pytorch mixtures
1.0.0
Un module de plug-and-play pour le mélange d'Experts et le mélange de dépassement dans Pytorch. Votre solution à guichet unique pour insérer des couches MOE / MOD dans des réseaux de neurones personnalisés sans effort!
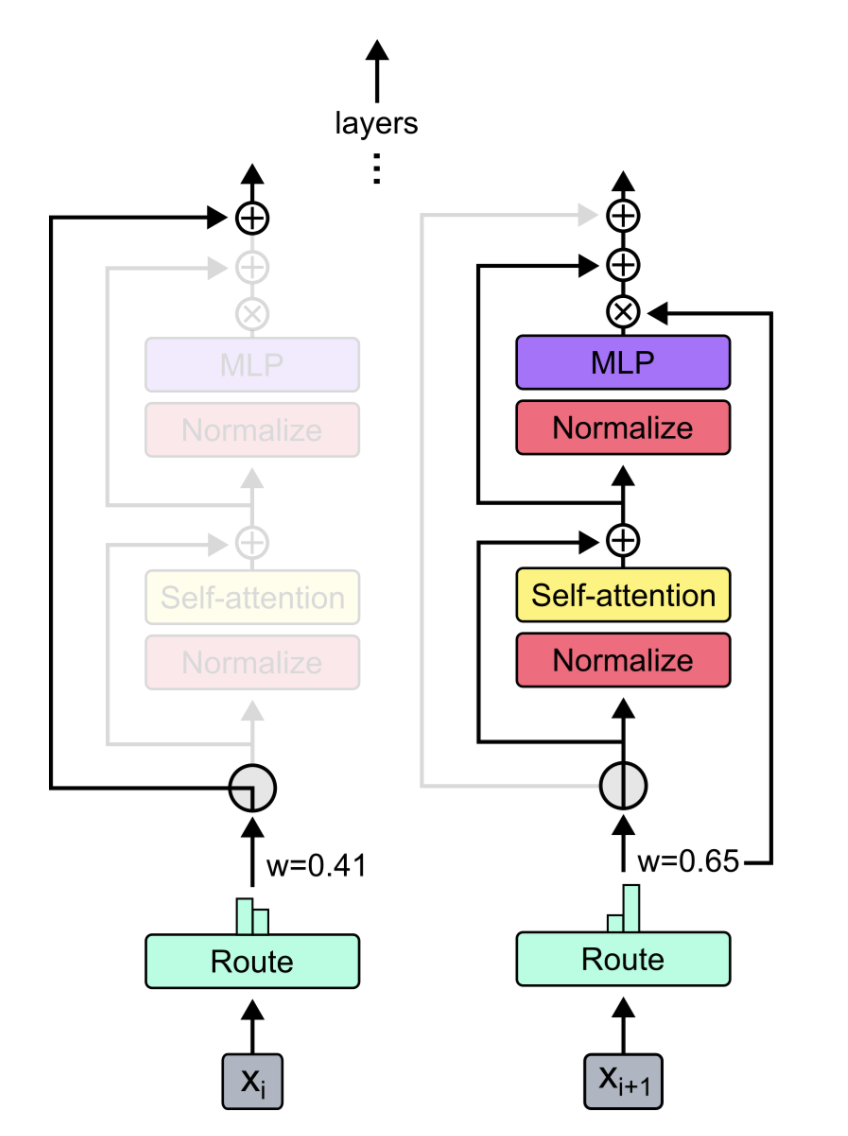
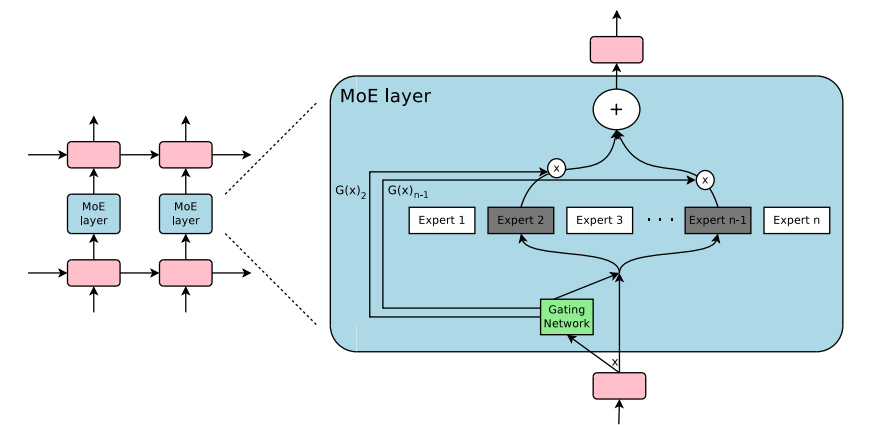 -
- 
Sources:
En utilisant simplement pip3 install pytorch-mixtures installer ce package. Notez que cela nécessite que torch et einops soient préinstallés sous forme de dépendances. Si vous souhaitez créer ce package à partir de Source, exécutez la commande suivante:
git clone https://github.com/jaisidhsingh/pytorch-mixtures.git
cd pytorch-mixtures
pip3 install . pytorch-mixtures est conçu pour s'intégrer sans effort dans votre code existant pour tout réseau de neurones de votre choix, par exemple
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe_layer import MoELayer
import torch
import torch . nn as nn
# define some config
BATCH_SIZE = 16
SEQ_LEN = 128
DIM = 768
NUM_EXPERTS = 8
CAPACITY_FACTOR = 1.25
# first initialize the router
router = ExpertChoiceRouter ( dim = DIM , num_experts = NUM_EXPERTS )
# choose the experts you want: pytorch-mixtures just needs a list of `nn.Module` experts
# for e.g. our experts are just linear layers
experts = [ nn . Linear ( DIM , DIM ) for _ in range ( NUM_EXPERTS )]
# supply the router and experts to the MoELayer for modularity
moe = MoELayer (
num_experts = NUM_EXPERTS ,
router = router ,
experts = experts ,
capacity_factor = CAPACITY_FACTOR
)
# initialize some test input
x = torch . randn ( BATCH_SIZE , SEQ_LEN , DIM )
# pass through moe
moe_output , aux_loss , router_z_loss = moe ( x ) # shape: [BATCH_SIZE, SEQ_LEN, DIM] Vous pouvez également l'utiliser facilement dans vos propres classes nn.Module
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe import MoELayer
from pytorch_mixtures . utils import MHSA # multi-head self-attention layer provided for ease
import torch
import torch . nn as nn
class CustomMoEAttentionBlock ( nn . Module ):
def __init__ ( self , dim , num_heads , num_experts , capacity_factor , experts ):
super (). __init__ ()
self . attn = MHSA ( dim , num_heads )
router = ExpertChoiceRouter ( dim , num_experts )
self . moe = MoELayer ( dim , router , experts , capacity_factor )
self . norm1 = nn . LayerNorm ( dim )
self . norm2 = nn . LayerNorm ( dim )
def forward ( self , x ):
x = self . norm1 ( self . attn ( x ) + x )
moe_output , aux_loss , router_z_loss = self . moe ( x )
x = self . norm2 ( moe_output + x )
return x , aux_loss , router_z_loss
experts = [ nn . Linear ( 768 , 768 ) for _ in range ( 8 )]
my_block = CustomMoEAttentionBlock (
dim = 768 ,
num_heads = 8 ,
num_experts = 8 ,
capacity_factor = 1.25 ,
experts = experts
)
# some test input
x = torch . randn ( 16 , 128 , 768 )
output , aux_loss , router_z_loss = my_block ( x ) # output shape: [16, 128, 768] Ce package fournit à l'utilisateur pour exécuter un absl test simple mais fiable pour le code MOE. Si tous les experts sont initialisés comme le même module, la sortie du MoELayer doit être égale au tenseur d'entrée transmis par tout expert. ExpertChoiceRouter et TopkRouter sont testés ainsi et réussissent dans les tests. Les utilisateurs peuvent exécuter ces tests en exécutant ce qui suit:
from pytorch_mixtures import run_tests
run_tests ()Remarque: Tous les tests passent correctement. Si un test échoue, cela est probablement dû à un cas de bord dans les initialisations aléatoires. Essayez à nouveau et il passera.
Si vous avez trouvé ce package utile, veuillez le citer dans votre travail:
@misc { JaisidhSingh2024 ,
author = { Singh, Jaisidh } ,
title = { pytorch-mixtures } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/jaisidhsingh/pytorch-mixtures} } ,
}Ce package a été construit à l'aide du code open-source mentionné ci-dessous:


