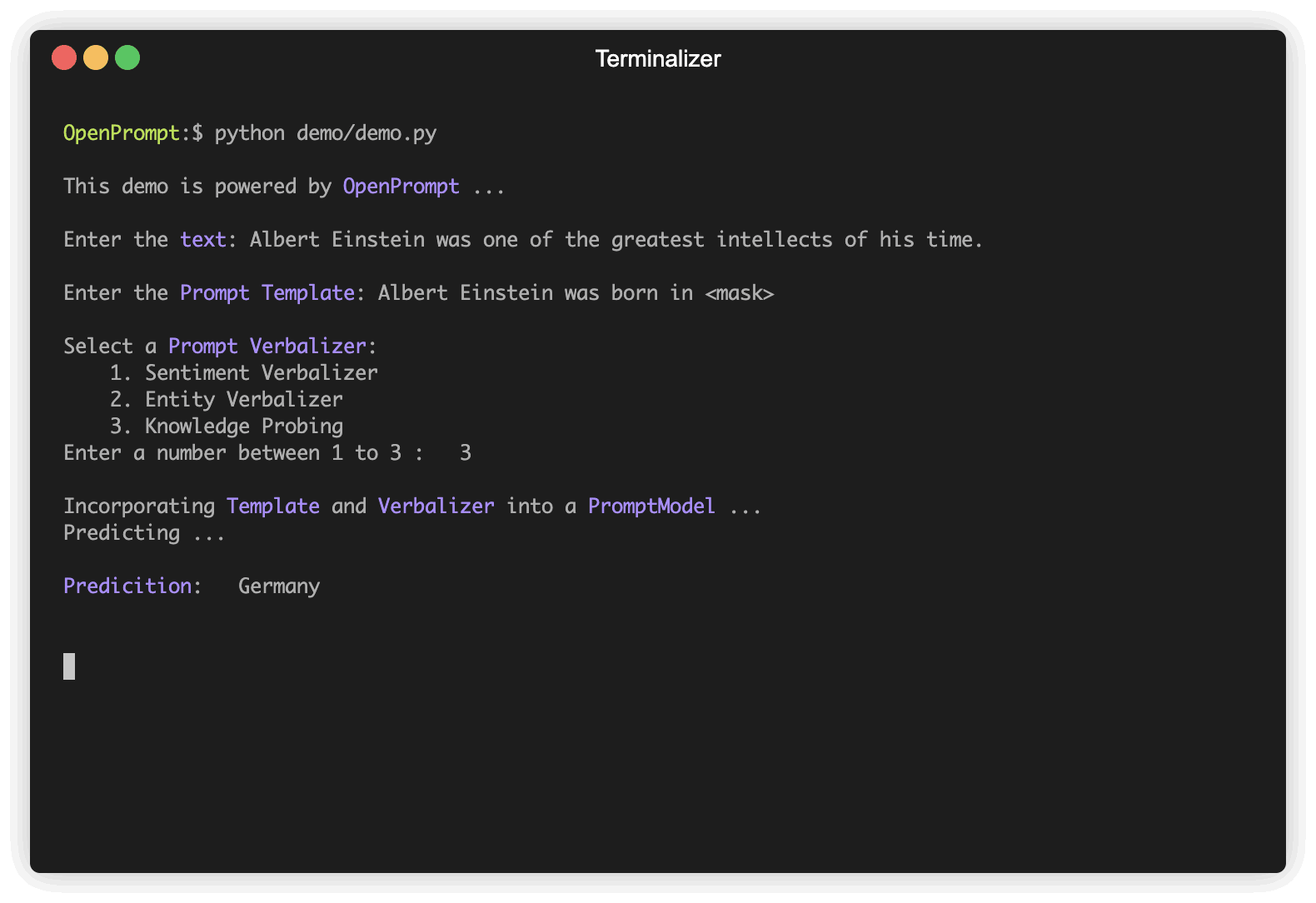
) يعتبر Verbalizer مهمًا آخر (ولكنه ليس ضروريًا) في التعلم المطبق ، والذي يعرض الملصقات الأصلية (لقد حددناها classes ، تذكر؟) لمجموعة من كلمات التسمية. فيما يلي مثال على أن نعرض الطبقة negative على كلمة سيئة ، ونقوم بإعداد الطبقة positive للكلمات الجيدة والرائعة والرائعة.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) بالنظر إلى المهمة ، لدينا الآن PLM ، Template Verbalizer ، نحن نجمعها في PromptModel . لاحظ أنه على الرغم من أن المثال يجمع بسذاجة الوحدات الثلاث ، يمكنك في الواقع تحديد بعض التفاعلات المعقدة فيما بينها.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) يعد PromptDataLoader إصدارًا سريعًا من Pytorch Dataloader ، والذي يتضمن أيضًا Tokenizer Template و TokenizerWrapper .
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)منتهي! يمكننا إجراء التدريب والاستدلال مثل العمليات الأخرى في Pytorch.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'يرجى الرجوع إلى البرامج النصية التعليمية الخاصة بنا ، والوثائق لمزيد من التفاصيل.
نحن نقدم سلسلة من البرامج النصية للتنزيل في dataset/ المجلد ، لا تتردد في استخدامها لتنزيل المعايير.
هناك الكثير من المجموعات الممكنة التي تعمل بها OpenPrompt. نحن نبذل قصارى جهدنا لاختبار أداء الأساليب المختلفة في أقرب وقت ممكن. سيتم تحديث الأداء باستمرار في الجداول. نشجع المستخدمين أيضًا على العثور على أفضل المعلمات المفرطة لمهامهم الخاصة والإبلاغ عن النتائج عن طريق تقديم طلب السحب.
تحسين/تعزيز كبير في المستقبل.
يرجى الاستشهاد بالورقة إذا كنت تستخدم OpenPrompt في عملك
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}نشكر جميع المساهمين في هذا المشروع ، ويرحب المزيد من المساهمين!


