OpenPrompt
v1.0.0
プロンプトラーニングのオープンソースフレームワーク。
概要•インストール•使用方法•ドキュメント•紙•引用•パフォーマンス•パフォーマンス•
./tutorial/9_UltraChat.pyを参照してください。pip install openpromptプロンプトラーニングは、事前に訓練された言語モデル(PLM)をダウンストリームNLPタスクに適応させる最新のパラダイムであり、入力テキストをテキストテンプレートで変更し、PLMSを直接使用して事前に訓練されたタスクを実行します。このライブラリは、プロンプト学習パイプラインを展開するための標準的で柔軟で拡張可能なフレームワークを提供します。 OpenPromptは、Huggingface TransformersからPLMを直接ロードすることをサポートします。将来的には、他のライブラリによって実装されたPLMSもサポートします。迅速な学習に関するリソースについては、ペーパーリストを確認してください。
注:OpenPromptにはPython 3.8+を使用してください
私たちのレポは、Python 3.8+およびPytorch 1.8.1+でテストされ、次のようにPIPを使用してOpenPromptをインストールします。
pip install openprompt最新の機能を使用するために、ソースからOpenPromptをインストールすることもできます。
Githubからリポジトリをクローンします。
git clone https://github.com/thunlp/OpenPrompt.git
cd OpenPrompt
pip install -r requirements.txt
python setup.py installコードを変更します
python setup.py develop
PromptModelオブジェクトには、 PLM 、A(または複数の) Template 、および(または複数の) Verbalizer含まれています。 Templateクラスは、元の入力をテンプレートでラップするように定義され、 Verbalizerクラスは、現在の語彙のラベルとターゲット単語間の投影を構築することです。そして、 PromptModelオブジェクトは、実際にトレーニングと推論に参加します。
OpenPromptのモジュール性と柔軟性により、プロンプト学習パイプラインを簡単に開発できます。
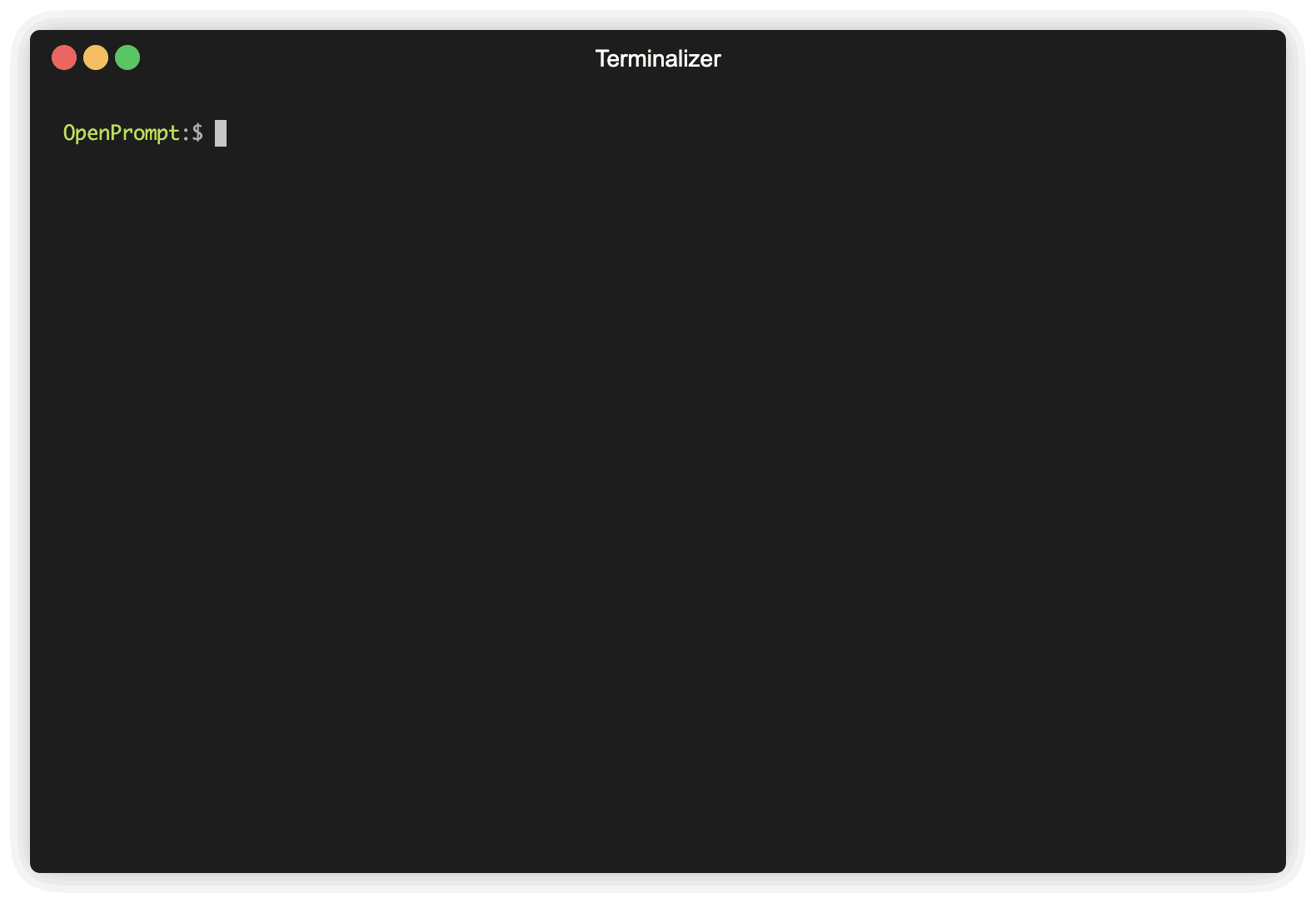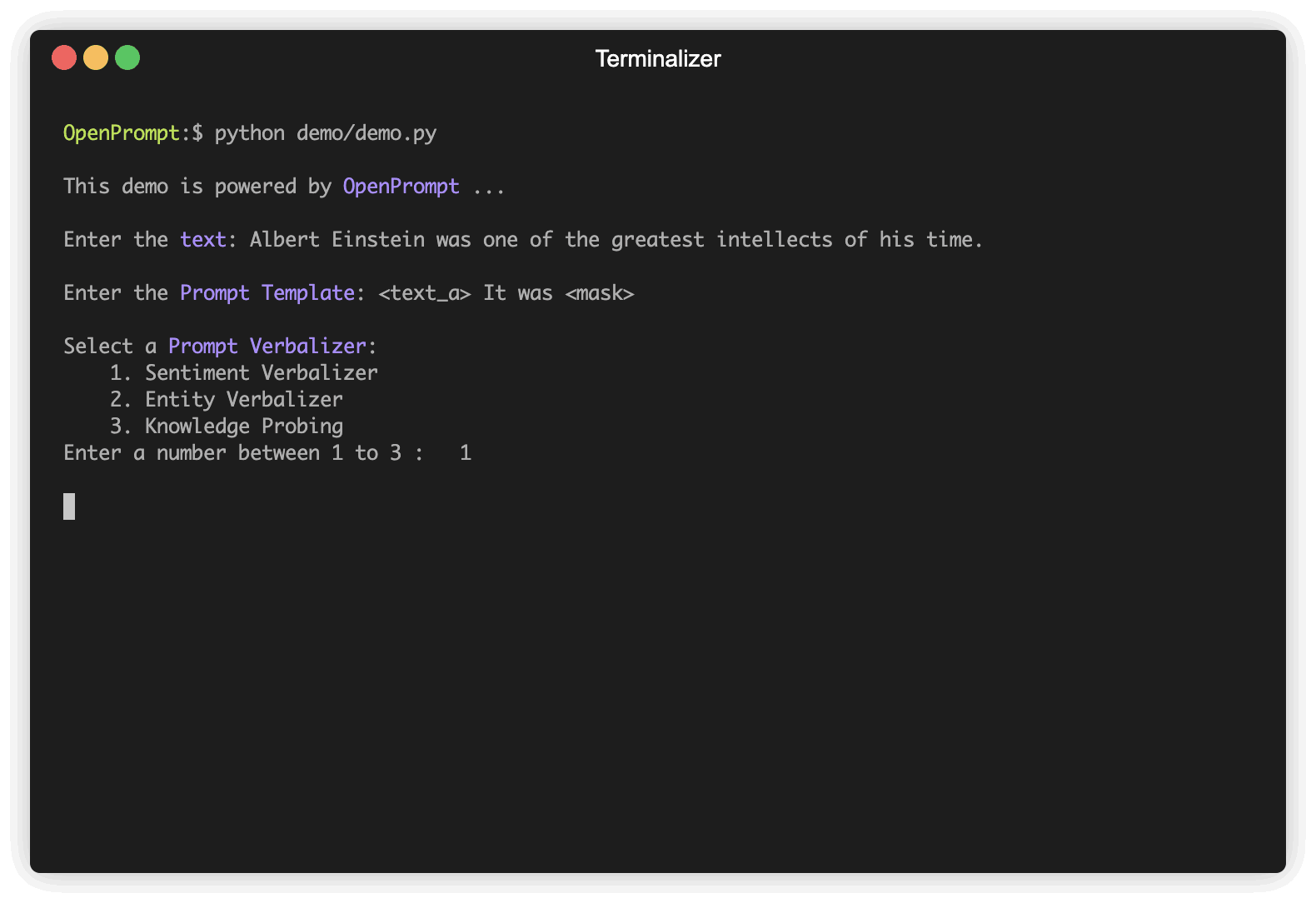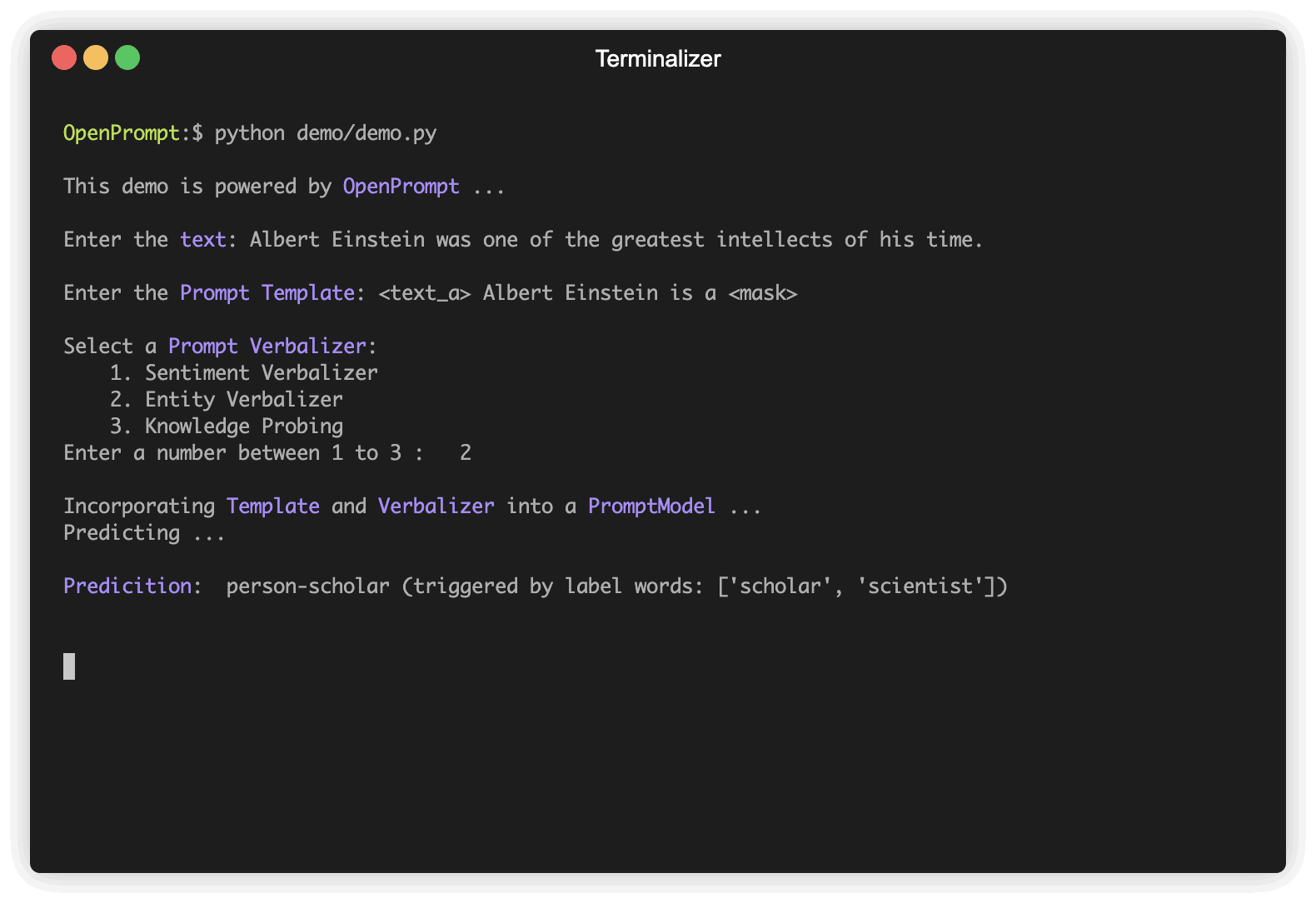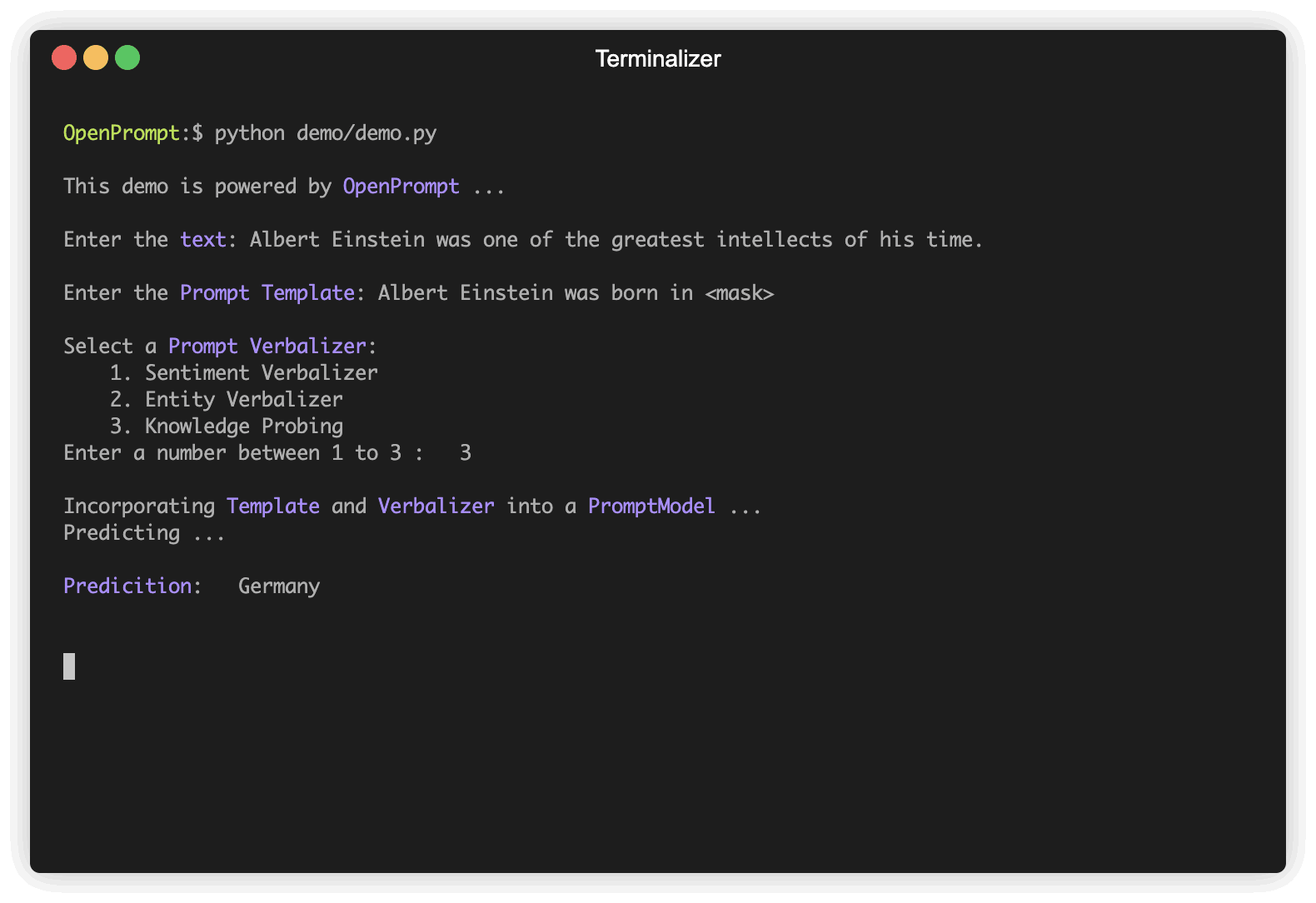
最初のステップは、現在のNLPタスクを決定し、データがどのように見えるか、データに何が欲しいかを考えてください!つまり、このステップの本質は、タスクのclassesとInputExampleを決定することです。簡単にするために、センチメント分析を例として使用します。 tutorial_task。
from openprompt . data_utils import InputExample
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative" ,
"positive"
]
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample (
guid = 0 ,
text_a = "Albert Einstein was one of the greatest intellects of his time." ,
),
InputExample (
guid = 1 ,
text_a = "The film was badly made." ,
),
]タスクをサポートするPLMを選択してください。異なるモデルには異なる属性があります。OpenPLMPTを使用して、さまざまなPLMの可能性を調査することをお勧めします。 OpenPromptは、Huggingfaceのモデルと互換性があります。
from openprompt . plms import load_plm
plm , tokenizer , model_config , WrapperClass = load_plm ( "bert" , "bert-base-cased" ) Template 、元の入力テキストの修飾子であり、これはプロンプトラーニングで最も重要なモジュールの1つでもあります。ステップ1でtext_aを定義しました。
from openprompt . prompts import ManualTemplate
promptTemplate = ManualTemplate (
text = '{"placeholder":"text_a"} It was {"mask"}' ,
tokenizer = tokenizer ,
)Verbalizer 、プロンプトラーニングのもう1つの重要な(必要ではない)ことであり、元のラベルをラベルclassesのセットに投影します(覚えていますか?)。 negativeクラスを悪い言葉に投影し、 positiveクラスを良い、素晴らしい、素晴らしい言葉に投影する例を以下に示します。
from openprompt . prompts import ManualVerbalizer
promptVerbalizer = ManualVerbalizer (
classes = classes ,
label_words = {
"negative" : [ "bad" ],
"positive" : [ "good" , "wonderful" , "great" ],
},
tokenizer = tokenizer ,
)タスクを考慮して、 PLM 、 Template 、およびVerbalizerがあります。それらをPromptModelに結合します。この例は3つのモジュールを単純に組み合わせて組み合わせていますが、実際にそれらの間の複雑な相互作用を定義できることに注意してください。
from openprompt import PromptForClassification
promptModel = PromptForClassification (
template = promptTemplate ,
plm = plm ,
verbalizer = promptVerbalizer ,
)PromptDataLoader 、基本的にはPytorch Dataloaderのプロンプトバージョンであり、 Tokenizer 、 Template 、 TokenizerWrapperライターも含まれます。
from openprompt import PromptDataLoader
data_loader = PromptDataLoader (
dataset = dataset ,
tokenizer = tokenizer ,
template = promptTemplate ,
tokenizer_wrapper_class = WrapperClass ,
)終わり! Pytorchの他のプロセスと同じように、トレーニングと推論を実施できます。
import torch
# making zero-shot inference using pretrained MLM with prompt
promptModel . eval ()
with torch . no_grad ():
for batch in data_loader :
logits = promptModel ( batch )
preds = torch . argmax ( logits , dim = - 1 )
print ( classes [ preds ])
# predictions would be 1, 0 for classes 'positive', 'negative'詳細については、チュートリアルスクリプトとドキュメントを参照してください。
dataset/フォルダーに一連のダウンロードスクリプトを提供しています。それらを使用してベンチマークをダウンロードしてください。
OpenPromptを搭載した可能な組み合わせが多すぎます。私たちは、できるだけ早くさまざまな方法のパフォーマンスをテストするために最善を尽くしています。パフォーマンスは常にテーブルに更新されます。また、ユーザーは自分のタスクに最適なハイパーパラメーターを見つけ、プルリクエストを行うことで結果を報告することをお勧めします。
将来の大きな改善/強化。
あなたの仕事でOpenPromptを使用している場合は、私たちの論文を引用してください
@article { ding2021openprompt ,
title = { OpenPrompt: An Open-source Framework for Prompt-learning } ,
author = { Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong } ,
journal = { arXiv preprint arXiv:2111.01998 } ,
year = { 2021 }
}このプロジェクトへのすべての貢献者に感謝します。もっと多くの貢献者を歓迎します!


