OpenPrompt
v1.0.0
Ein Open-Source-Framework für ein schnelles Lernen.
Übersicht • Installation • Verwenden • Dokumente • Papier • Zitat • Leistung •
./tutorial/9_UltraChat.py .pip install openpromptEingabeaufforderungs-Lernen ist das neueste Paradigma, um vorgebreitete Sprachmodelle (PLMS) an nachgeschaltete NLP-Aufgaben anzupassen, die den Eingabetxt mit einer Textvorlage verändert und PLMs direkt verwendet, um vorgebildete Aufgaben durchzuführen. Diese Bibliothek bietet ein Standard-, flexibler und erweiterbares Framework für die Bereitstellung der Eingabeaufforderung-Lernpipeline. OpenPrompt unterstützt das Laden von PLMs direkt von Umarmungs -Face -Transformatoren. In Zukunft werden wir auch PLMs unterstützen, die von anderen Bibliotheken implementiert wurden. Weitere Ressourcen zum schnellen Lernen finden Sie in unserer Papierliste.
Hinweis: Bitte verwenden Sie Python 3.8+ für OpenPrompt
Unser Repo wird auf Python 3.8+ und Pytorch 1.8.1+ getestet. Installieren Sie OpenPrompt wie folgt mit PIP:
pip install openpromptUm mit den neuesten Funktionen zu spielen, können Sie OpenPrompt auch aus der Quelle installieren.
Klonen Sie das Repository von Github:
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installÄndern Sie den Code
python setup.py develop
Ein PromptModel -Objekt enthält eine PLM , eine (oder mehrere) Template und einen (oder mehrere) Verbalizer , wobei die Template definiert ist, um die ursprüngliche Eingabe mit Vorlagen zu wickeln, und die Verbalizer besteht darin, eine Projektion zwischen Etiketten und Zielwörtern im aktuellen Vokabular zu erstellen. Und ein PromptModel -Objekt nimmt praktisch an Schulungen und Inferenz teil.
Mit der Modularität und Flexibilität von OpenPrompt können Sie problemlos eine Pipeline zur Eingabeaufforderung entwickeln.
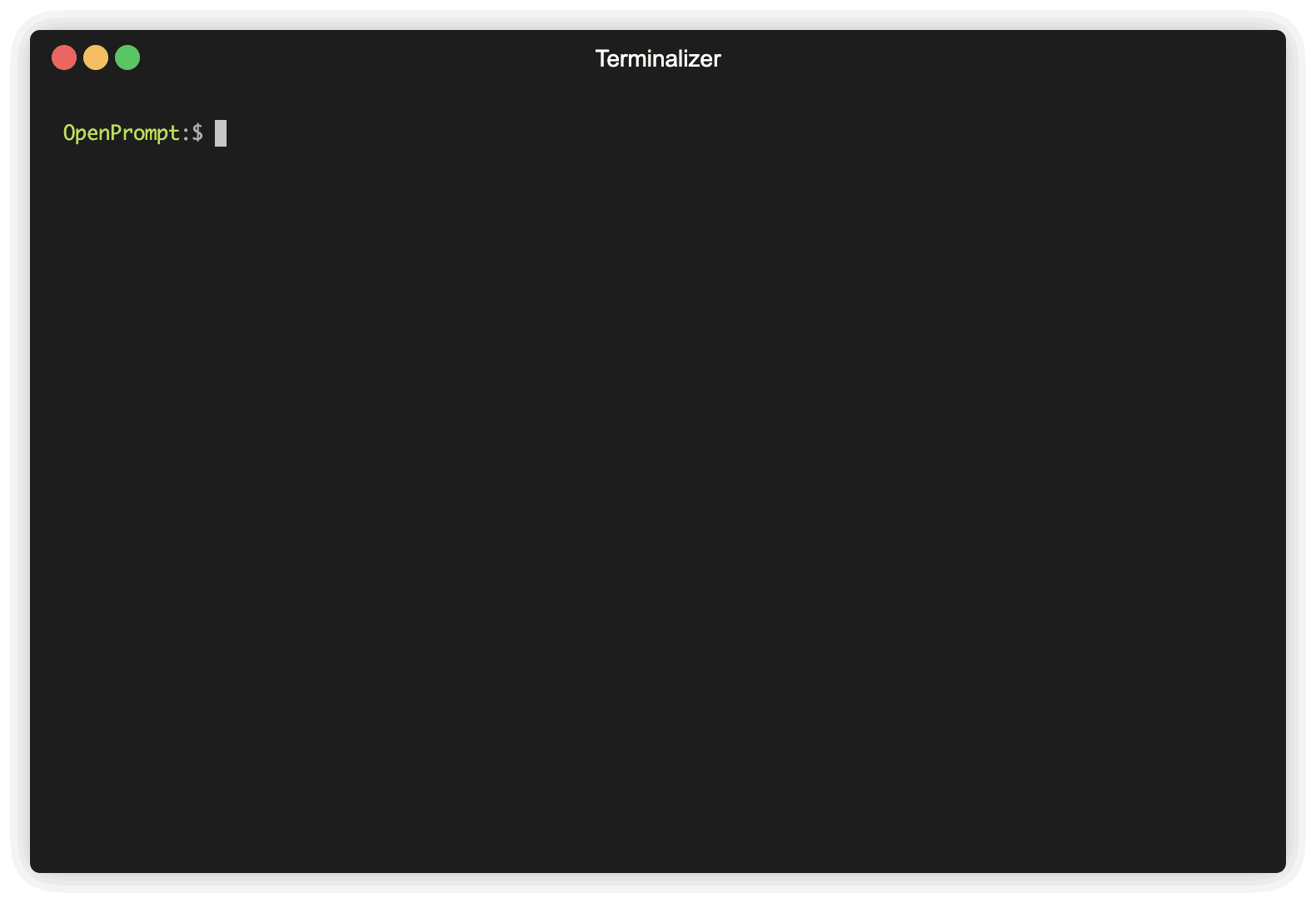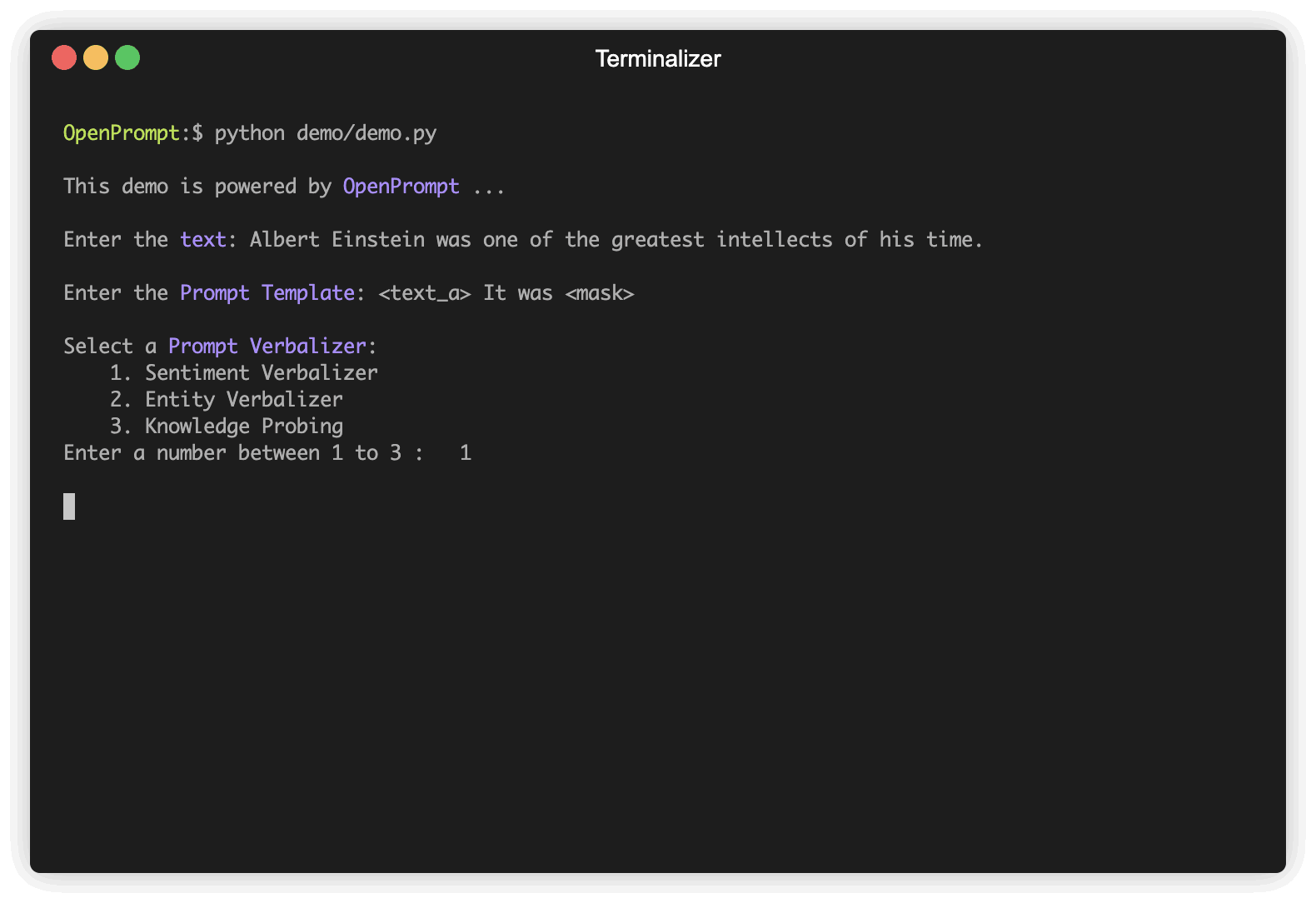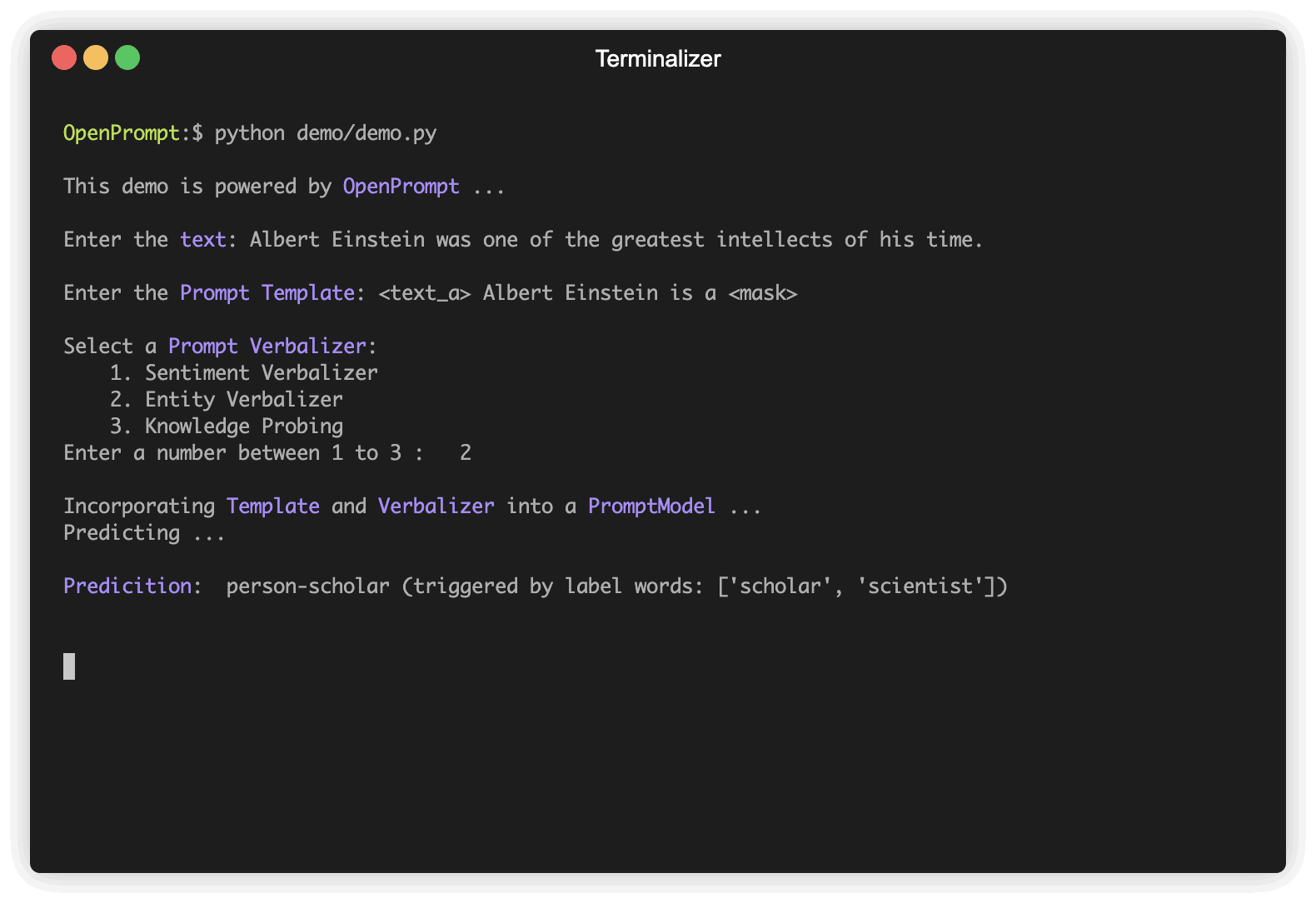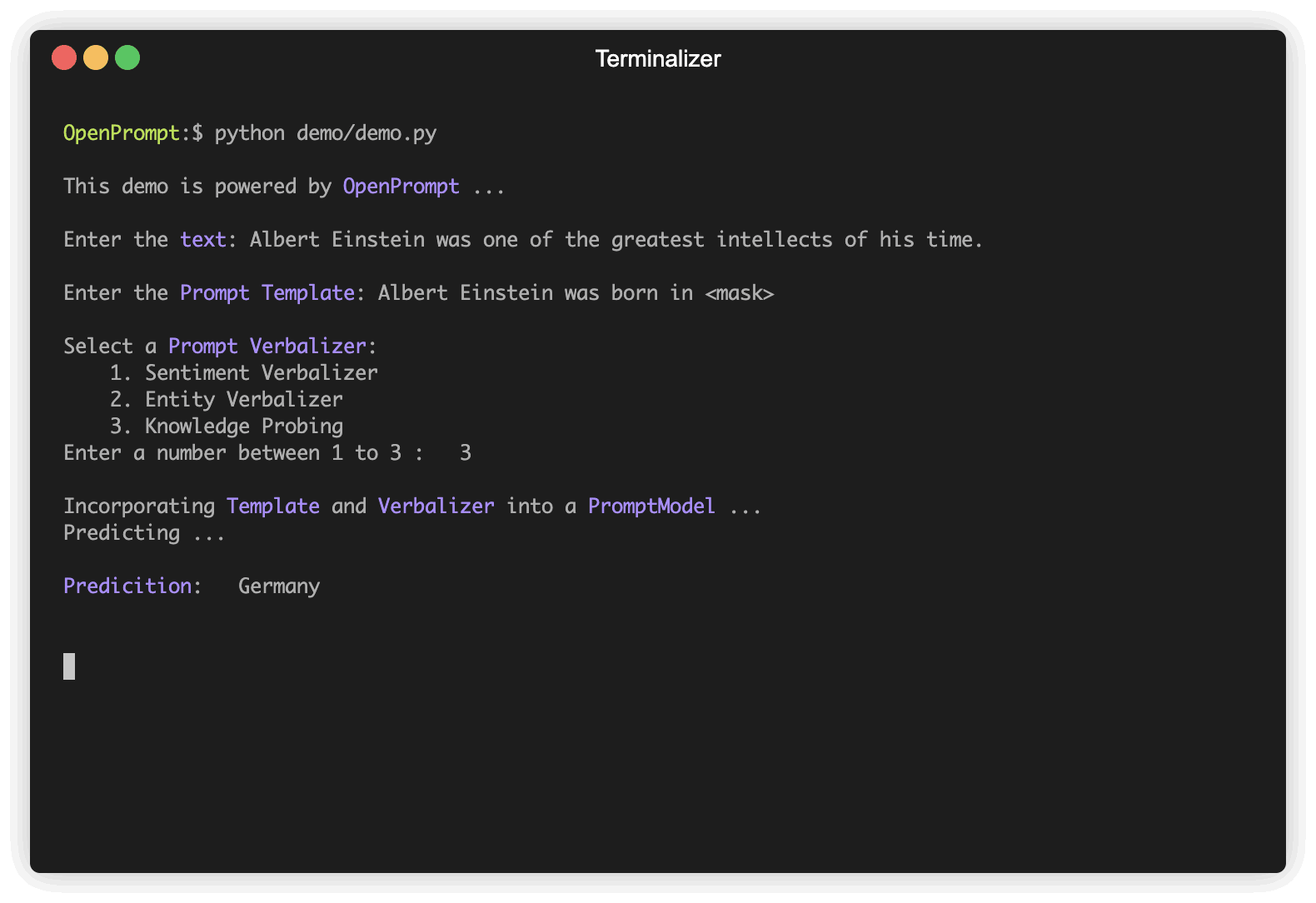
Der erste Schritt besteht darin, die aktuelle NLP -Aufgabe zu bestimmen und darüber nachzudenken, wie Ihre Daten aussehen und was Sie von den Daten wünschen! Das heißt, das Wesen dieses Schritts besteht darin, die classes und die InputExample der Aufgabe zu bestimmen. Der Einfachheit halber verwenden wir als Beispiel die Sentiment -Analyse. tutorial_task.
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]Wählen Sie eine PLM, um Ihre Aufgabe zu unterstützen. Verschiedene Modelle haben unterschiedliche Attribute. Wir haben Sie aufgefordert, OpenPrompt zu verwenden, um das Potenzial verschiedener PLMs zu untersuchen. OpenPrompt ist mit Modellen auf dem Umarmungsface kompatibel.
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Eine Template ist ein Modifikator des ursprünglichen Eingangstextes, der auch eines der wichtigsten Module beim Eingabeaufenthaltslernen ist. Wir haben text_a in Schritt 1 definiert.
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
) Ein Verbalizer ist ein weiterer wichtiger (aber nicht notwendiger) im prompt-larning, der die ursprünglichen Etiketten (wir haben sie als classes definiert, erinnern Sie sich?) Einen Label-Wörter. Hier ist ein Beispiel, dass wir die negative Klasse mit dem Wort schlecht projizieren und die positive Klasse zu den Worten, die gut, wunderbar, großartig projizieren.
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
) Angesichts der Aufgabe haben wir jetzt eine PLM , eine Template und einen Verbalizer , wir kombinieren sie zu einem PromptModel . Beachten Sie, dass Sie zwar die drei Module naiv kombinieren, aber einige komplizierte Wechselwirkungen zwischen ihnen definieren können.
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
) Ein PromptDataLoader ist im Grunde eine Eingabeaufforderung von Pytorch Dataloader, die auch einen Tokenizer , eine Template und einen TokenizerWrapper enthält.
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)Erledigt! Wir können Schulungen und Schlussfolgerung wie andere Prozesse in Pytorch durchführen.
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'Weitere Informationen finden Sie in unseren Tutorial -Skripten und Dokumentationen.
Wir bieten eine Reihe von Download -Skripten im dataset/ Ordner. Sie können sie gerne zum Herunterladen von Benchmarks verwenden.
Es gibt zu viele mögliche Kombinationen, die von OpenPrompt angetrieben werden. Wir versuchen unser Bestes, um die Leistung verschiedener Methoden so schnell wie möglich zu testen. Die Leistung wird ständig in die Tabellen aktualisiert. Wir ermutigen die Benutzer auch, die besten Hyper-Parameter für ihre eigenen Aufgaben zu finden und die Ergebnisse zu melden, indem sie Pull-Anfrage stellen.
Hauptverbesserung/Verbesserung in Zukunft.
Bitte zitieren Sie unser Papier, wenn Sie OpenPrompt in Ihrer Arbeit verwenden
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}Wir danken allen Mitwirkenden zu diesem Projekt, weitere Mitwirkende sind willkommen!


