pytorch mixtures
1.0.0
Ein Plug-and-Play-Modul für Expertenmischungen und Depths in Pytorch. Ihre One-Stop-Lösung zum Einfügen von MOE/MOD-Ebenen in benutzerdefinierte neuronale Netze mühelos!
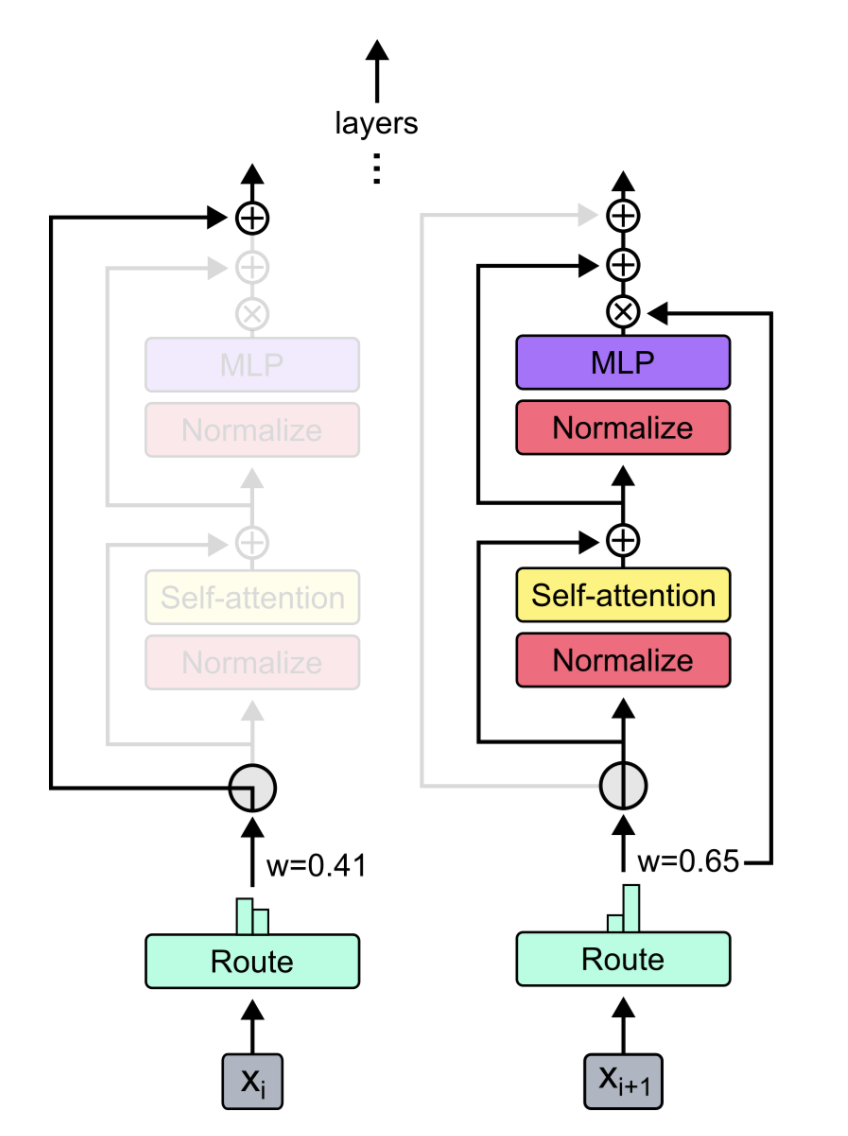
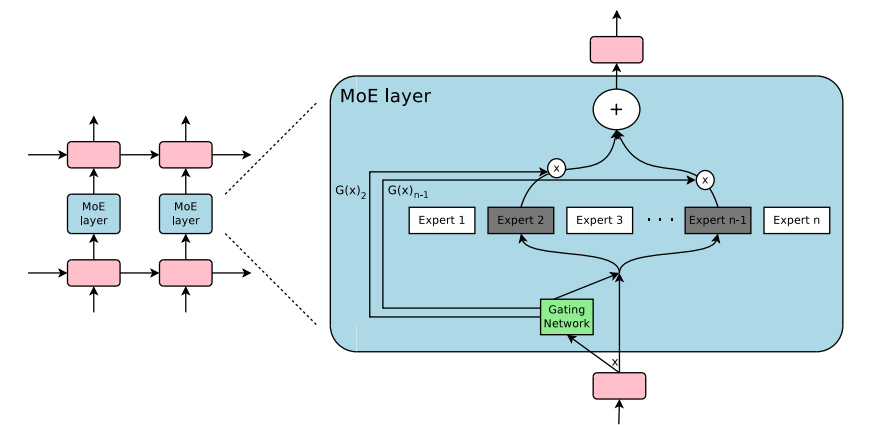 -
- 
Quellen:
Wenn Sie einfach pip3 install pytorch-mixtures verwenden, installieren Sie dieses Paket. Beachten Sie, dass torch und einops als Abhängigkeiten vorinstalliert werden müssen. Wenn Sie dieses Paket aus der Quelle erstellen möchten, führen Sie den folgenden Befehl aus:
git clone https://github.com/jaisidhsingh/pytorch-mixtures.git
cd pytorch-mixtures
pip3 install . pytorch-mixtures ist so konzipiert, dass sie zum Beispiel mühelos in Ihren vorhandenen Code für jedes neuronale Netz Ihrer Wahl integriert werden
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe_layer import MoELayer
import torch
import torch . nn as nn
# define some config
BATCH_SIZE = 16
SEQ_LEN = 128
DIM = 768
NUM_EXPERTS = 8
CAPACITY_FACTOR = 1.25
# first initialize the router
router = ExpertChoiceRouter ( dim = DIM , num_experts = NUM_EXPERTS )
# choose the experts you want: pytorch-mixtures just needs a list of `nn.Module` experts
# for e.g. our experts are just linear layers
experts = [ nn . Linear ( DIM , DIM ) for _ in range ( NUM_EXPERTS )]
# supply the router and experts to the MoELayer for modularity
moe = MoELayer (
num_experts = NUM_EXPERTS ,
router = router ,
experts = experts ,
capacity_factor = CAPACITY_FACTOR
)
# initialize some test input
x = torch . randn ( BATCH_SIZE , SEQ_LEN , DIM )
# pass through moe
moe_output , aux_loss , router_z_loss = moe ( x ) # shape: [BATCH_SIZE, SEQ_LEN, DIM] Sie können dies auch einfach in Ihren eigenen nn.Module -Klassen verwenden
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe import MoELayer
from pytorch_mixtures . utils import MHSA # multi-head self-attention layer provided for ease
import torch
import torch . nn as nn
class CustomMoEAttentionBlock ( nn . Module ):
def __init__ ( self , dim , num_heads , num_experts , capacity_factor , experts ):
super (). __init__ ()
self . attn = MHSA ( dim , num_heads )
router = ExpertChoiceRouter ( dim , num_experts )
self . moe = MoELayer ( dim , router , experts , capacity_factor )
self . norm1 = nn . LayerNorm ( dim )
self . norm2 = nn . LayerNorm ( dim )
def forward ( self , x ):
x = self . norm1 ( self . attn ( x ) + x )
moe_output , aux_loss , router_z_loss = self . moe ( x )
x = self . norm2 ( moe_output + x )
return x , aux_loss , router_z_loss
experts = [ nn . Linear ( 768 , 768 ) for _ in range ( 8 )]
my_block = CustomMoEAttentionBlock (
dim = 768 ,
num_heads = 8 ,
num_experts = 8 ,
capacity_factor = 1.25 ,
experts = experts
)
# some test input
x = torch . randn ( 16 , 128 , 768 )
output , aux_loss , router_z_loss = my_block ( x ) # output shape: [16, 128, 768] Dieses Paket bietet dem Benutzer, einen einfachen, aber zuverlässigen absl test für den MOE -Code auszuführen. Wenn alle Experten als das gleiche Modul initialisiert werden, sollte die Ausgabe des MoELayer dem Eingangspfehler gleich sein. Sowohl ExpertChoiceRouter als auch TopkRouter werden so getestet und erfolgreich in den Tests. Die Benutzer können diese Tests für sich ausführen, indem sie Folgendes ausführen:
from pytorch_mixtures import run_tests
run_tests ()Hinweis: Alle Tests bestehen korrekt. Wenn ein Test fehlschlägt, ist dies wahrscheinlich auf einen Kantenfall in den zufälligen Initialisierungen zurückzuführen. Versuchen Sie es erneut, und es wird vergehen.
Wenn Sie dieses Paket nützlich fanden, zitieren Sie es bitte in Ihrer Arbeit:
@misc { JaisidhSingh2024 ,
author = { Singh, Jaisidh } ,
title = { pytorch-mixtures } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/jaisidhsingh/pytorch-mixtures} } ,
}Dieses Paket wurde mit Hilfe des unten erwähnten Open-Source-Codes erstellt:


