pytorch mixtures
1.0.0
Модуль подключаемой игры для смеси экспертов и смеси глубины в Pytorch. Ваше универсальное решение для вставки слоев MOE/MOD в пользовательские нейронные сети без усилий!
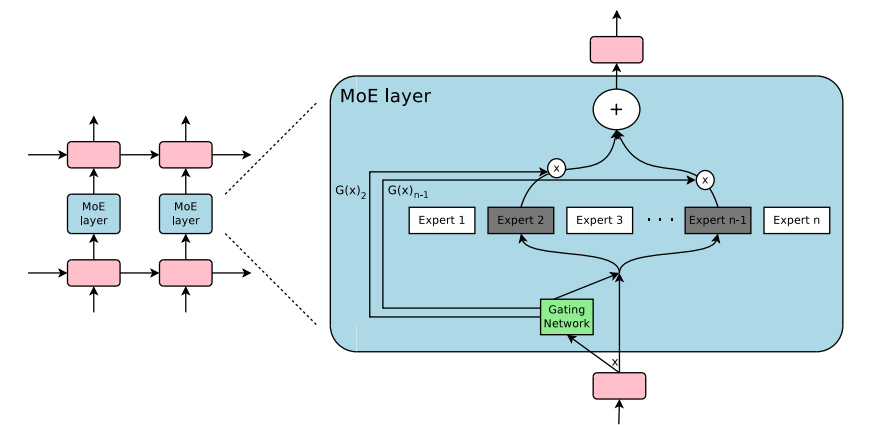 -
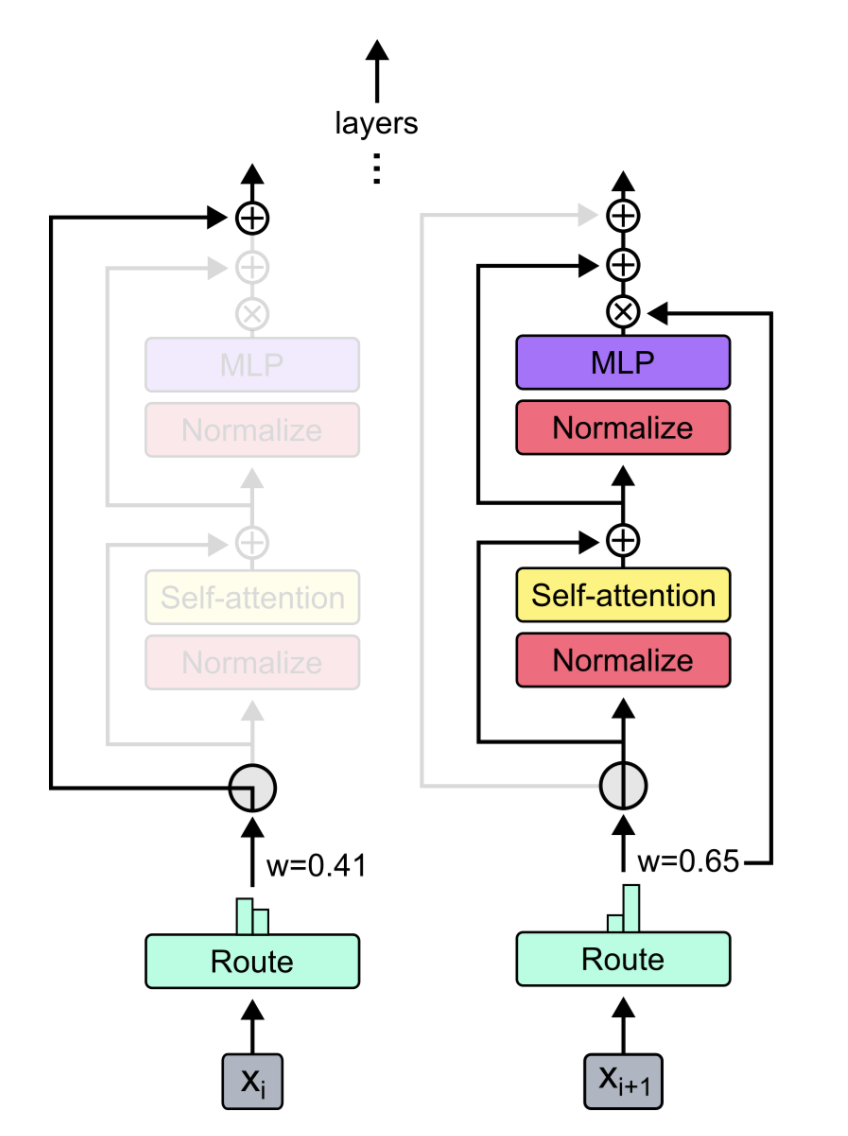
- 
Источники:
Просто использование pip3 install pytorch-mixtures установит этот пакет. Обратите внимание, что это требует, чтобы torch и einops были предварительно установлены в качестве зависимостей. Если вы хотите построить этот пакет из источника, запустите следующую команду:
git clone https://github.com/jaisidhsingh/pytorch-mixtures.git
cd pytorch-mixtures
pip3 install . pytorch-mixtures предназначен для легкой возможности интегрироваться в существующий код для любой нейронной сети по вашему выбору, например, например,
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe_layer import MoELayer
import torch
import torch . nn as nn
# define some config
BATCH_SIZE = 16
SEQ_LEN = 128
DIM = 768
NUM_EXPERTS = 8
CAPACITY_FACTOR = 1.25
# first initialize the router
router = ExpertChoiceRouter ( dim = DIM , num_experts = NUM_EXPERTS )
# choose the experts you want: pytorch-mixtures just needs a list of `nn.Module` experts
# for e.g. our experts are just linear layers
experts = [ nn . Linear ( DIM , DIM ) for _ in range ( NUM_EXPERTS )]
# supply the router and experts to the MoELayer for modularity
moe = MoELayer (
num_experts = NUM_EXPERTS ,
router = router ,
experts = experts ,
capacity_factor = CAPACITY_FACTOR
)
# initialize some test input
x = torch . randn ( BATCH_SIZE , SEQ_LEN , DIM )
# pass through moe
moe_output , aux_loss , router_z_loss = moe ( x ) # shape: [BATCH_SIZE, SEQ_LEN, DIM] Вы также можете легко использовать это в своих собственных классах nn.Module
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe import MoELayer
from pytorch_mixtures . utils import MHSA # multi-head self-attention layer provided for ease
import torch
import torch . nn as nn
class CustomMoEAttentionBlock ( nn . Module ):
def __init__ ( self , dim , num_heads , num_experts , capacity_factor , experts ):
super (). __init__ ()
self . attn = MHSA ( dim , num_heads )
router = ExpertChoiceRouter ( dim , num_experts )
self . moe = MoELayer ( dim , router , experts , capacity_factor )
self . norm1 = nn . LayerNorm ( dim )
self . norm2 = nn . LayerNorm ( dim )
def forward ( self , x ):
x = self . norm1 ( self . attn ( x ) + x )
moe_output , aux_loss , router_z_loss = self . moe ( x )
x = self . norm2 ( moe_output + x )
return x , aux_loss , router_z_loss
experts = [ nn . Linear ( 768 , 768 ) for _ in range ( 8 )]
my_block = CustomMoEAttentionBlock (
dim = 768 ,
num_heads = 8 ,
num_experts = 8 ,
capacity_factor = 1.25 ,
experts = experts
)
# some test input
x = torch . randn ( 16 , 128 , 768 )
output , aux_loss , router_z_loss = my_block ( x ) # output shape: [16, 128, 768] Этот пакет предоставляет пользователю запустить простой, но надежный absl test для кода MOE. Если все эксперты инициализированы в качестве одного и того же модуля, выход MoELayer должен быть равен входному тензору, проходящему через любого эксперта. Как ExpertChoiceRouter , так и TopkRouter проверяются таким образом и преуспевают в тестах. Пользователи могут запустить эти тесты для себя, выполнив следующее:
from pytorch_mixtures import run_tests
run_tests ()Примечание. Все тесты проходят правильно. Если тест не удается, это, вероятно, связано с краевым случаем в случайных инициализациях. Попробуйте еще раз, и это пройдет.
Если вы нашли этот пакет полезным, пожалуйста, укажите его в своей работе:
@misc { JaisidhSingh2024 ,
author = { Singh, Jaisidh } ,
title = { pytorch-mixtures } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/jaisidhsingh/pytorch-mixtures} } ,
}Этот пакет был построен с помощью кода с открытым исходным кодом, упомянутого ниже:


