pytorch mixtures
1.0.0
Un módulo plug-and-play para la mezcla de expertos y la mezcla de profundidad en Pytorch. ¡Su solución única para insertar capas MOE/mod en redes neuronales personalizadas sin esfuerzo!
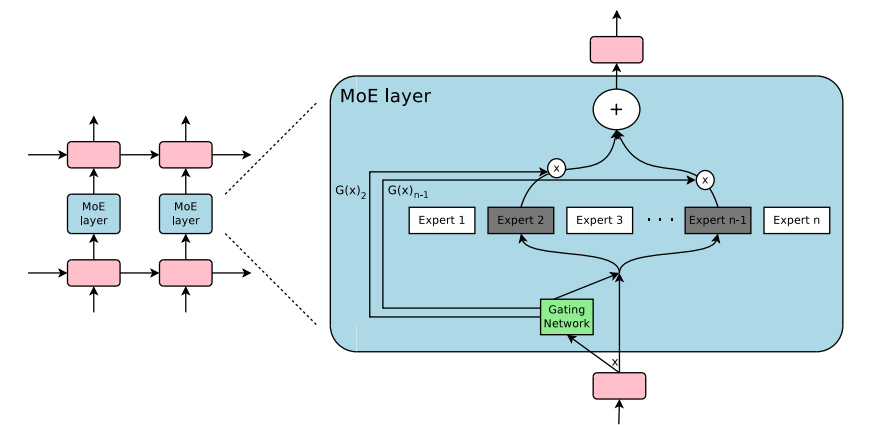 -
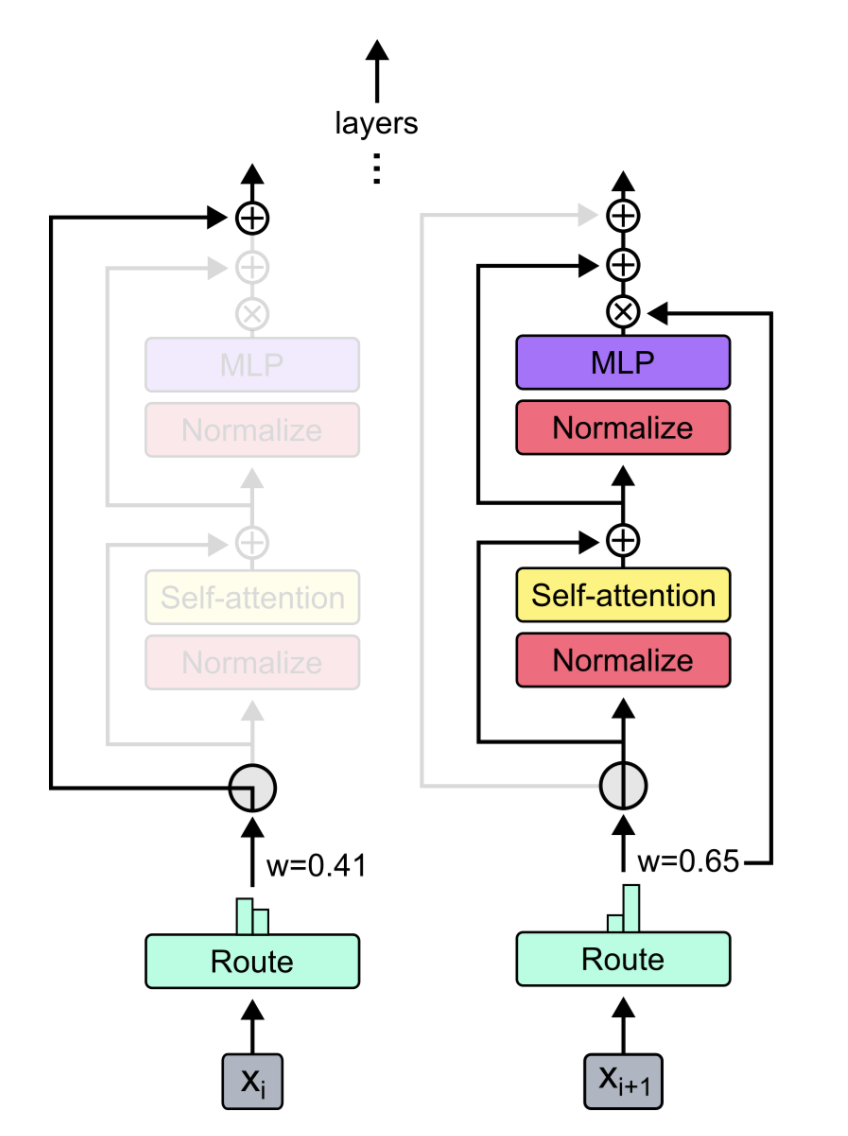
- 
Fuentes:
Simplemente usar pip3 install pytorch-mixtures instalará este paquete. Tenga en cuenta que esto requiere que torch y einops se estén preinstalados como dependencias. Si desea construir este paquete a partir de la fuente, ejecute el siguiente comando:
git clone https://github.com/jaisidhsingh/pytorch-mixtures.git
cd pytorch-mixtures
pip3 install . pytorch-mixtures está diseñado para integrarse sin esfuerzo en su código existente para cualquier red neuronal de su elección, por ejemplo
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe_layer import MoELayer
import torch
import torch . nn as nn
# define some config
BATCH_SIZE = 16
SEQ_LEN = 128
DIM = 768
NUM_EXPERTS = 8
CAPACITY_FACTOR = 1.25
# first initialize the router
router = ExpertChoiceRouter ( dim = DIM , num_experts = NUM_EXPERTS )
# choose the experts you want: pytorch-mixtures just needs a list of `nn.Module` experts
# for e.g. our experts are just linear layers
experts = [ nn . Linear ( DIM , DIM ) for _ in range ( NUM_EXPERTS )]
# supply the router and experts to the MoELayer for modularity
moe = MoELayer (
num_experts = NUM_EXPERTS ,
router = router ,
experts = experts ,
capacity_factor = CAPACITY_FACTOR
)
# initialize some test input
x = torch . randn ( BATCH_SIZE , SEQ_LEN , DIM )
# pass through moe
moe_output , aux_loss , router_z_loss = moe ( x ) # shape: [BATCH_SIZE, SEQ_LEN, DIM] También puede usar esto fácilmente dentro de sus propias clases nn.Module
from pytorch_mixtures . routing import ExpertChoiceRouter
from pytorch_mixtures . moe import MoELayer
from pytorch_mixtures . utils import MHSA # multi-head self-attention layer provided for ease
import torch
import torch . nn as nn
class CustomMoEAttentionBlock ( nn . Module ):
def __init__ ( self , dim , num_heads , num_experts , capacity_factor , experts ):
super (). __init__ ()
self . attn = MHSA ( dim , num_heads )
router = ExpertChoiceRouter ( dim , num_experts )
self . moe = MoELayer ( dim , router , experts , capacity_factor )
self . norm1 = nn . LayerNorm ( dim )
self . norm2 = nn . LayerNorm ( dim )
def forward ( self , x ):
x = self . norm1 ( self . attn ( x ) + x )
moe_output , aux_loss , router_z_loss = self . moe ( x )
x = self . norm2 ( moe_output + x )
return x , aux_loss , router_z_loss
experts = [ nn . Linear ( 768 , 768 ) for _ in range ( 8 )]
my_block = CustomMoEAttentionBlock (
dim = 768 ,
num_heads = 8 ,
num_experts = 8 ,
capacity_factor = 1.25 ,
experts = experts
)
# some test input
x = torch . randn ( 16 , 128 , 768 )
output , aux_loss , router_z_loss = my_block ( x ) # output shape: [16, 128, 768] Este paquete proporciona al usuario para ejecutar una absl test simple pero confiable para el código MOE. Si todos los expertos se inicializan como el mismo módulo, la salida de la MoELayer debe ser igual al tensor de entrada pasada a través de cualquier experto. Tanto ExpertChoiceRouter como TopkRouter se prueban así, y tienen éxito en las pruebas. Los usuarios pueden ejecutar estas pruebas por sí mismos ejecutando lo siguiente:
from pytorch_mixtures import run_tests
run_tests ()Nota: Todas las pruebas pasan correctamente. Si una prueba falla, es probable que se deba a un caso de borde en las inicializaciones aleatorias. Inténtalo de nuevo y pasará.
Si encontró este paquete útil, cíquelo en su trabajo:
@misc { JaisidhSingh2024 ,
author = { Singh, Jaisidh } ,
title = { pytorch-mixtures } ,
year = { 2024 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/jaisidhsingh/pytorch-mixtures} } ,
}Este paquete fue construido con la ayuda del código de código abierto que se menciona a continuación:


