OpenPrompt
v1.0.0
프롬프트 학습을위한 오픈 소스 프레임 워크.
개요 • 설치 • 사용 방법 • 문서 • 종이 • 인용 • 성능 •
./tutorial/9_UltraChat.py 참조하십시오.pip install openprompt프롬프트 학습은 사전 훈련 된 언어 모델 (PLM)을 다운 스트림 NLP 작업에 적응시키는 최신 패러다임으로, 텍스트 템플릿이있는 입력 텍스트를 수정하고 PLM을 직접 사용하여 사전 훈련 된 작업을 수행합니다. 이 라이브러리는 프롬프트 학습 파이프 라인을 배포하기위한 표준적이고 유연하며 확장 가능한 프레임 워크를 제공합니다. OpenPrompt는 Huggingface Transformers에서 직접 PLM을 로딩하는 것을 지원합니다. 앞으로는 다른 라이브러리에서 구현 한 PLM도 지원할 것입니다. 신속한 학습에 대한 더 많은 리소스는 종이 목록을 확인하십시오.
참고 : OpenPrompt에는 Python 3.8+를 사용하십시오
당사의 리포는 Python 3.8+ 및 Pytorch 1.8.1+ 에서 테스트되며 다음과 같이 PIP를 사용하여 OpenPrompt를 설치합니다.
pip install openprompt최신 기능을 사용하려면 소스에서 OpenPrompt를 설치할 수도 있습니다.
Github에서 저장소를 복제하십시오.
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py install코드를 수정하십시오
python setup.py develop
PromptModel 객체에는 PLM , A (또는 다중) Template 및 (또는 다중) Verbalizer 포함되어 있으며, 여기서 Template 클래스는 원래 입력을 템플릿으로 랩핑하도록 정의되며, Verbalizer 클래스는 현재 어휘의 레이블과 대상 단어 사이의 투영을 구성하는 것입니다. PromptModel 객체는 실제로 훈련 및 추론에 참여합니다.
OpenPrompt의 모듈성 및 유연성으로 프롬프트 학습 파이프 라인을 쉽게 개발할 수 있습니다.
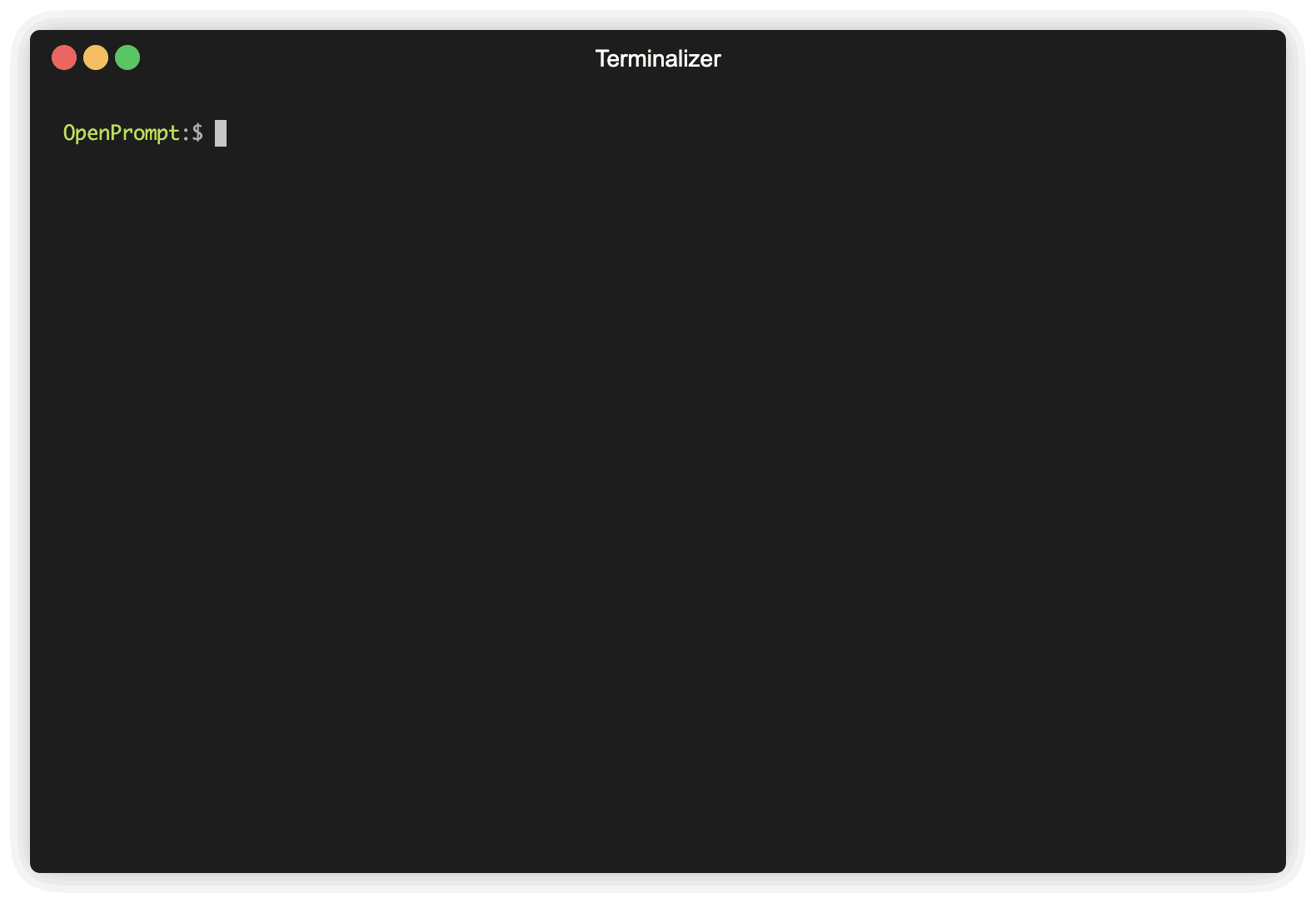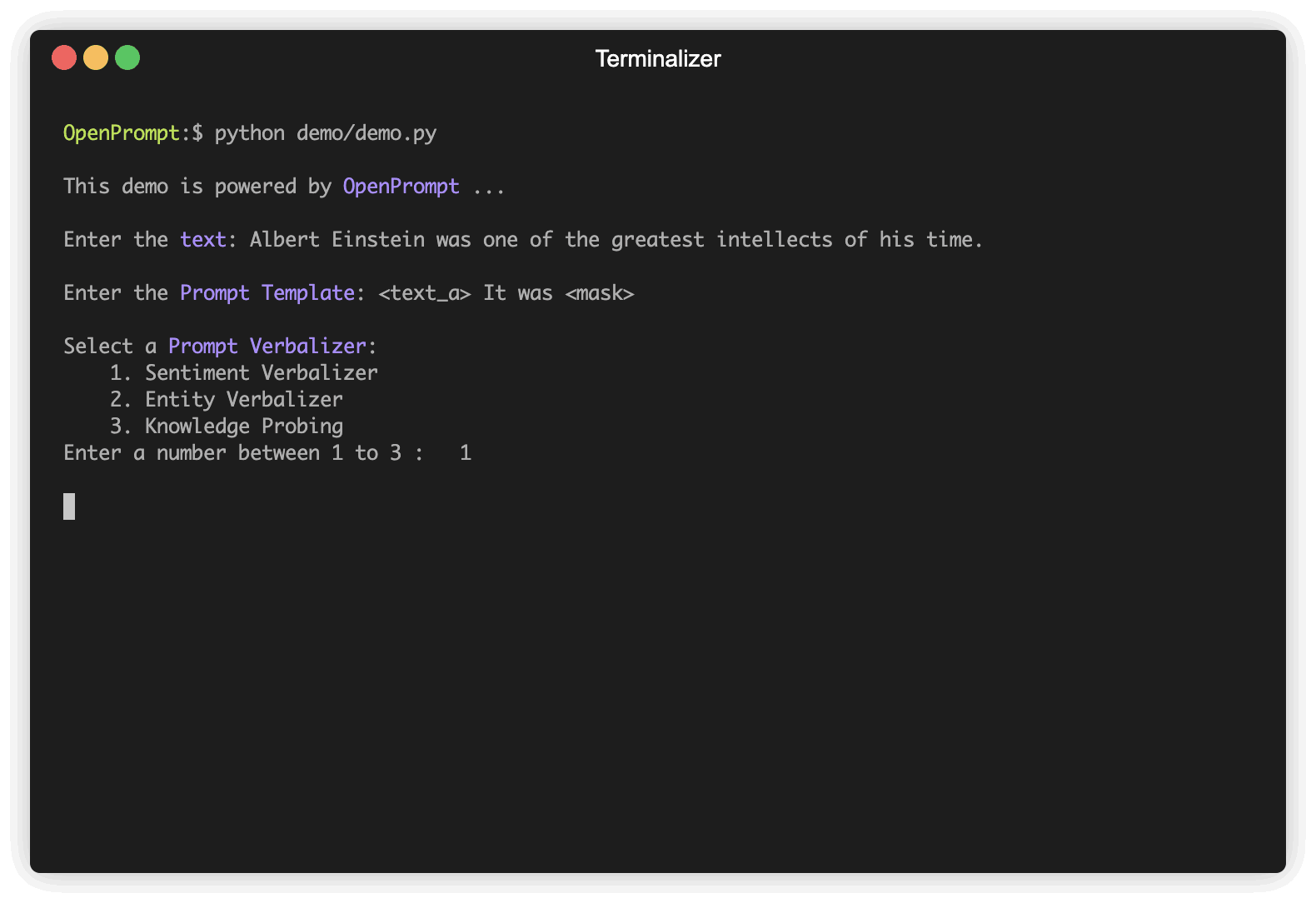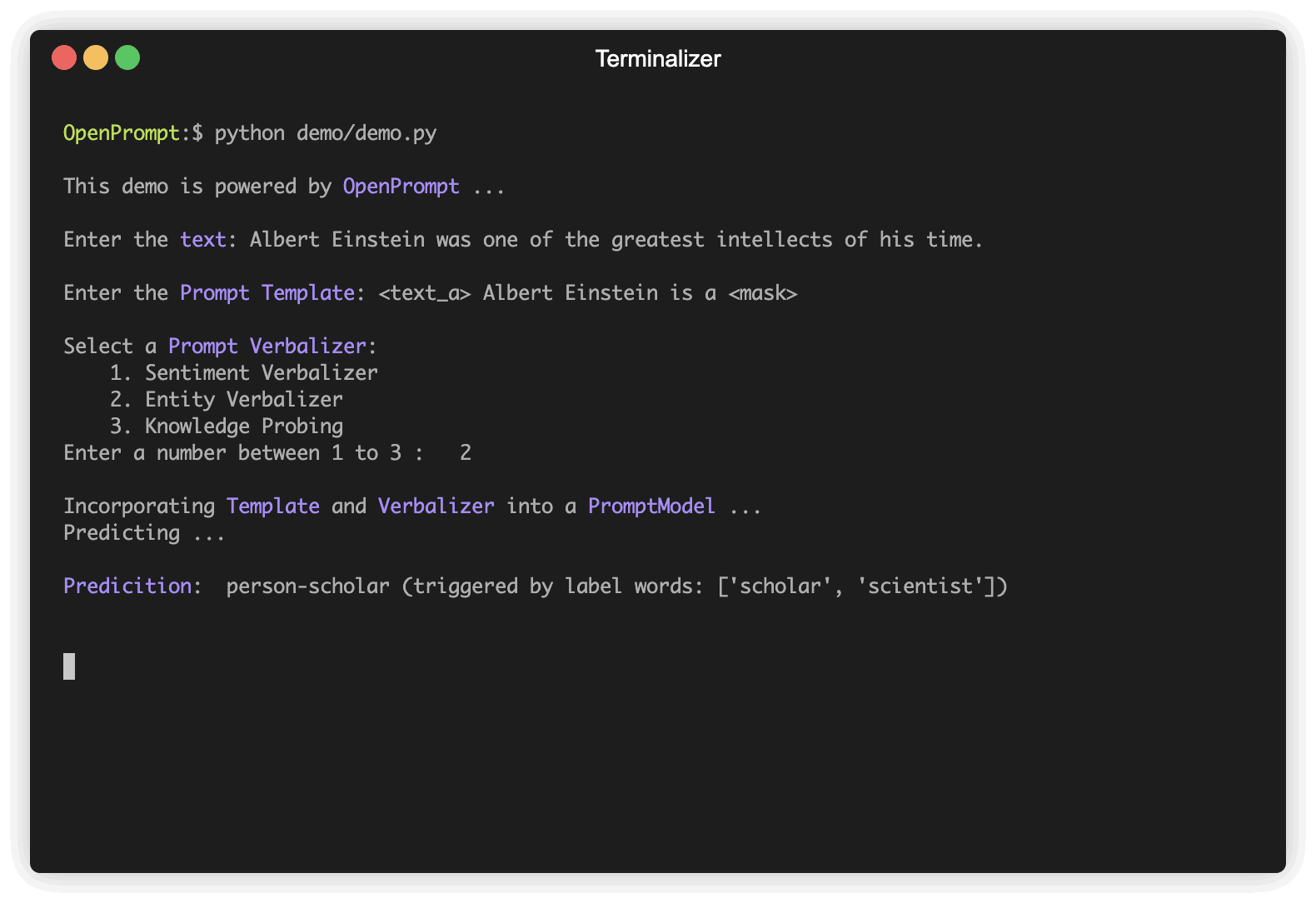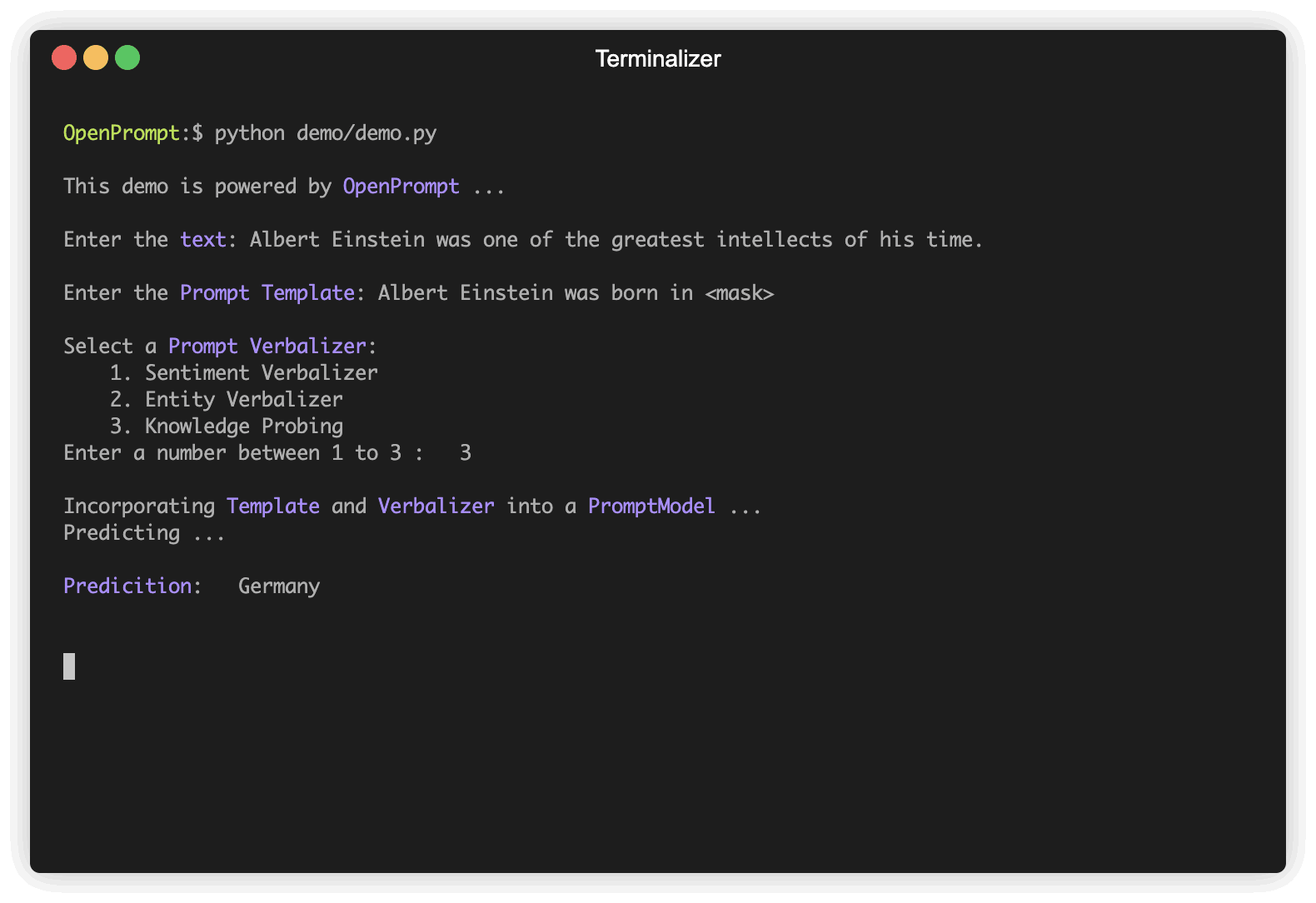
첫 번째 단계는 현재 NLP 작업을 결정하고 데이터가 어떻게 보이는지, 데이터에서 무엇을 원하는지 생각하는 것입니다! 즉,이 단계의 본질은 작업의 classes 와 InputExample 결정하는 것입니다. 단순화를 위해 감정 분석을 예로 사용합니다. Tutorial_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]작업을 지원하려면 PLM을 선택하십시오. 다른 모델마다 속성이 다르므로 OpenPrompt를 사용하여 다양한 PLM의 잠재력을 탐색하는 것이 좋습니다. OpenPrompt는 HuggingFace의 모델과 호환됩니다.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Template 원래 입력 텍스트의 수정 자이며, 이는 신속한 학습에서 가장 중요한 모듈 중 하나입니다. 1 단계에서 text_a 정의했습니다.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Verbalizer 프롬프트 학습에서 또 다른 중요한 (필요하지 않은)이며,이 레이블을 라벨 단어 세트에 원래 레이블 ( classes 로 정의)을 투사합니다. 다음은 우리가 negative 클래스를 나쁜 단어에 투사하고 positive 클래스를 선하고 훌륭하고 위대한 단어로 투영한다는 예입니다.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) 작업이 주어지면 이제 PLM , Template 및 Verbalizer 제가있어 PromptModel 로 결합합니다. 이 예제는 세 가지 모듈을 순진하게 결합하지만 실제로는 그 중 복잡한 상호 작용을 정의 할 수 있습니다.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) PromptDataLoader 는 기본적으로 Pytorch Dataloader의 프롬프트 버전으로 Tokenizer , Template 및 TokenizerWrapper 도 포함됩니다.
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)완료! 우리는 Pytorch의 다른 프로세스와 동일하게 훈련 및 추론을 수행 할 수 있습니다.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'자세한 내용은 튜토리얼 스크립트와 문서를 참조하십시오.
우리는 dataset/ 폴더에 일련의 다운로드 스크립트를 제공하고 벤치 마크를 다운로드하는 데 자유롭게 사용하십시오.
OpenPrompt로 구동되는 조합이 너무 많습니다. 우리는 가능한 빨리 다른 방법의 성능을 테스트하기 위해 최선을 다하고 있습니다. 성능은 끊임없이 테이블로 업데이트됩니다. 또한 사용자는 자신의 작업에 가장 적합한 하이퍼 파라미터를 찾아 풀 요청을 통해 결과를보고하도록 권장합니다.
미래의 주요 개선/향상.
작업에서 OpenPrompt를 사용하면 신문을 인용하십시오.
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}우리는이 프로젝트에 대한 모든 기여자들에게 감사의 말씀을 전합니다. 더 많은 기고자들을 환영합니다!


