OpenPrompt
v1.0.0
Uma estrutura de código aberto para aprendizado rápido.
Visão geral • Instalação • Como usar • Documentos • Papel • Citação • Desempenho •
./tutorial/9_UltraChat.py .pip install openpromptO prompt-learning é o mais recente paradigma a adaptar os modelos de idiomas pré-treinados (PLMs) às tarefas a jusante do PNL, que modifica o texto de entrada com um modelo textual e usa diretamente PLMs para realizar tarefas pré-treinadas. Esta biblioteca fornece uma estrutura padrão, flexível e extensível para implantar o pipeline de aprendizado rápido. O OpenPrompt suporta o carregamento de PLMs diretamente dos Transformers do Huggingface. No futuro, também apoiaremos PLMs implementados por outras bibliotecas. Para obter mais recursos sobre o aprendizado rápido, consulte nossa lista de papel.
NOTA: Por favor, use o Python 3.8+ para o OpenPrompt
Nosso repositório é testado no Python 3.8+ e Pytorch 1.8.1+ , instale o OpenPrompt usando o PIP da seguinte forma:
pip install openpromptPara jogar com os recursos mais recentes, você também pode instalar o OpenPrompt a partir da fonte.
Clone o repositório do GitHub:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installModificar o código
python setup.py develop
Um objeto PromptModel contém um Template PLM , um (ou múltiplo) e um (ou múltiplo) Verbalizer , onde a classe Template é definida para envolver a entrada original com os modelos, e a classe Verbalizer é construir uma projeção entre rótulos e palavras -alvo no vocabulário atual. E um objeto PromptModel participa praticamente de treinamento e inferência.
Com a modularidade e a flexibilidade do OpenPrompt, você pode facilmente desenvolver um pipeline de aprendizado rápido.
A primeira etapa é determinar a tarefa atual da PNL, pense na aparência dos seus dados e como você deseja dos dados! Ou seja, a essência desta etapa é determinar as classes e o InputExample da tarefa. Por simplicidade, usamos a análise de sentimentos como exemplo. tutorial_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
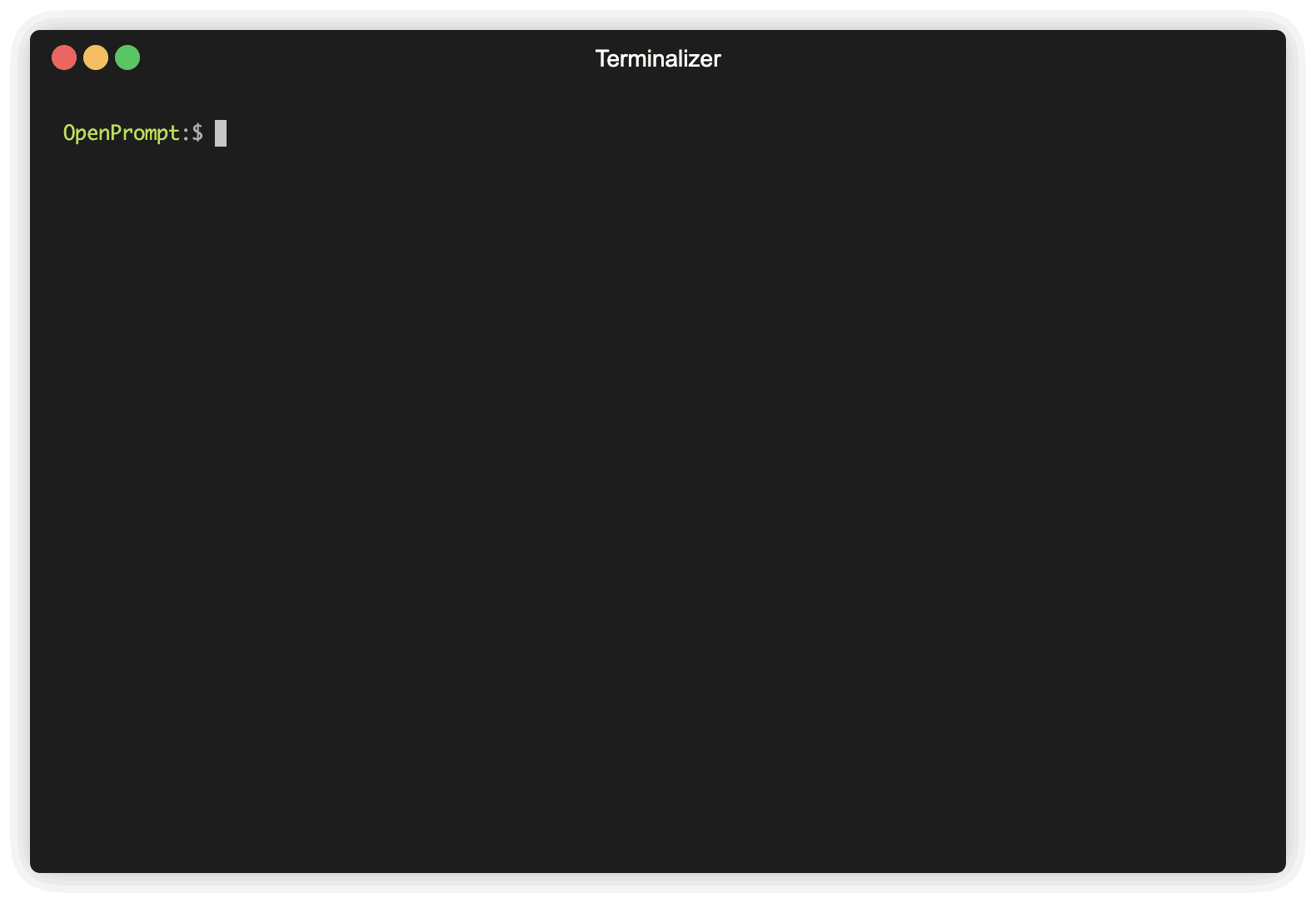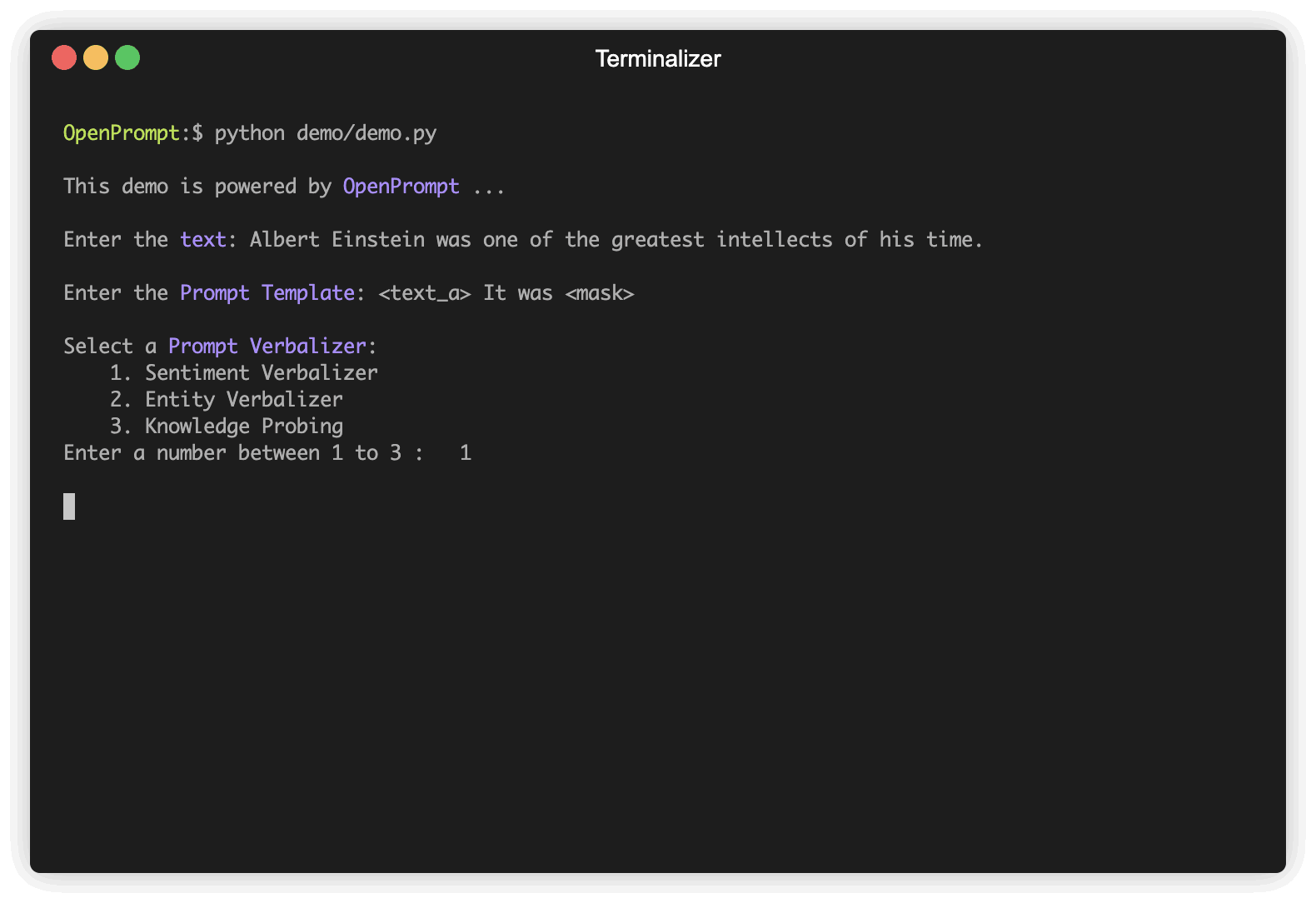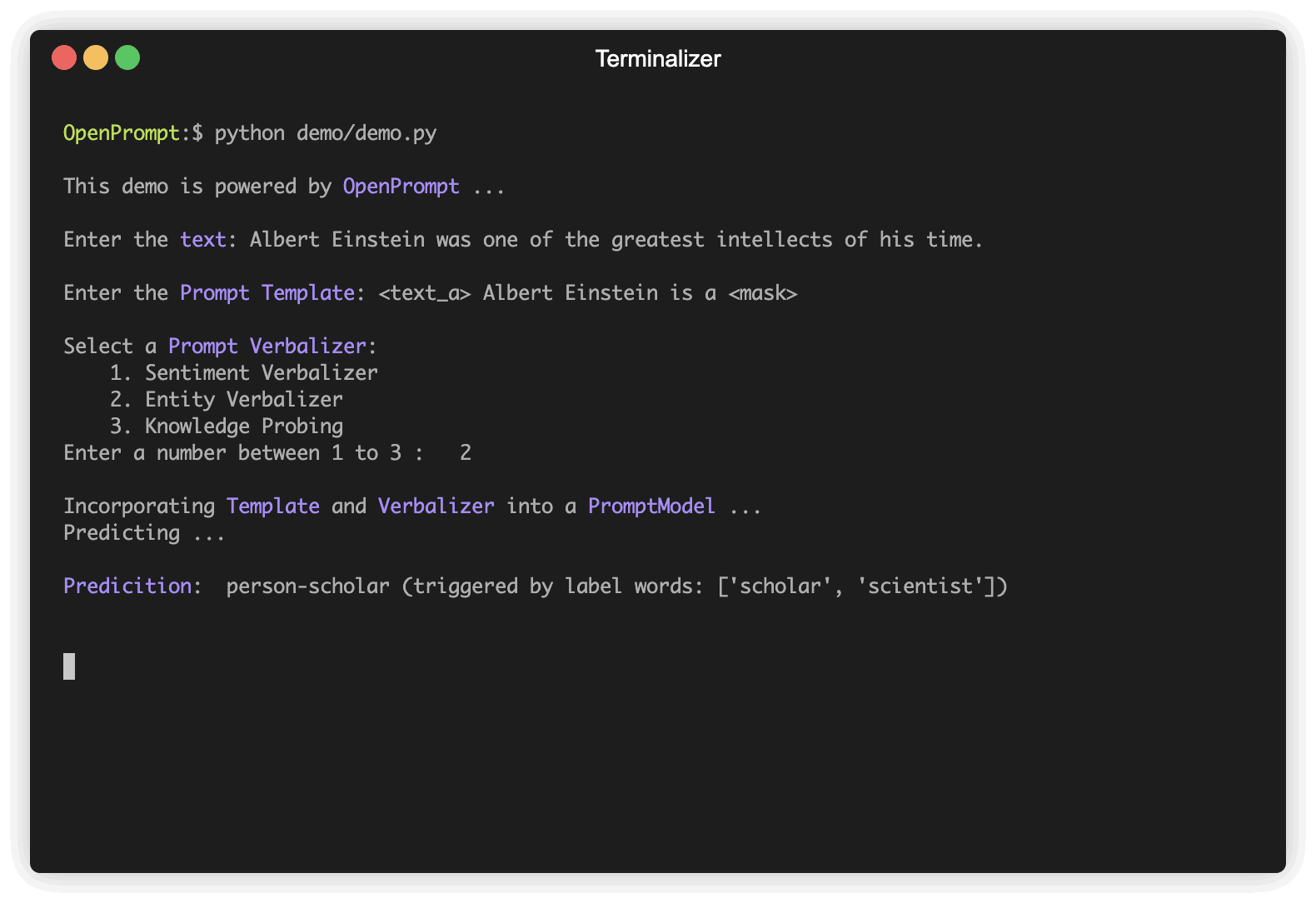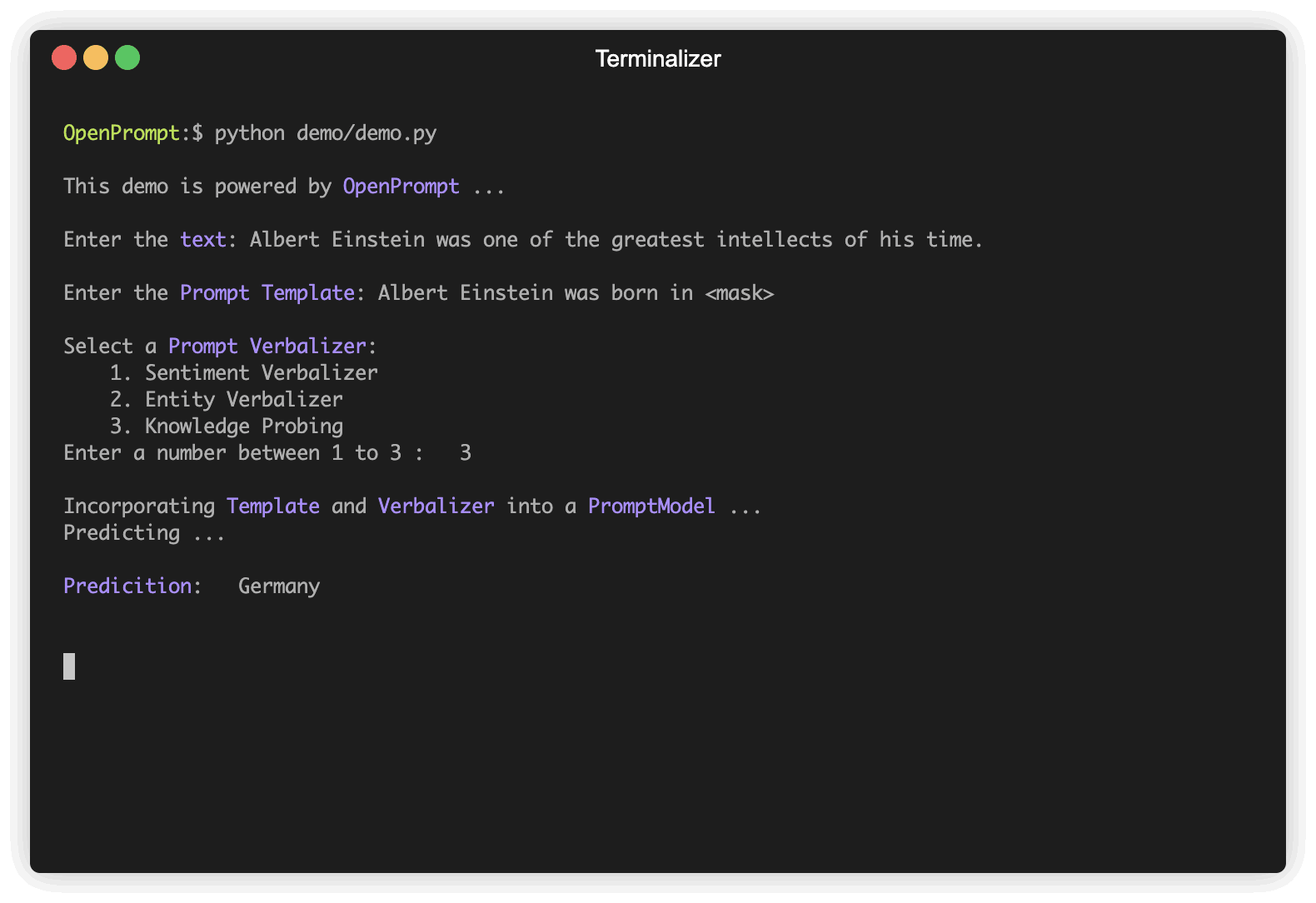
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]Escolha um PLM para apoiar sua tarefa. Modelos diferentes têm atributos diferentes, incentivamos você a usar o OpenPrompt para explorar o potencial de vários PLMs. O OpenPrompt é compatível com os modelos no HuggingFace.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Um Template é um modificador do texto de entrada original, que também é um dos módulos mais importantes no aprendizado rápido. Nós definimos text_a na etapa 1.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Um Verbalizer é outro importante (mas não necessário) no aprendizado rápido, que projeta os rótulos originais (nós os definimos como classes , lembra?) Para um conjunto de palavras de etiqueta. Aqui está um exemplo de que projetamos a classe negative para a palavra ruim e projetamos a classe positive para as palavras boas, maravilhosas, ótimas.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) Dada a tarefa, agora temos um PLM , um Template e um Verbalizer , combinamos -os em um PromptModel . Observe que, embora o exemplo combine ingenuamente os três módulos, você pode definir algumas interações complicadas entre eles.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) Um PromptDataLoader é basicamente uma versão rápida do Pytorch Dataloader, que também inclui um Tokenizer , um Template e um TokenizerWrapper .
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)Feito! Podemos realizar treinamento e inferência o mesmo que outros processos em Pytorch.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'Consulte nossos scripts do tutorial e documentação para obter mais detalhes.
Fornecemos uma série de scripts de download no dataset/ pasta, sinta -se à vontade para usá -los para baixar os benchmarks.
Existem muitas combinações possíveis alimentadas pelo OpenPrompt. Estamos tentando o nosso melhor para testar o desempenho de diferentes métodos o mais rápido possível. O desempenho será atualizado constantemente para as tabelas. Também incentivamos os usuários a encontrar os melhores hiper-parâmetros para suas próprias tarefas e relatar os resultados fazendo a solicitação de tração.
Grande melhoria/aprimoramento no futuro.
Cite nosso artigo se você usar o OpenPrompt em seu trabalho
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}Agradecemos a todos os colaboradores deste projeto, mais colaboradores são bem -vindos!


