OpenPrompt
v1.0.0
Рамка с открытым исходным кодом для быстрого обучения.
Обзор • Установка • Как использовать • Документы • Бумага • Цитирование • Производительность •
./tutorial/9_UltraChat.py .pip install openpromptОбратное обучение -это последняя парадигма для адаптации предварительно обученных языковых моделей (PLMS) к нижним задачам NLP, которая изменяет входной текст с помощью текстового шаблона и непосредственно использует PLM для выполнения предварительно обученных задач. Эта библиотека обеспечивает стандартную, гибкую и расширяемую структуру для развертывания трубопровода по быстрому обучению. OpenPrompt поддерживает загрузку PLM непосредственно от трансформаторов HuggingFace. В будущем мы также будем поддерживать PLMS, реализованные другими библиотеками. Для получения дополнительных ресурсов о быстрой обучении, пожалуйста, проверьте наш список бумаги.
Примечание. Пожалуйста, используйте Python 3.8+ для OpenPrompt
Наш репо протестирован на Python 3.8+ и Pytorch 1.8.1+ , установите OpenPrompt, используя PIP следующим образом:
pip install openpromptЧтобы играть с последними функциями, вы также можете установить OpenPrompt из источника.
Клонировать репозиторий от GitHub:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installИзменить код
python setup.py develop
Объект PromptModel содержит PLM , (или (или множественную) Template и (или множественный) Verbalizer , где класс Template определяется для обертывания исходного ввода шаблонами, а класс Verbalizer - это создание проекции между метками и целевыми словами в текущем словаре. И объект PromptModel практически участвует в обучении и выводе.
Благодаря модульности и гибкости OpenPrompt вы можете легко разработать процесс быстрого обучения.
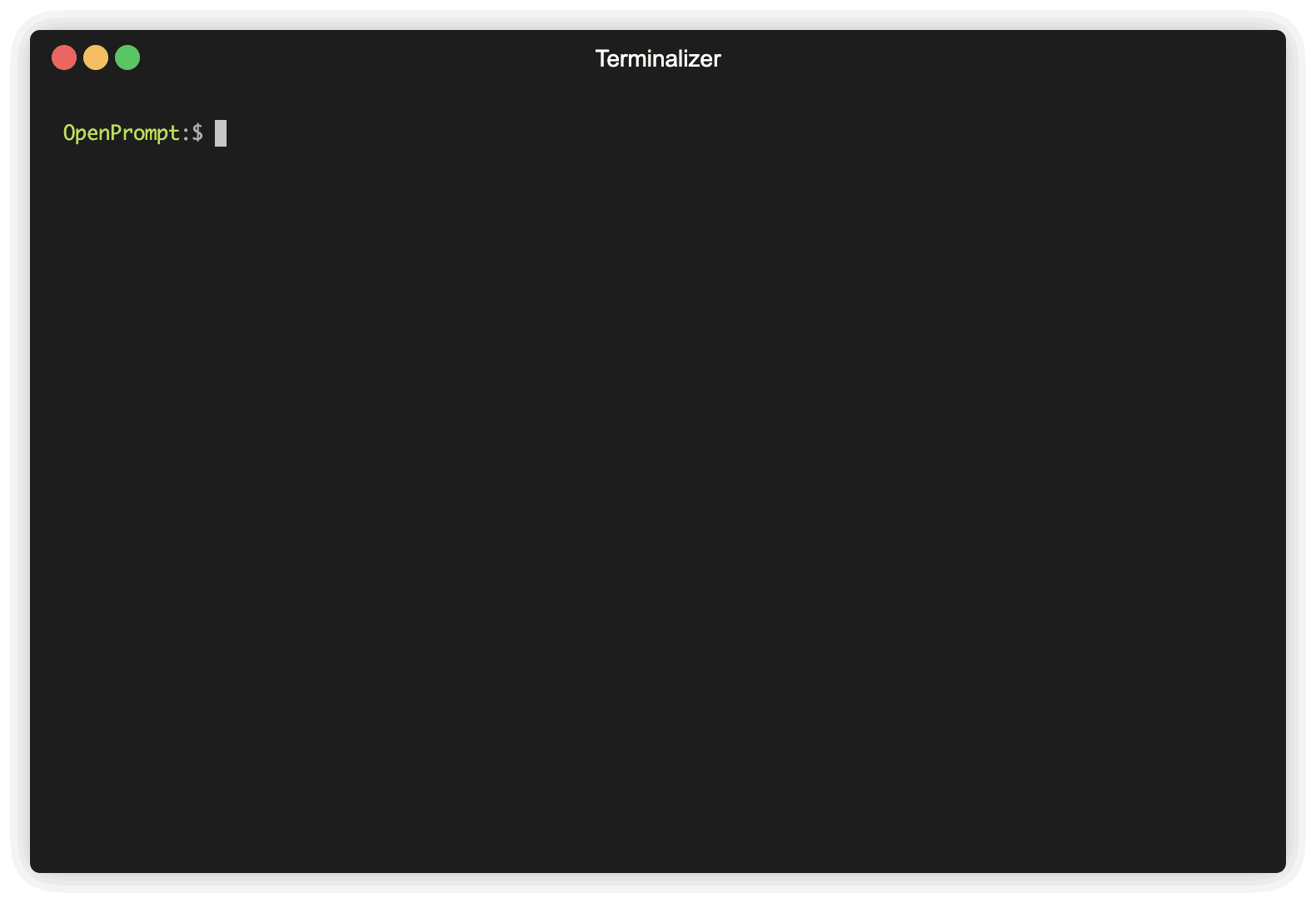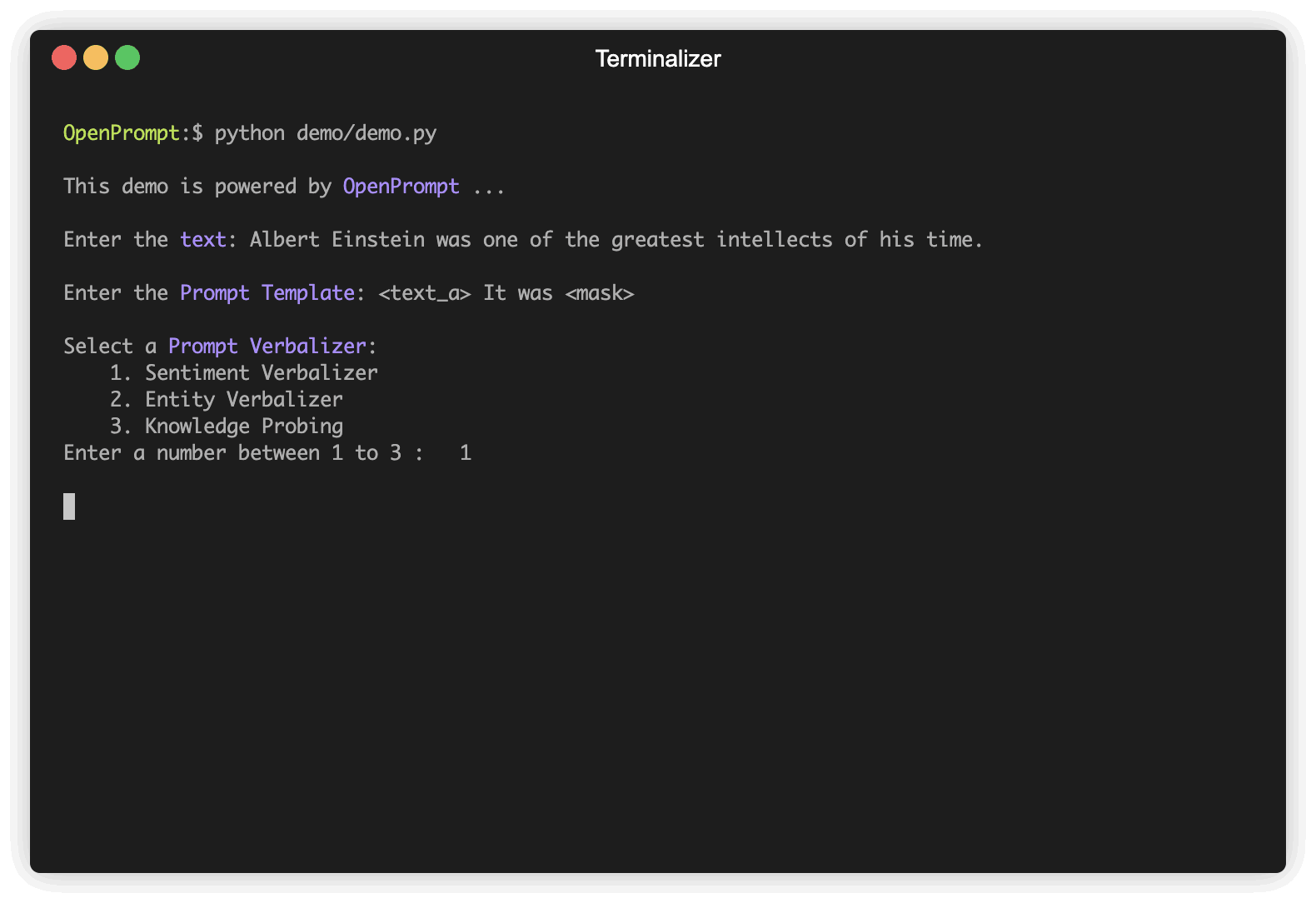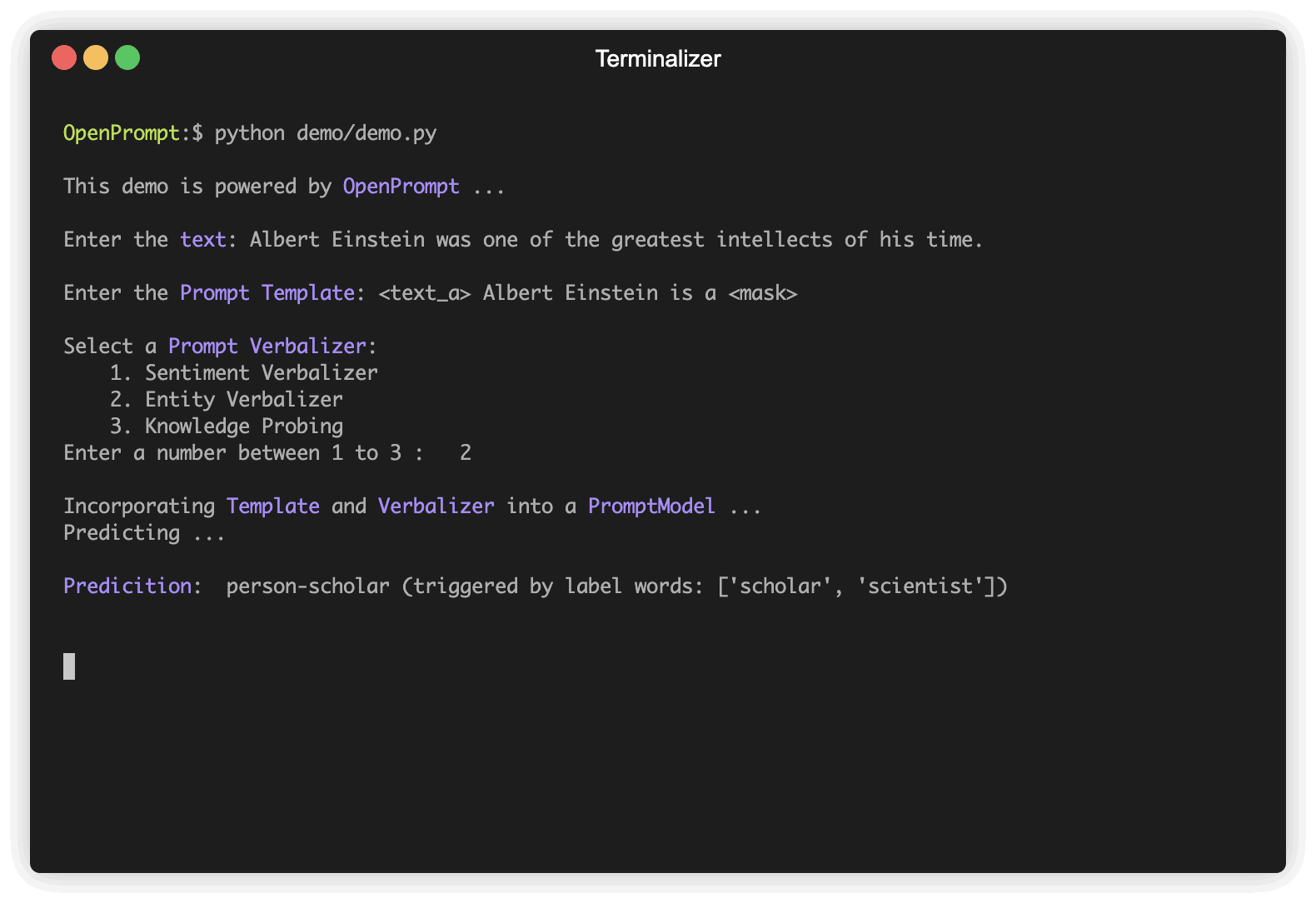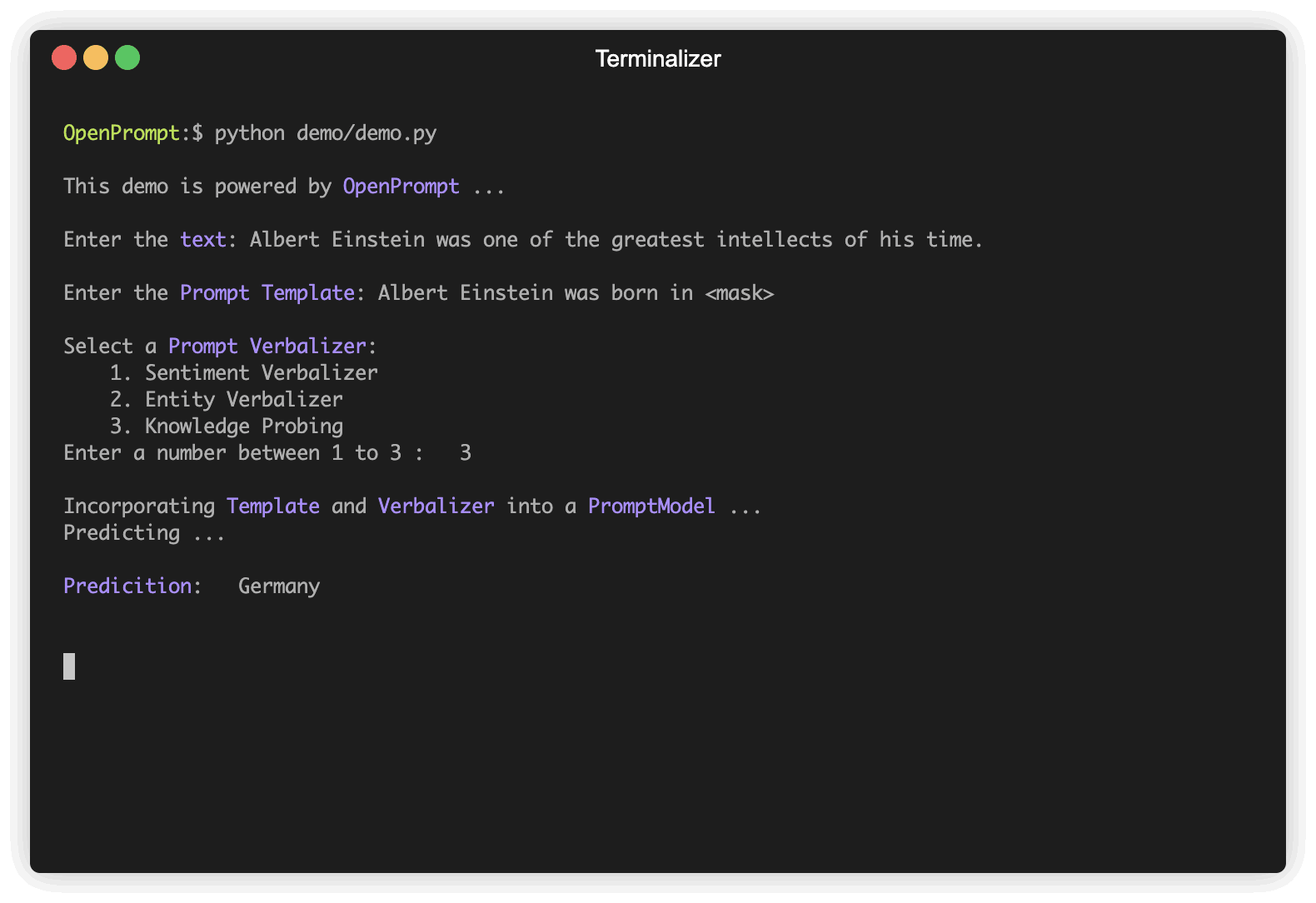
Первым шагом является определение текущей задачи NLP, подумайте о том, как выглядят ваши данные и что вы хотите от данных! То есть сущность этого шага состоит в том, чтобы определить classes и InputExample задачи. Для простоты мы используем анализ настроений в качестве примера. Tutorial_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]Выберите PLM, чтобы поддержать вашу задачу. Различные модели имеют разные атрибуты, мы поощряем вас использовать OpenPrompt для изучения потенциала различных PLMS. OpenPrompt совместим с моделями на HuggingFace.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Template -это модификатор исходного входного текста, который также является одним из наиболее важных модулей в быстрого обучении. Мы определили text_a на шаге 1.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Verbalizer является еще одним важным (но не необходимым) в быстром обучении, какое проектирует исходные этикетки (мы определили их как classes , помните?) На набор слов метки. Вот пример, который мы проецируем negative класс на слово «плохо» и продемонстрируем positive класс для слов хорошего, замечательного, великолепного.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) Учитывая задачу, теперь у нас есть PLM , Template и Verbalizer , мы комбинируем их в PromptModel . Обратите внимание, что, хотя пример наивно объединяет три модуля, вы можете фактически определить некоторые сложные взаимодействия между ними.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) PromptDataLoader - это в основном оперативная версия DataLoader Pytorch, которая также включает в себя Tokenizer , Template и TokenizerWrapper .
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)Сделанный! Мы можем проводить обучение и вывод, как и другие процессы в Pytorch.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'Пожалуйста, обратитесь к нашим учебным сценариям и документации для более подробной информации.
Мы предоставляем серию загрузочных сценариев в dataset/ папке, не стесняемся использовать их для загрузки тестов.
Существует слишком много возможных комбинаций, основанных на OpenPrompt. Мы стараемся как можно скорее проверить производительность различных методов. Производительность будет постоянно обновляться в таблицах. Мы также призываем пользователей найти лучшие гиперпараметры для своих собственных задач и сообщать о результатах, сделав запрос на вытяжение.
Основное улучшение/улучшение в будущем.
Пожалуйста, процитируйте нашу газету, если вы используете OpenPrompt в своей работе
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}Мы благодарим всех участников этого проекта, приветствуются больше участников!


